This is based on the inaugural longbets.org bet between Ray Kurzweil (YES) and Mitch Kapor (NO). It's a much more stringent Turing test than just "person on the street chats informally with a bot and can't tell it from a human". In fact, it's carefully constructed to be a proxy for AGI. Experts who know all the bot's weaknesses get to grill it for hours. Kurzweil and Kapor agree that LLMs as of 2023 don't and can't pass this Turing test.
Personally I think Kapor will win and Kurzweil will lose -- that a computer will not pass this version of the Turing test this decade.
((Bayesian) Update: But I admit the probability has jumped up recently! I created this Manifold market almost a year before ChatGPT launched.)
Resolution Criteria
However Kurzweil and Kapor and Longbets agree to resolve the wager is how this market resolves.
Related Markets
Metaculus's version and Manifold mirror of Metaculus's version
Manifold numerical market for a full probability distribution on the year AGI appears
(Also I had a real-money version on biatob.com for anyone confident that Kurzweil's side has a good chance, but the link keeps breaking)
 1,000
1,000People are also trading
Kalshi resolved their bet early (for some reason at current price rather than cost, maybe to represent people's opinion about the meaning) because the full rules said Kapor while the short rules said Kurzweil.
Fine for me that they did that rather than cost, since that at least gave me positive profit.
But everyone betting in that market knew it was about Kurzweil.
@DavidBolin You mean they accidentally contradicted themselves in the market description so they effectively did a resolve-to-PROB at the market probability? Sounds like a dangerous precedent!
I just looked at the original Longbets terms, and I don't agree that it has the judges "knowing all of the bot's weaknesses". The rules there don't specify either way on this point, but I see two reasons to think otherwise:
The spirit of the Test - If the bot fails only because it has known, specific weaknesses that otherwise wouldn't show up in a two-hour interview, then that doesn't contradict its "ability to pose as a human".
The rules specify that Kurzweil may have the Test held when he chooses, and provide the Computer to be tested. This would allow him to have the test done on a new model, whose patterns are not yet publicly known.
@AhronMaline This sounds right. I think I meant to say that the judges are AI experts who know the weaknesses of chatbots in general.
@AhronMaline "The spirit of the test" is that there isn't any spirit.
Turing himself talks about how hard it is to pass this test precisely because it requires a lot more than intelligence.
@DavidBolin the test is about the AI's ability to perfectly imitate a human, as judged by other humans. If it can fool any judge who lacks specific pieces of info about that AI model, that means it has all the abilities required.
@mathvc
Yep. Kind of like how superhuman go was achieved almost a a decade ago. But if you train an adversarial model specifically against Go-playing AI, then humans can still beat it.
This may be a general feature of high dimensional spaces: if AI has to commit to a strategy in advance and humans are allowed to train specifically against that strategy humans can always win.
@Bayesian it's part of his complicated "reverse jim" strategy. You can tell it isn't a real bet because he didn't put in limit orders
@Bayesian They only filled a few shares of my order before letting the price drift in the opposite direction for months.
@Uaaar33 Good question. The above Metaculus market sounds like it's describing something similar to the Kurzweil/Kapor wager but doesn't seem to mention it explicitly.
@DavidBolin so the price is way higher on kalshi than here right? so wouldn't someone wanna buy YES here before kalshi? ig unless the benefit is realmoney, but the returns are almost certainly worse than eg s&p 500 for those few years
@Bayesian Maybe not you guys but some people already filled some of those orders and there's plenty of time.
@VerySeriousPoster I think the jump was more due to people being reminded how much higher Metaculus (~88%) and Kalshi (~72%) were than Manifold (~38%). There have also been various discussions of issues and subjectivity in the Longbets resolution itself, including arguments that the substantial randomness of the result will push the result towards 50% or towards ~100%. I think Claude 3 would come after that.
However, for many people, Claude 3 was a negative update for AI capabilities because people expected the GPT-4 bar to be significantly cleared already and Claude 3 is merely a little below, at, or a little above—depending on who you ask. I think the combined speed and performance of Claude 3 Haiku was more clearly a positive update, though perhaps on a somewhat different axis and maybe only relative to February 2024 (rather than, say, March 2023).


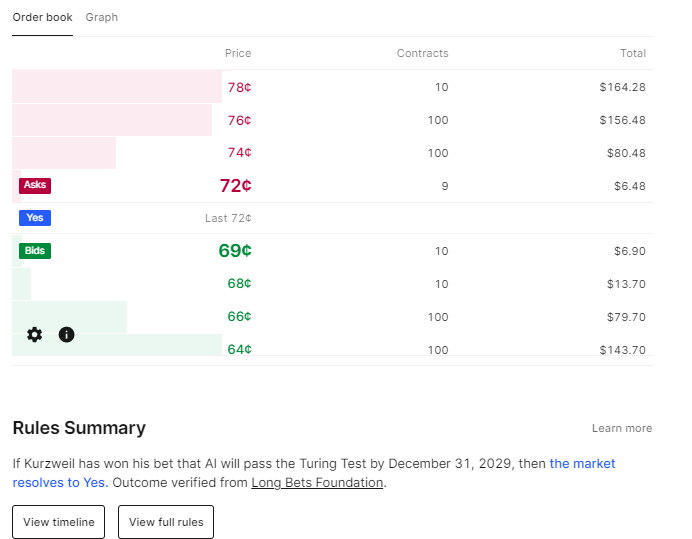
@Bayesian I am also surprised to see real money so high. I even bet against it a bit myself on Kalshi! But people keep buying it back up! I'm not an expert, and AI keeps outperforming my expectation.
So I'm going to take the outside view here. If anyone disagrees, they should go bet against it with real money!
@Bayesian Metaculus actually predicts a similar Turing test can be passed by 2026! Four years to spare!

@Bayesian Well I bought a bit of no when the kalshi market went live and was even higher than it is now. But the price remained high, and after reading the metaculus comments now I think this market is the one that's more mispriced.
If Metaculus dropped, then I'd probably sell here. But I think they'd be good at this kind of thing since they don't have to care about the time value of money.
@Joshua yeah, makes sense. on a question like this idk to what extent kalshi is gonna be well priced. didn't know they did markets this far out tbh
@Joshua Guess it's time for me to sign up there, if I can do it legally or otherwise without too much risk.
$25,000 to $75,000 in 5.5 years is not too bad a deal.
@DavidBolin I'm an ASI ~never kinda dude but do you really think transparent text chat isn't happening within the decade?
@Adam Passing an adversarial Turing test, even with pure chat, IS superintelligence.
Right now, you can pretty much recognize an LLM by a single paragraph. Even if you disagree with that statement about superintelligence, there is no way anything is passing an adversarial test like that without intensive training and finetuning on the specific task of trying to pass the test.
No one is going to do that because it's too expensive and goes against other things they care about, like not having LLMs be outrageous liars. This is not happening.
@DavidBolin on one hand you say that passing the test is superintelligence, then you argue no one will bother to do the work. which one is it? even if we’re being super charitable anyway, it seem pretty obvious that passing the test or winning the llm arena unlocks a ton of funding prospects at attractive valuations
@beaver1 If you want a precise answer, it is superintelligence.
I made the other point as in "even if you think it does not take superintelligence," it is still true that no one would do the work.
In my opinion (1) no one will do the work, (2) if they did, they would fail. (3) If they did not fail, they would get superintelligence.