As with my other related questions, by default will judge based on the leaderboard here, based on Elo: https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard

Chatbot Arena Leaderboard - a Hugging Face Space by lmsys
Discover amazing ML apps made by the community
If Google deplolys a new model in 2024 that might or might not qualify, but it is not yet ranked on the leaderboard at year's end due to time required for evaluation, I will hold off on resolving until that has happened until a maximum of February 1, 2025.
If Google releases a model that the public, or least those who have signed up for its early testing programs, cannot access by the deadline, that does not count - I will use my ability to access it absent any special treatment as a proxy here, or if I get special treatment I will ask others.
As with other questions, I reserve the right to correct what I see as an egregious error in either direction, either by twitter poll or outright fiat, including if the model is effectively available but does not appear on the leaderboard for logistical reasons.
(This is the EOY '24 version of the market here: https://manifold.markets/ZviMowshowitz/will-google-have-the-best-llm-by-eo)
Clarification (in response to Daniel): This resolves on the spot if Google has the best model - it's 'by EOY' not 'at EOY.'
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ21,920 | |
| 2 | Ṁ844 | |
| 3 | Ṁ791 | |
| 4 | Ṁ548 | |
| 5 | Ṁ476 |
People are also trading
I saw the update on the public leaderboard. I was using a cached web page, sorry my bad.
Old comment: I mean, you could at least have waited until the score appeared on the public leaderboard. It has happened multiple times that lmsys announces a specific placement for a model, and when the leaderboard updates, the score is above or below what was announced.
I will give a nad rating based on this
@PlainBG that's obviously not true when speaking about events (e.g. will I win a tournament by EOY). I think Zvi's wording was technically correct, but I also found it confusing.
Hmm, thinking about it some more it does seem like this wording would usually imply "at EOY" when talking about persistent states. For instance, you could say "will I be homeless by EOY" whether or not you were currently homeless, and it would refer to your state at EOY. If you wanted what Zvi's going for, you would say something like "will I experience homelessness by EOY" to make it an event rather than a state.
Well that's fair given the existence of "Clarification (in response to Daniel): This resolves on the spot if Google has the best model - it's 'by EOY' not 'at EOY.'"
But I personally misinterpreted this market because it seemed clear to me the opposite was meant from the first few lines.
Both GPT4o and Claude share my interpretation of question text.
https://chatgpt.com/share/006f377a-7fc3-4968-acb2-072222e995dd
@ZviMowshowitz resolves YES
I'm in the UK, using a free (not paid) google account. I had signed up to various Google AI beta testing programs in general.
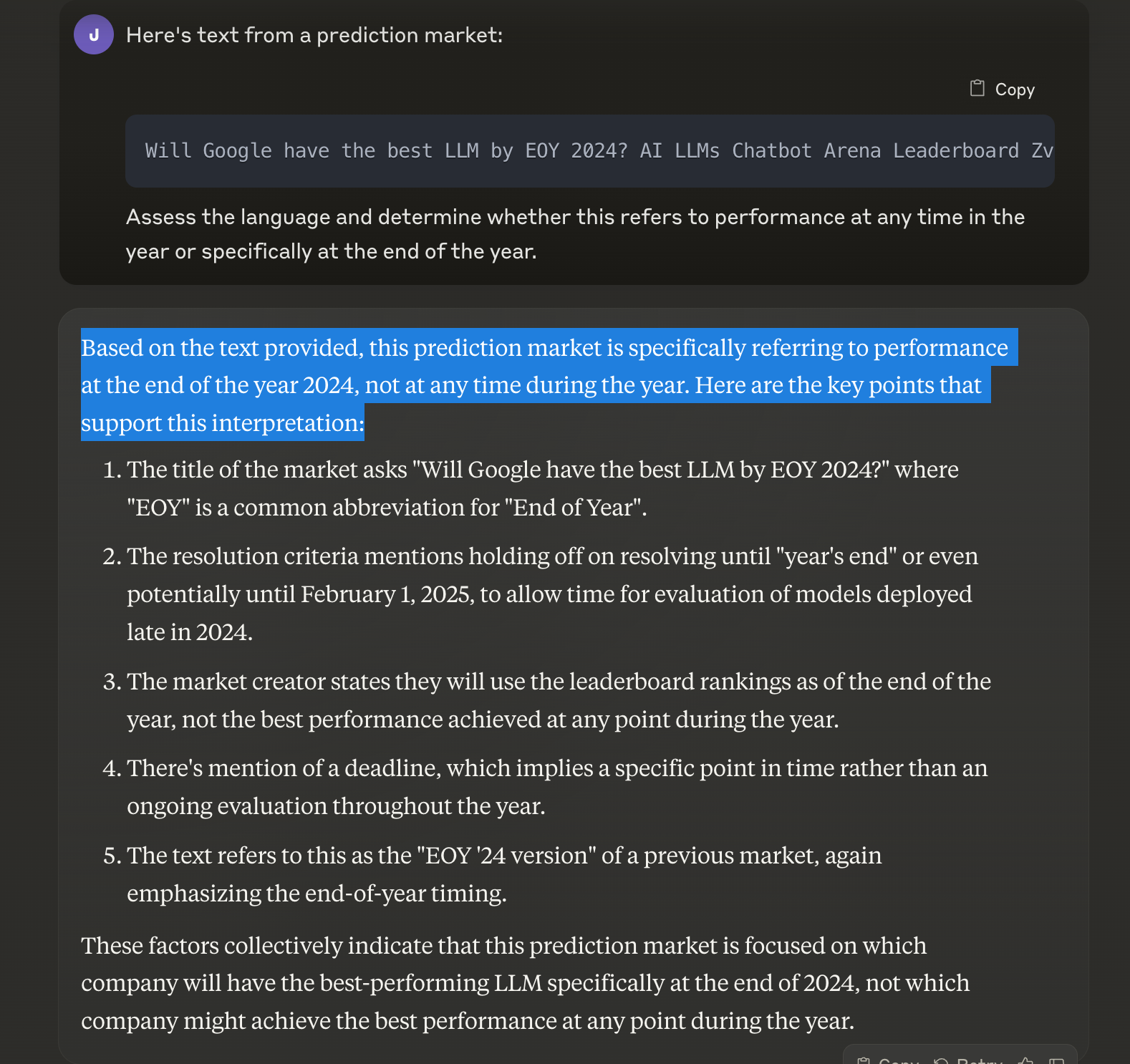
I can access gemini-1.5-pro-exp-0801 at https://aistudio.google.com/ (my screenshot)
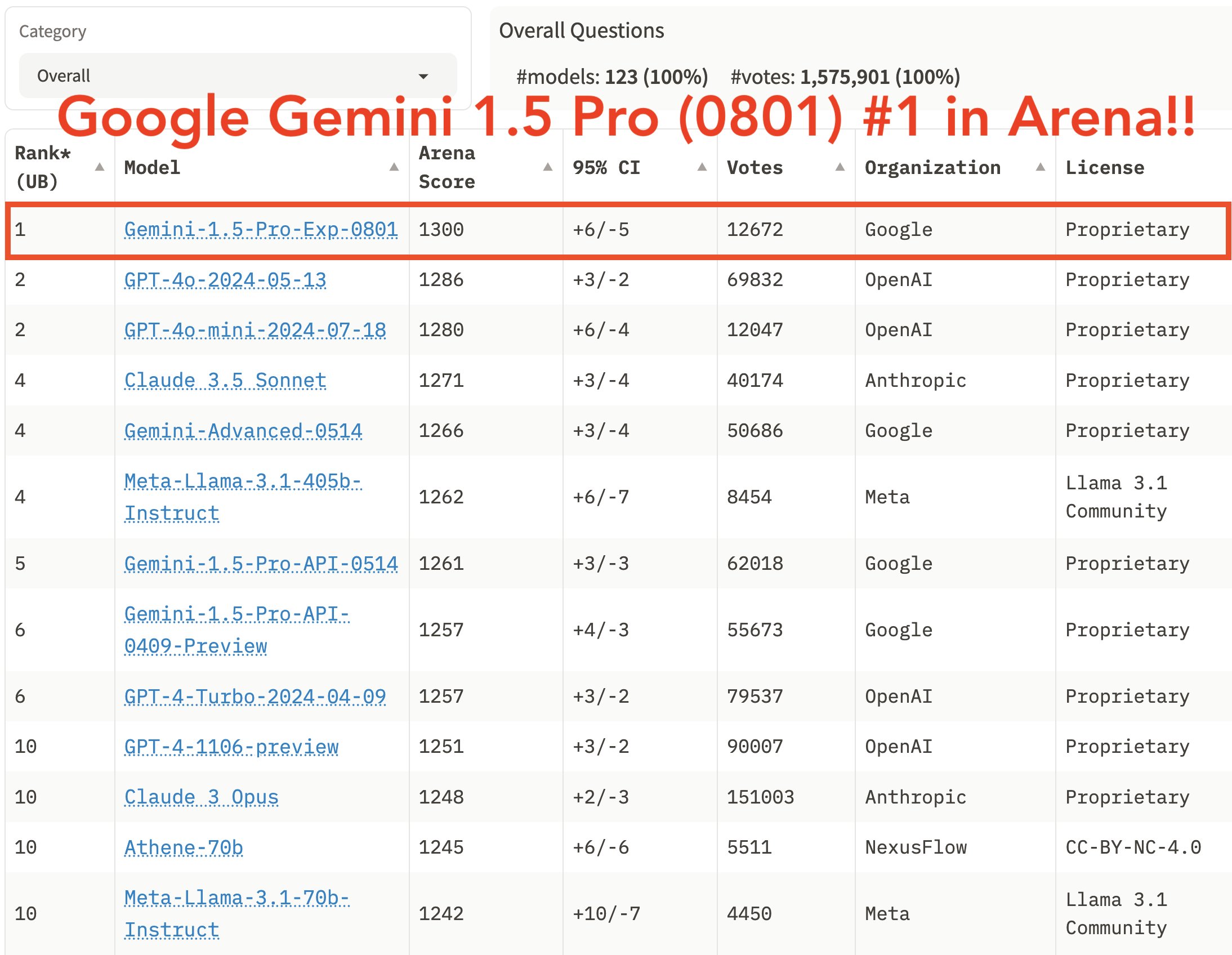
LMSYS's leaderboard (https://chat.lmsys.org/?leaderboard) places gemini-1.5-pro-exp-0801 at 1st place, not tied with GPT-4o-2024-05-13. (screenshot from LMSYS's tweet in the parent comment)
@ChrisPrichard I have put a limit order of NO at 33% for 500 mana if you want to buy more YES. we can also do more if you want
@ZviMowshowitz it seems like many people are now realizing the LMSYS leaderboard allows models with live internet access and models that don't, which seems to be a good explanation for how Bard surprisingly jumped to the #2 spot. How do imbalances like this factor into your view of the "best LLM"?
@Jacy I believe if the leaderboard out Bard with Gemini Pro in first over GPT-4 due to that I would overrule it, but not if it was Ultimate. But not sure what the exact principle is.
Clarification: What if Google's LLM were to have some cognitive architecture (Tree of thought) added on top of it, running behind the scenes?
It seems possible that Google's LLM itself may be similiarly capable as GPT-4, but due to the added cognitive architecture it will perform better than GPT-4 on the benchmarks.
How would this question resolve if this was the case?
@4168760 Note that the benchmark is human judgment and the humans are allowed to use prompt engineering, so I do not expect this to come up. If it does, then I would correct if it was an egregious error, meaning something along the lines of 'oh come on yes I know Gemini has slightly higher Elo here but GPT-4 is still obviously better than Gemini, all you have to do is use a reasonable system instruction like [some basic ToT script] and it blows Gemini away, whereas no similar prompt lets Gemini improve.' But it would have to be pretty egregious and obvious.
@dreev Clarification: As per question original wording, this can resolve early, and will if the answer is already YES. It's by EOY 2024, not at EOY.
@ZviMowshowitz how long does it have to hold the top spot on the leaderboard? a week? a day? an hour?