
Short-term AI 3.3: By June 2024 will SOTA on HumanEval be >= 99%?
10
Ṁ190Ṁ685resolved Jun 5
Resolved
NO1H
6H
1D
1W
1M
ALL
This question is managed and resolved by Manifold.
Market context
Get  1,000 to start trading!
1,000 to start trading!
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ40 | |
| 2 | Ṁ14 | |
| 3 | Ṁ9 | |
| 4 | Ṁ7 | |
| 5 | Ṁ5 |
People are also trading
Will any AI model score above 90% on the ARC-AGI-2 benchmark before April 2026?
11% chance
What will be true of the SOTA AI on the FrontierMath benchmark, before 2027?
Will AI solve 100% of solvable MTurk problems by July 2028?
32% chance
Any SOTA AI model uses human-understandable thinking medium at the end of 2028?
71% chance
In what year will AI achieve a score of 95% or higher on the SWE-bench Verified benchmark?
2/29/28
In what year will AI achieve a score of 95% or higher on the PhysBench leaderboard?
2036
What will be true of the SOTA AI on the FrontierMath benchmark, before 2028?
Will humans create a SOTA AI model without Multi-Layer Perceptrons by 2029?
28% chance
Will AI pass the Longbets version of the Turing test by the end of 2029?
50% chance
[Carlini questions] SOTA AI scores better than X% of other participants in competitive programming contest by 2030
95.2
Sort by:
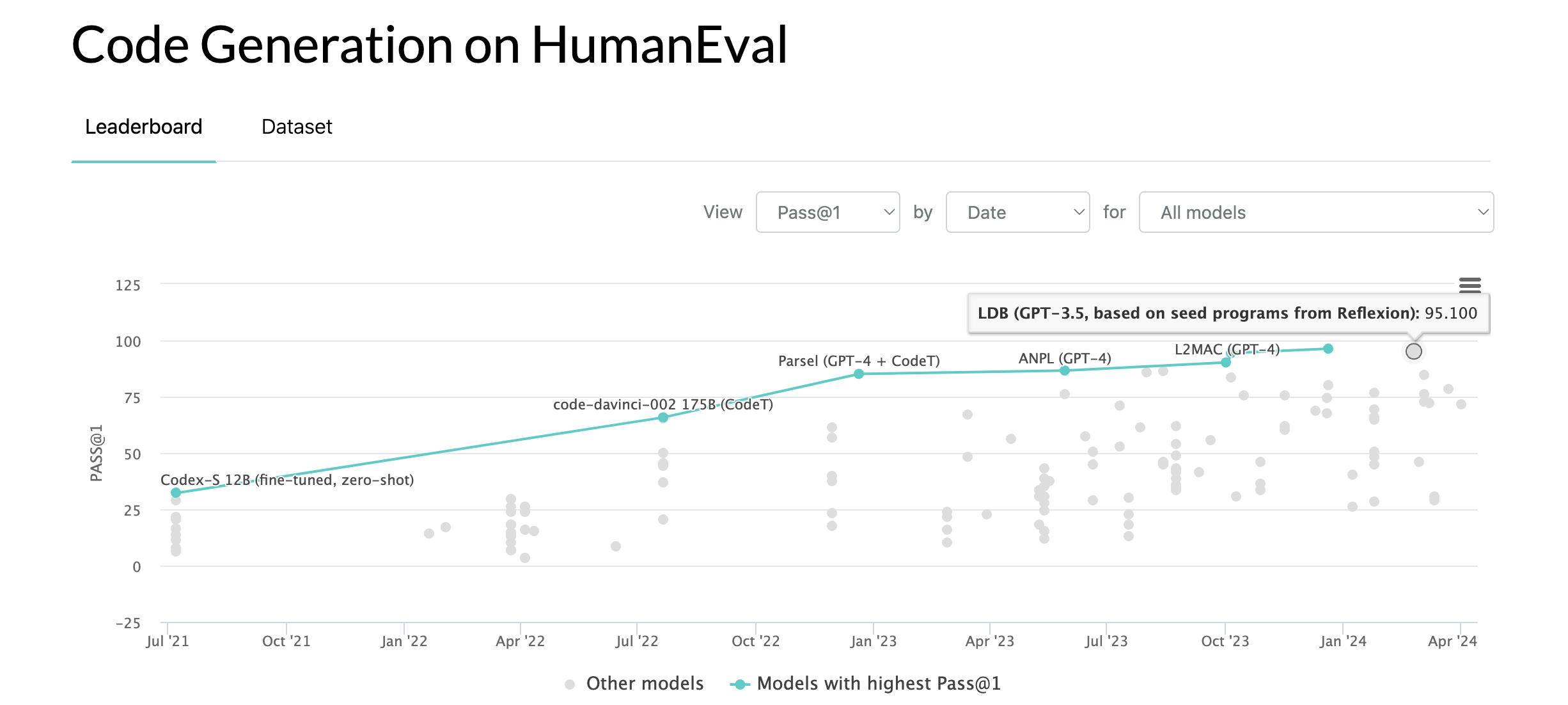
@PlasmaBallin I'm just following the links in the description. Which should be straightforward (can post pics) but it's possible the linked source could be missing models? (i see one comment noting another). but maybe it's easiest just to go on the linked source
@thooton I think it's quite plausible that the test set will end up in the training set in some hard to detect way. I will exclude models for this if it's known their training set is poisoned (I assume Papers With Code would exclude them as well), but for most large language models the pre-training data is not public.
People are also trading
Related questions
Will any AI model score above 90% on the ARC-AGI-2 benchmark before April 2026?
11% chance
What will be true of the SOTA AI on the FrontierMath benchmark, before 2027?
Will AI solve 100% of solvable MTurk problems by July 2028?
32% chance
Any SOTA AI model uses human-understandable thinking medium at the end of 2028?
71% chance
In what year will AI achieve a score of 95% or higher on the SWE-bench Verified benchmark?
2/29/28
In what year will AI achieve a score of 95% or higher on the PhysBench leaderboard?
2036
What will be true of the SOTA AI on the FrontierMath benchmark, before 2028?
Will humans create a SOTA AI model without Multi-Layer Perceptrons by 2029?
28% chance
Will AI pass the Longbets version of the Turing test by the end of 2029?
50% chance
[Carlini questions] SOTA AI scores better than X% of other participants in competitive programming contest by 2030
95.2