Short-term AI 3.4: By June 2024 will SOTA on APPS be >= 25%?
8
Ṁ130Ṁ1.3kresolved Jun 8
Resolved
NO1H
6H
1D
1W
1M
ALL
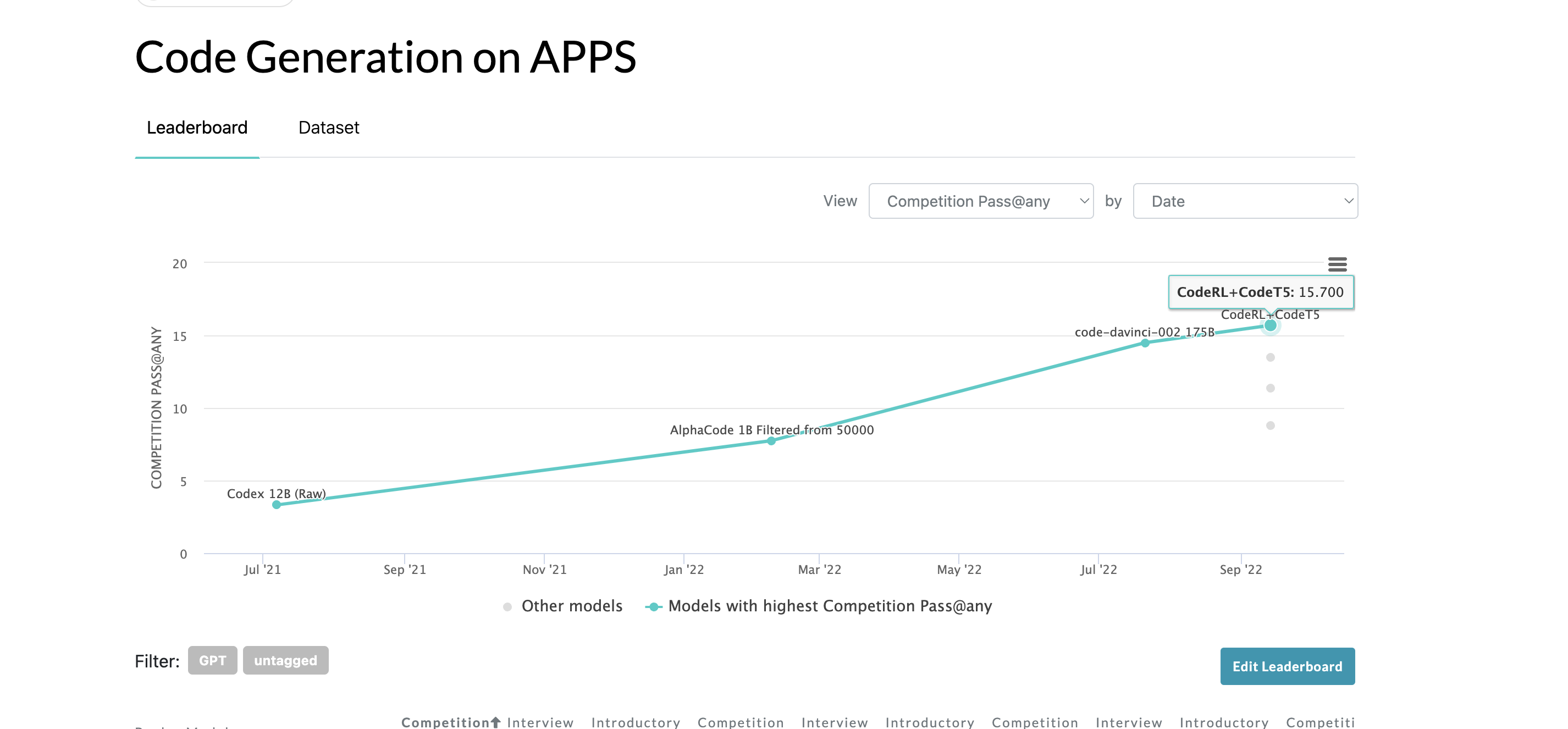
APPS is the more challenging code benchmark (compared to HumanEval). SOTA at market creation is 15.7 by CodeRL. I will use Competition Pass@any.
Notable that the current SOTA is using a very old LLM as the base model, and yet it still beats davinci-002.
Other short-term AI 3 markets:
This question is managed and resolved by Manifold.
Market context
Get  1,000 to start trading!
1,000 to start trading!
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ171 | |
| 2 | Ṁ31 | |
| 3 | Ṁ21 | |
| 4 | Ṁ11 | |
| 5 | Ṁ5 |
Sort by:
@PlasmaBallin according to the linked source this is NO (not sure if there's any reason to include other models)
People are also trading
Related questions
What will be true of the SOTA AI on the FrontierMath benchmark, before 2027?
What will be true of the SOTA AI on the FrontierMath benchmark, before 2028?
BIG-bench accuracy 75% #4: Will SOTA for a single model on BIG-bench pass 75% by the start of 2027?
86% chance
BIG-bench accuracy 75% #5: Will SOTA for a single model on BIG-bench pass 75% by the start of 2028?
87% chance
Any SOTA AI model uses human-understandable thinking medium at the end of 2028?
71% chance
SOTA AI at EOY 2026 a reasoning model?
94% chance
MMLU 99% #4: Will SOTA for MMLU (average) pass 99% by the start of 2027?
8% chance
[Carlini questions] SOTA AI scores better than X% of other participants in competitive programming contest by 2027
91.5
[Carlini questions] SOTA AI scores better than X% of other participants in competitive programming contest by 2030
95.2
MMLU 99% #5: Will SOTA for MMLU (average) pass 99% by the start of 2028?
44% chance