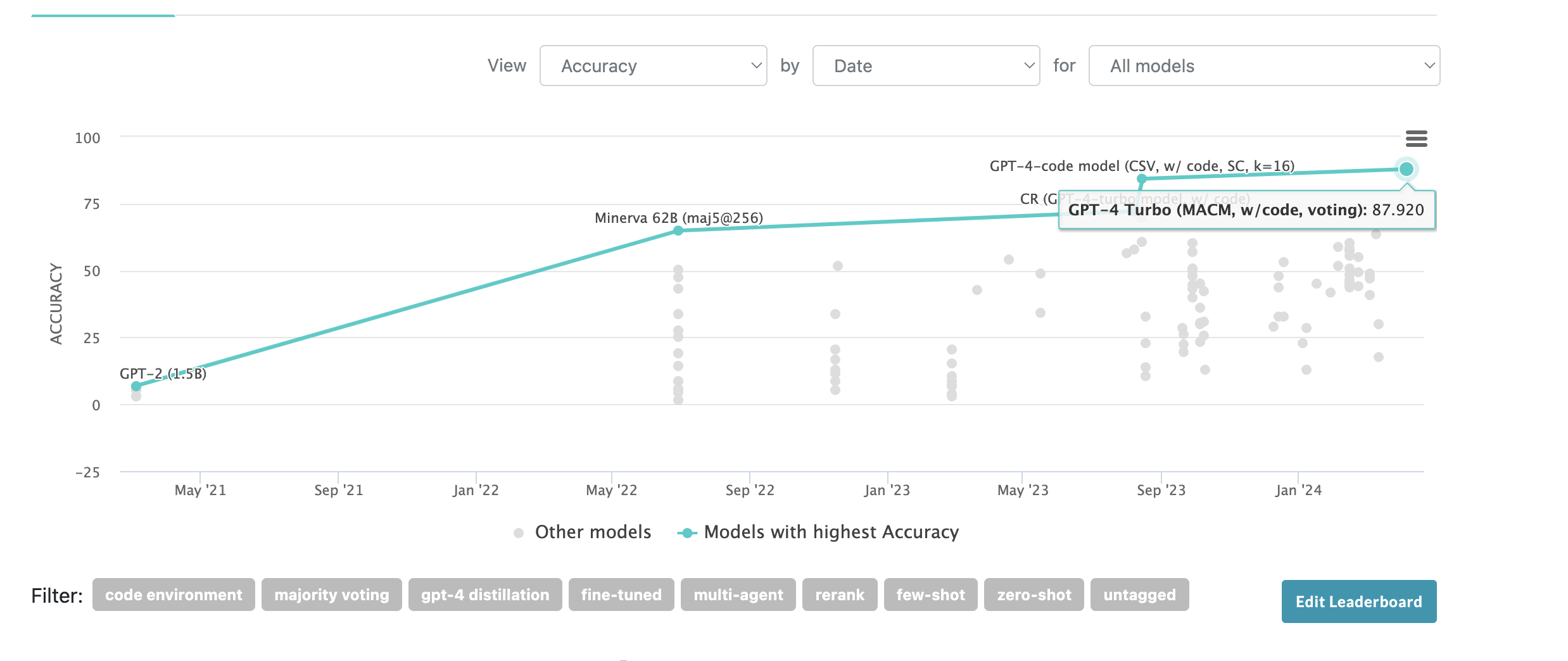
Benchmark. At market creation SOTA is 84.3% by GPT-4 Code Interpreter.
Other short-term AI 3 markets:
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ98 | |
| 2 | Ṁ49 | |
| 3 | Ṁ43 | |
| 4 | Ṁ33 | |
| 5 | Ṁ8 |
People are also trading
@mods if anyone knows more about this than I do please take a look as the resolution seems contentious, if not I can later. Thanks.
Object level - I don't really care if this market resolves the other way.
Meta level - I don't think mods should be in the business of arbitrating ambiguity in resolution criteria. Sure, it was ambiguous if I would use the literal value in the clearly linked webpage, but I don't think "use the literal value" is totally outside the realm of reasonable interpretations and this market is clearly resolved correctly according to that criterion.
@VincentLuczkow why did you resolve no? your linked benchmark is a thin wrapper around reported results in papers (paperswithcode) which is known to not always be particularly up to date. And it was all but shouted from the heavens that Gemini 1.5 got >90% on MATH (paper released in May) with a fine-tuned model and rm@256 sampling procedure, which you didn't stipulate was invalid.
@hyperion In general I resolve to whatever is actually on papers with code so that I don't have to get into arguments litigating what counts or doesn't count (tbc I agree that Gemini 1.5 counts, but resolution criteria are resolution criteria). On the other hand the market clearly didn't take that into account as we got closer to the deadline, so probably most people didn't realize I would resolve that way. In the next round I will be clearer about this, and I apologize for not being clearer in this round.
Well, @VincentLuczkow resolving based on papers with code alone is obviously dumb when there exist published reports from the biggest labs in the world getting hundreds of thousands of Twitter views, showing benchmark scores that plainly satisfy the criteria for a market. Your resolution criteria just says "benchmark" and links to one of many trackers of the actual benchmark (MATH), it doesn't make clear that you actually planned to resolve based on that particular tracker.
I think this market is clearly misresolved, and it should be N/A at best. I will object to the admins, I won't be trading on your markets again, and I will withdraw my mana from any of your active markets, and will recommend to others that they do the same.
@PlasmaBallin this is the source linked in the description. which doesn't show any models >=90%. below, there's a comment linking to a tweet with a model that claims to be >90%? no idea if that should count given that it isn't on the source (and the blue highlighted numbe rmight mean that it's using some speical allowance that doesn't count for the leaderboard?