 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ774 | |
| 2 | Ṁ616 | |
| 3 | Ṁ383 | |
| 4 | Ṁ335 | |
| 5 | Ṁ302 |
People are also trading
Postive(+)
GPT5 - Hallucination rate is down ~80% across the board
GPT-5 dominates the Text Arena, ranking #1 in every major category: Hard Prompts,Coding ,Math,Long Queries
The model will do well.
My prediction is 73% +or- 2% ( Much better than i thought). My end of year optimistic estimate on simple bench was 74% just last month.
I think worse case the model does 68-69% and my best case is around 78%
we will likely have an answer to this market within a week.
@Mad2live That test was done on the 10 public questions, not the private dataset.
Do we have any info on GPT 5's knowledge cutoff date? Could it possibly have the public questions in its training data?
@TiagoChamba That is what I’m thinking, plus I think i remember another modeling getting 80% on that public version and failing to break 63%
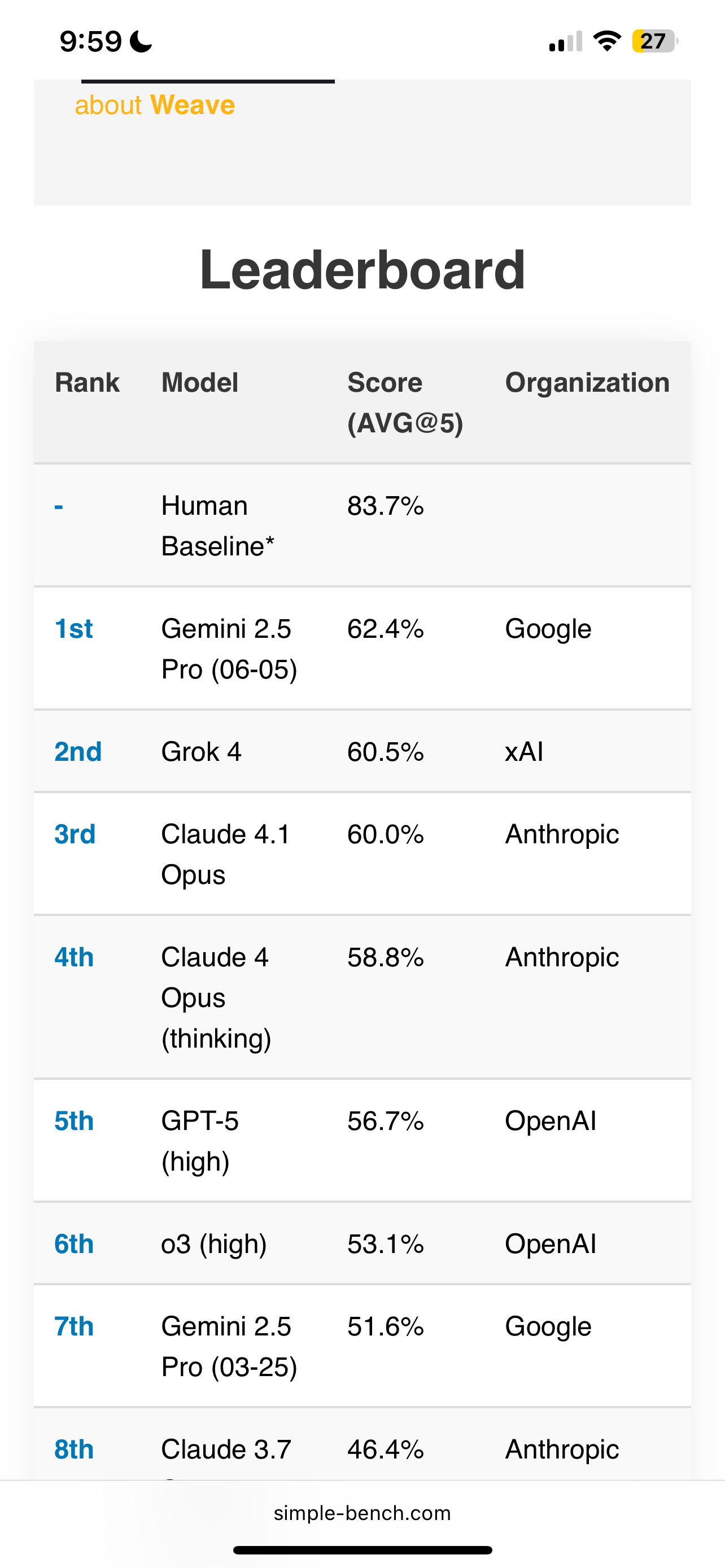
The human baseline is now 83.7%. Unfortunate that the old baseline is the name but I will resolve to true if any model exceeds the human baseline published on https://simple-bench.com.
Is it true that this benchmark can be anything, and can be changed at any point? There are no hashes, no large sample of problems, no error bars, no evaluation code, no specifics on what a model can or cannot use... How do we know what a true performance is, except what the author says?
Description of the benchmark here: https://simple-bench.com/about.html
I have made some irrational bets to subsidize the market - as I cannot be bothered to figure out the correct way to do this.