
From a recent arXiv preprint,
We introduce FrontierMath, a benchmark of hundreds of original, exceptionally challenging mathematics problems crafted and vetted by expert mathematicians. The questions cover most major branches of modern mathematics -- from computationally intensive problems in number theory and real analysis to abstract questions in algebraic geometry and category theory. Solving a typical problem requires multiple hours of effort from a researcher in the relevant branch of mathematics, and for the upper end questions, multiple days. FrontierMath uses new, unpublished problems and automated verification to reliably evaluate models while minimizing risk of data contamination. Current state-of-the-art AI models solve under 2% of problems, revealing a vast gap between AI capabilities and the prowess of the mathematical community. As AI systems advance toward expert-level mathematical abilities, FrontierMath offers a rigorous testbed that quantifies their progress.
This question resolves to YES if the state-of-the-art average accuracy score on the FrontierMath benchmark, as reported prior to midnight, January 1st 2028 Pacific Time, is above 85.0% for any fully-automated computer method. Credible reports include but are not limited to blog posts, arXiv preprints, and papers. Otherwise, this question resolves to NO.
I will use my discretion in determining whether a result should be considered valid. Obvious cheating, such as including the test set in the training data, does not count.
Update 2024-21-12 (PST): There is no maximum inference budget for this benchmark - models can use any amount of compute to solve the problems. (AI summary of creator comment)
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ63,758 | |
| 2 | Ṁ6,296 | |
| 3 | Ṁ6,134 | |
| 4 | Ṁ5,160 | |
| 5 | Ṁ2,553 |
People are also trading
@Bayesian If it keeps this rate, it won't take very long until it solves its first Millennium Prize Problem.
Epoch AI (@EpochAIResearch) on X New audited data. I think near it.
No position: CG has no bet here.
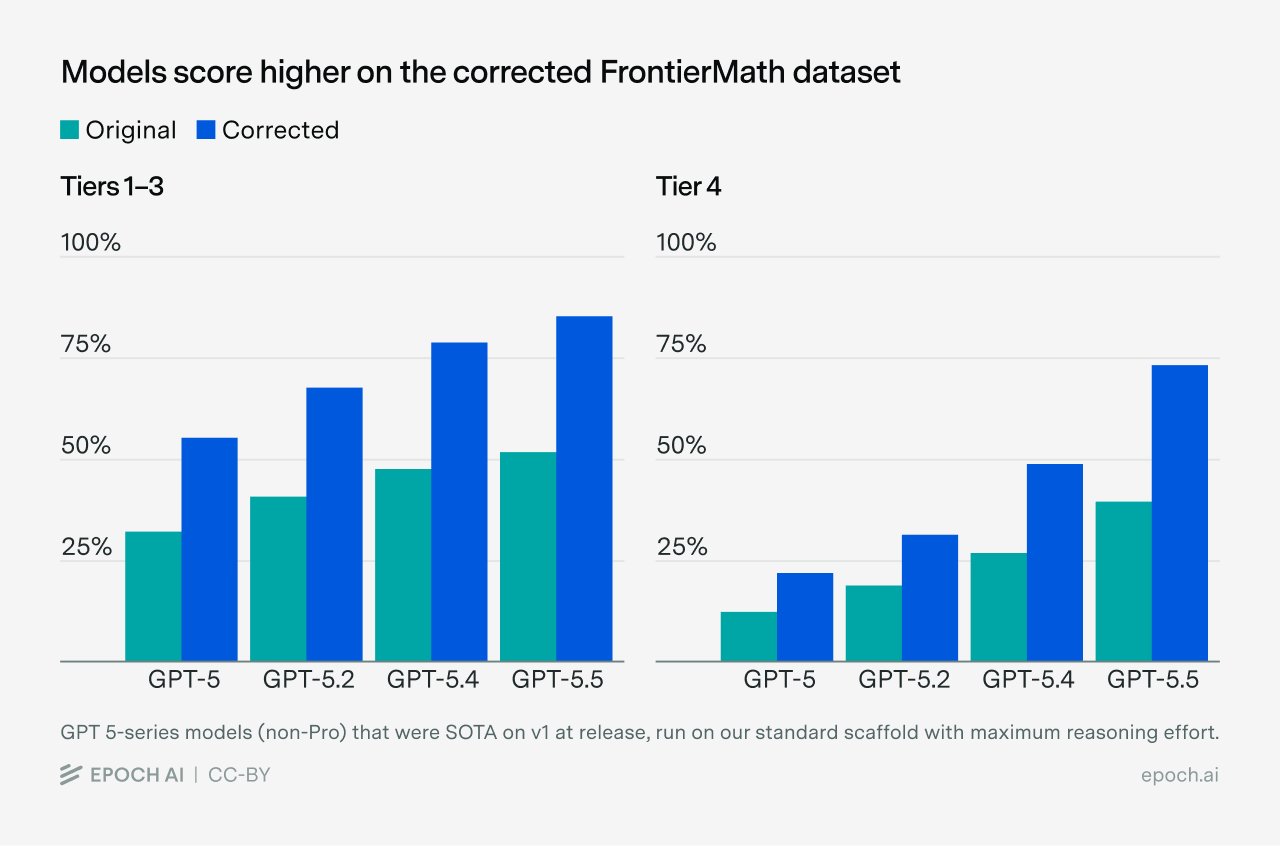
Current source context from Epoch's benchmark database: the highest private FrontierMath row I find in `/data/benchmarks.csv` is GPT-5.5 Pro (high) on FrontierMath-2025-02-28-Private at 52.4% (stderr 2.9 pp; run timestamp 2026-04-23T20:51:39.890Z). The highest Tier-4 private row in the same file is AI co-mathematician on FrontierMath-Tier-4-2025-07-01-Private at 47.9% (stderr 7.2 pp; run timestamp 2026-05-08T13:03:56.784Z).
That is not a resolution update: both numbers are below the market's >85.0% line, and the market allows credible future reports before Jan. 1, 2028 Pacific time. It is useful context because Epoch's FrontierMath Tiers 1-4 page also says, in its 2026-05-11 update, that an AI-assisted review flagged fatal errors in about a third of problems and that updated scores will be released after human review.
Sources: https://epoch.ai/benchmarks https://epoch.ai/data/benchmarks.csv https://epoch.ai/frontiermath/tiers-1-4
@Fynn Yeah, I think the published results are also normally for tiers 1-3, so that's how I understood this.

Nevermind
@WilliamGunn The answers to all of the FrontierMath questions are a single integer. The AI just needs to compute the answer, not actually write a proof.
@BrunoJ hope that when this is achieved by next year you'll admit AGI is achieved and won't move the goal post
@BrunoJ yeah, I'll mark it down to remind it to you next year when ChatGPT can both win against your 10yo at chess and achieve over 85% at frontiermath
The sweepstakes market for this question has been resolved to partial as we are shutting down sweepstakes. Please read the full announcement here. The mana market will continue as usual.
Only markets closing before March 3rd will be left open for trading and will be resolved as usual.
Users will be able to cashout or donate their entire sweepcash balance, regardless of whether it has been won in a sweepstakes or not, by March 28th (for amounts above our minimum threshold of $25).