
The best performance by an AI system on FrontierMath as of December 31st 2026.

Which AI systems count?
Any AI system counts if it operates within realistic deployment constraints and doesn't have unfair advantages over human baseliners.
Tool assistance, scaffolding, and any other inference-time elicitation techniques are permitted as long as:
There is no systematic unfair advantage over the humans described in the Human Performance section (e.g. AI systems are allowed to have multiple outputs autograded while humans aren't, or AI systems have access to the internet when humans don't).
Having the AI system complete the task does not use more compute than could be purchased with the wages needed to pay a human to complete the same task to the same level
The PASS@k elicitation technique (which automatically grades and chooses the best out of k outputs from a model) is a common example that we do not accept on this benchmark because mathematicians are generally evaluated on their ability to generate a single correct answer, not multiple answers to be automatically graded. So PASS@k would consititute an unfair advantage.
If there is evidence of training contamination leading to substantially increased performance, scores will be accordingly adjusted or disqualified.
(Much of the resolution is modified from AI Digest's excellent
/Manifold/what-will-be-the-best-performance-o-A58Ld8LZZL )
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ138,162 | |
| 2 | Ṁ14,000 | |
| 3 | Ṁ1,114 | |
| 4 | Ṁ666 | |
| 5 | Ṁ315 |
People are also trading
@mathvc I'll at least give it some hours and possible a few days to make sure it's best to resolve YES now or when it releases or whatever. I'm not sure yet tbc but I think it would be weird to resolve YES in 5 minutes off of the announcement. idk what yall think about this
@mathvc I think that's incorrect. The dark blue bar seems to indicate a pass@k evaluation technique, see here. In the video, they say "in aggressive test time settings we're able to get over 25%", which suggests that they're using an evaluation technique that's much more permissive than the one that Epoch had in mind. Eyeballing this chart, I think o3 gets about 6% on FrontierMath.
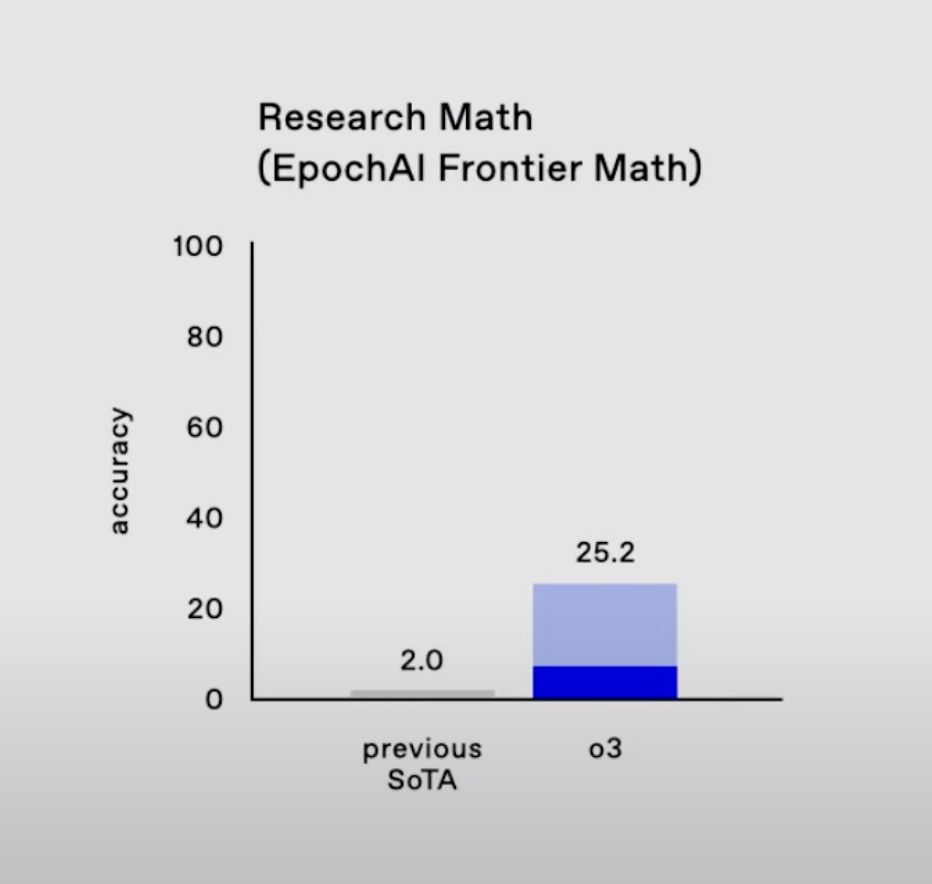
@EricNeyman no. Agressive test-time setting means that they generate longer chains of thoughts. Possibly 100 times longer. But they give only one answer and the answer/proof is correct
@Bayesian Cool -- if so, my next question is whether this criterion is satisfied:
"Having the AI system complete the task does not use more compute than could be purchased with the wages needed to pay a human to complete the same task to the same level"
My friend speculates that they spent about $20k/problem, but that's just speculation. That's probably more than you'd need to pay a mathematician (especially for the easier problems, which are presumably the ones that o3 got right).
Do you think someone at OpenAI would be willing to tell us how much compute they used?
@EricNeyman I think they wanted to keep it private so I'd guess they won't say, but yeah $20k+ seems reasonable. hmmm
@jim this inference strategy called majority voting. It is quite different from pass@1. OpenAI did pass@1
@jim I don't think it's true that it would cost much more than $20k/problem to get a human to get 25%+ on FrontierMath. I suspect a top grad student could be paid $1k/problem (a week of work) or less to get 25%.
@EricNeyman i dunno how literal people want to be about the description (e.g. is this an upper & lower bound on who you could hire) but I would agree (1) "$20k/problem" seems like way more than you'd need to hire an excellent grad student to do the same, & (2) "$1k for a week of work" is probably too low (like maybe you can find some folks willing to work for that rate but it's too low for a typical rate).
(i'm basing (2) off 1. yes 1k/wk is a reasonable "grad student salary" but grad students are busy and underpaid relative to skills and generally do not take on additional work at the rate of their salary, & (2) i could check to confirm source but anecdotally heard of some econ students hired to help verify a version of a similar benchmark and the pay was more like $500 for most of a day of work which seems more reasonable. at a glance i'd start with something like $75-100/hr as a reasonable rate given the wording of the question)
@Ziddletwix yup, I'd love d clarification e.g. from @EliLifland on how these judgments will be made by AI Digest.
@Ziddletwix altho i admit i'm not sure how you're supposed to quantify the % of problems they get right? seems ambiguous.
"Having the AI system complete the task does not use more compute than could be purchased with the wages needed to pay a human to complete the same task to the same level"
does this mean you need to be able to pay a single grad student who can also get 20%+ of all problems correct? or can you pay multiple grad students who can each get some smaller fraction of problems correct? (and if so, how is the pay actually calculated there, can they just pick the problems they know how to do, etc).
that phrasing seems very ambiguous—if the "the same task" is actually "can get 20%+ of all problems correct", at a skim i am guessing that would render the pay requirement mostly irrelevant (but i'm not super familiar with the frontier math benchmark, so maybe there's better stats on this, i'm just glancing through the example questions, seems like they're the sort of problems that are "very doable for a math grad student in this area but very few to none mathematicians could actually tackle 20%+ of all problems without investing a toooon of time"—again there might be stats on this)
@EricNeyman I've responded to you elsewhere about this: https://manifold.markets/Manifold/what-will-be-the-best-performance-o-A58Ld8LZZL#kmnki6b21qk. Copying over here below. Looks like we independently converged on $1k/problem for paying humans to get 25%, but I have lower estimates of $$ spend per problem than your friend. $20k per problem seems like it would be pretty crazy given that there are hundreds of problems in the benchmark.
--------------- (copied response from linked comment) -----------------
@EricNeyman thanks for prompting us, here's our current best guess:
Short answer: If resolving now we'd reach out to Epoch and/or OpenAI to ask for more clarity, but if we weren't able to get more information in time, our best (low confidence) guess would be to resolve to the range 10-20%, and the point 16% (edit: now 24%). This is based on cost estimates for o3 and humans, then interpolating between those.
Reasoning:
How many $$$ were spent per problem benchmarking o3? This tweet by an Epoch employee indicates a similar OOM of evaluation spending on FrontierMath compared to ARC-AGI (which was 'low' = $20/task / $2k total, 'high' = $3.5k per task / $350k total). We are guessing these 'low' / 'high' might be similar to the 8% / 25% on FrontierMath, although the 8% is potentially lower than the 'low' as we think dark bars often correspond to one-shot. So let's guess that costs are $20 per problem for 8% performance and $10k per problem for the 25% performance (high end slightly higher than ARC because each problem is harder, low end the same due to dark bar guess above).
How much would it cost a human to get 8-25%? The way that we tentatively think we should approach this for a percentage N is to (a) look at for what cost budget C per problems, you could get 8% performance from humans then (b) say this is the per-problem budget for the whole dataset. In this case, we very roughly guess that the 8th percentile difficulty costs $200 per problem (~4 hours of a grad student) and 25th percentile costs $1000 (~3 days of a grad student). So now we have 2 pairs of points to interpolate between then find the intersection. (score, cost)
AI costs: ($20, 8%) and ($10k, 25%)
Human costs: ($200, 8%) and ($1000, 25%)
Assuming log scaling these intersect at roughly 16%.
edit: update, my best guess is now that this would resolve higher much closer to 25% because Tamay probably meant total cost rather than per-problem cost, but still thinking about it / looking into it.
Here's my updated best guess based on switching to ~equivalent total cost and also getting rid of the adjustment for FrontierMath problems being harder:
AI costs: ($7, 8%) and ($1200, 25%)
Human costs: ($200, 8%) and ($1000, 25%)
Assuming log scaling these intersect at roughly 24%.
@Bayesian I'm not accusing anyone of cheating. It's just very hard to make guarantees about what's in your training set when it consists of the entire internet. This kind of leakage isn't new; it's rather the standard thing to expect, and has happened many times before, see e.g. https://arxiv.org/abs/2410.05229v1
IMO one of the most exciting and challenging frontiers in AI is how to make robust evals for these models. Any fixed, finite set of O(1,000) or even O(10,000) questions is dead in the water in my view. We need the ability to generate billions of questions of a certain format at will, like in the GSM-Symbolic paper linked above. This is very hard; how do you generate billions of advanced math questions that are still solvable by human mathematicians in O(days)?
@pietrokc These benchmarks are literally private and known by only a few people that make them very secure