
This market matches Mathematics: FrontierMath from the AI 2025 Forecasting Survey by AI Digest.
This market is the same as this one but uses different buckets as AI has already exceeded expectations in this benchmark. If it looks like it will even exceed 50% we will make another market with finer buckets for the top-end.
The best performance by an AI system on FrontierMath as of December 31st 2025.

Resolution criteria
This resolution will use AI Digest as its source. If the number reported is exactly on the boundary (eg. 3%) then the higher choice will be used (ie. 3-5%).
Which AI systems count?
Any AI system counts if it operates within realistic deployment constraints and doesn't have unfair advantages over human baseliners.
Tool assistance, scaffolding, and any other inference-time elicitation techniques are permitted as long as:
There is no systematic unfair advantage over the humans described in the Human Performance section (e.g. AI systems are allowed to have multiple outputs autograded while humans aren't, or AI systems have access to the internet when humans don't).
Having the AI system complete the task does not use more compute than could be purchased with the wages needed to pay a human to complete the same task to the same level
The PASS@k elicitation technique (which automatically grades and chooses the best out of k outputs from a model) is a common example that we do not accept on this benchmark because mathematicians are generally evaluated on their ability to generate a single correct answer, not multiple answers to be automatically graded. So PASS@k would consititute an unfair advantage.
If there is evidence of training contamination leading to substantially increased performance, scores will be accordingly adjusted or disqualified.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ5,801 | |
| 2 | Ṁ4,571 | |
| 3 | Ṁ2,235 | |
| 4 | Ṁ1,946 | |
| 5 | Ṁ1,679 |
People are also trading
@AdamK It’s not even released to ultra users on web yet and 2.5 deepthink was never released on API, needed them to manually prompt it once question at a time, which took like 2 months post release. So yeah maybe but not at all guaranteed. I do think they might start the web prompting earlier the second time around tho
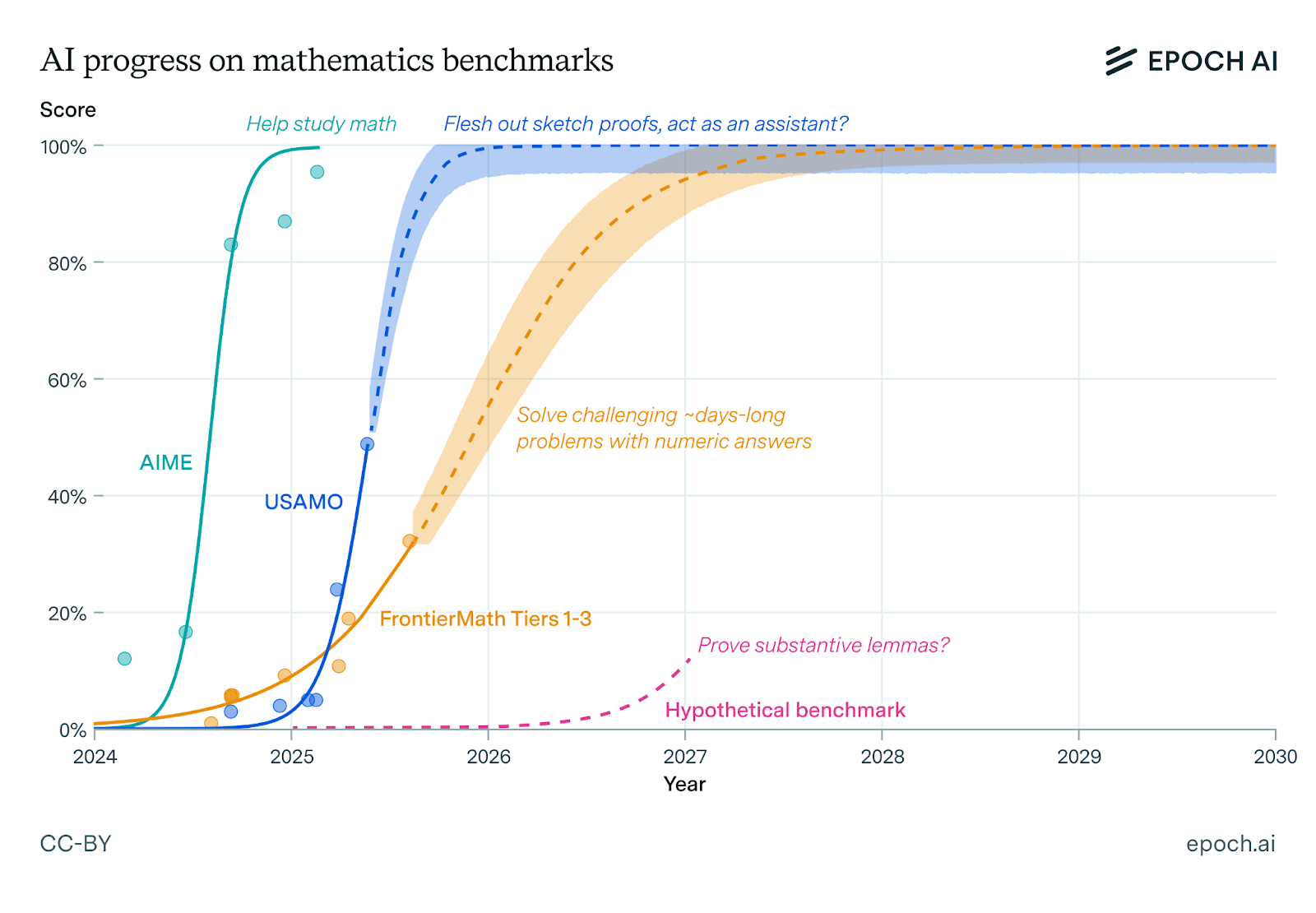
There's probably some alpha in this report from Epoch AI a few days ago: https://epoch.ai/gradient-updates/less-than-70-percent-of-frontiermath-is-within-reach-for-todays-models
The idea is that if you were allowed to stack up all the frontier lab models in a trenchcoat and call that your model, and also give it unlimited retries, then we can get as high as 70% on FrontierMath right now. FrontierMath problems are impossible to guess so the unlimited retries isn't a total cheat.
Point being, a 70% on FrontierMath from a single model without retries is arguably within reach -- no fundamentally new capabilities required -- and is just a question of the resources we put towards it.
Of course end of 2025 is very soon.
@dreev I think "as high as 70%" is misleading. They suggest that as an upper bound, but the actual current score they give for all runs combined is 57%.
@Bayesian what is the resolution source for this? epoch’s leaderboard Tier 1-3?
This resolution will use AI Digest as its source. If the number reported is exactly on the boundary (eg. 3%) then the higher choice will be used (ie. 3-5%).
AI Digest, not epochai. epochai is running a personalized scaffold (that might be worse than what labs have internally) and doesn't make use of test-time compute, which is why the previous market resolved >30% to openai announcing this result using an internal scaffold. If for some reason AI Digest doesn't end up counting it we will have to probably unresolve the previous one? i'm not sure if they've confirmed that openai's 32% counted or not for the purpose of this prediction but if you look at thier resolution criteria i don't see why it wouldn't
@Bayesian is AI Digest even tracking FrontierMath scores actively? They have done so at a couple points in time but it doesn't look like they're rigorously tracking this, and I don't understand why AI companies' internal numbers would be treated seriously at all, given how often they stretch these numbers or outright lie about them! And I don't see any evidence that Epoch is not making use of test-time compute? Do you have a source for that? That doesn't make any sense to me, given that reasoning models are scoring high, and that GPT-5 is delineated as different scores according to the amount of inference time they use?
@bens sorry I misspoke about it not using test-time compute. If a model is say o3-mini-high, they run that model without parallel instances trying different versions of the problem and so on, they just have a regular one-path scaffold iiuc. Whereas labs might run 10000 versions of the model and use some optimized strategy for making use of all those attempts to get a more reliable correct answer. It's the same model, but makes use of 10,000x more test-time compute, for example. This most likely was why o3 did so well on ARC-AGI.
I don't understand why AI companies' internal numbers would be treated seriously at all, given how often they stretch these numbers or outright lie about them!
Because they are serious internal numbers. Do you think openai made up the 32% score? I don't think they often outright lie about them. Ultimately afaiu AI digest will have ultimate say over whether they judge it to count or not. but I think it clearly should
(edited bc previous version was overstating my knowledge) also i haven't seen ai digest like officially stamping updates on any of the associated forecasting challenge’s scores actively, presumably they will track them at the end of the year when it comes to scoring forecasts
@Bayesian AI companies are heavily incentivized to lie about their benchmark scores in every way they can. Benchmark scores are achieved through selective reporting of benchmarks that their model scores well on, creative interpretation of ambiguous scores, reverse engineering of private benchmark datasets for post-training, re-testing many times and picking the best score, etc etc etc. I think there's basically no reason to take at face value AI companies' internal reporting of benchmarks, especially not in the last year or so. I mean, even in benchmarks as silly as Pokemon, AI companies are cheating and manipulating results.
@bens I think you are heavily overstating the amount of scores fraud going on. Do you think openai made up the 32% score? or that they ran o3-mini multiple times and only reported the best score, or obvious statistical malpractice like that?
Benchmark scores are achieved through selective reporting of benchmarks that their model scores well on
Some benchmarks are reported for every new release of reasoning models, this doesn't make much sense in this case
creative interpretation of ambiguous scores
i'd be curious to know in more detail what you mean by this
everse engineering of private benchmark datasets for post-training
Even if true, this would not distinguish epoch.ai's runs and the lab's internal runs, afaik.
re-testing many times and picking the best score
This is obvious statistical malpractice (if unstated, ie if they don't say it was scored with pass@n), I think they try pretty hard not to do this
I think there's basically no reason to take at face value AI companies' internal reporting of benchmarks, especially not in the last year or so.
wdym by take at face value? I'm like 95% sure the 32% achieved by o3-mini with test-time compute and python access and internal scaffold was real, not clear statistical malpractice. Do you place less than 50% on that? or what? I'd like to understand what the actual level of disagreement is
@Bayesian lol incredible timing.
-GPQA diamond is an incredibly strange choice for this analysis because it's (1) a terrible pointless benchmark with bad questions (which I can say because I've helped write questions for grad-level benchmarks like this and they're so universally terrible) and (2) the simplest benchmark to test and validate and hence the one least likely to be cheated on in the way that Epoch is testing for.
-Their methodology doesn't include like 90% of the ways that AI labs would cheat on benchmarks like this, lol.
-I'm not even sure what their point is? They link to other benchmarks that labs do have markedly different scores from Epoch's cataloguing efforts...?!
@Bayesian I guess broadly I just think the whole field of AI benchmarking leaves a lot to be desired. Simple quantitative benchmarks like GPQA or even things like ARC-AGI are immediately goodharted and close to useless in evaluating the rate of improvement of AI.
More sophisticated and complex quantitative benchmarks, like METR, or qualitative benchmarks, proportionally to how much attention they get (remember the R's in Strawberry hijinks with placing specific systems instructions in GPT releases) are much harder to game but still get goodharted over time.
In any case: AI companies, as well as teams within those companies, are heavily incentivized to show improvement in performance, to the point that no internal benchmark results are really useful in determining an answer to "is AI improving along ___ axis" or "how fast is AI improving along ___ axis". I think independent benchmarks with less transparent methodologies, such as METR, are probably state of the art for this reason, and even those leave a LOT to be desired, and companies are still incentivized to game them.
I think really broad systems-level benchmarks are probably the next step in benchmarking. Things like "how many miles of fully autonomous driving in X year" or "total $ of revenue from AI" will start to win out.
>wdym by take at face value? I'm like 95% sure the 32% achieved by o3-mini with test-time compute and python access and internal scaffold was real, not clear statistical malpractice. Do you place less than 50% on that? or what? I'd like to understand what the actual level of disagreement is
Ya, this value is more than double the value as scored by Epoch. It's just completely meaningless to compare their internal value on a scaled-to-100 benchmark under completely different conditions as those used on other models. Either a benchmark is scored the same way for each model that is subjected to it, or it's a completely meaningless number. That "32% value" doesn't exist in a vacuum.
If I go take the SAT test, but I get unlimited time, access to the Internet, I get to take it 10x and throw out the worst 9 scores, and any question that has two answers circled is marked as correct as long as one of them is right... my SAT score is not meaningfully comparable to the score of others.
For example... it's easy to imagine a future (or current) AI model that can get 100% on FutureMath by simply hacking into the answer key, or something of this nature. The explicit value on the benchmark is meaningless, it's only useful as a direct comparison with other past/present/future models.
If I go take the SAT test, but I get unlimited time, access to the Internet, I get to take it 10x and throw out the worst 9 scores, and any question that has two answers circled is marked as correct as long as one of them is right... my SAT score is not meaningfully comparable to the score of others.
I made an effort to distinguish statistical malpractice from the setup being different. Trying 10x and throwing out the 9 worst scores is statistical malpractice. They imo clearly do not do this.
But they likely do make it try dozens of attempts and, without access to the true answer, have it try to notice differences in its attempt to revise its guess. Kind of like letting the AI try the SAT for 5 years of thinking straight. That ‘5 year of test time compute’ ai system is different from the underlying AI model, which can achievr only eg half the score. But thqt doesnt mean the ai system cheated or did statistical malpractice. It didnt compare its solution with the true answer and discard it if it didn’t match or something like that.
It's just completely meaningless to compare their internal value on a scaled-to-100 benchmark under completely different conditions as those used on other models
Why? Some models are biggrr than others or think for longer. Some models use more test time compute or multi agent frameworks. Do you think it’s eg meaningless to say that AI beat Gold on the IMO? Bc no one model did this in one try. In all cases it used a multi agent scaffold that improves the long term reasoning of the overall AI system.
The explicit value on the benchmark is meaningless, it's only useful as a direct comparison with other past/present/future models.
Or past / present / futurr AI systems? In the future ai systems will be increasingly what matters over AI models. I think AI systems are the relevant object here. If models stay as strong but the scaffold they are in lets them unlock 100x more real economic value, it doesnt matter what the comparison between current andnpast ai models is, the AI systems become what matters
@bens c.f. this comment from Eli Lifland (who afaict is responsible for the AI Digest resolution) on the corresponding metaculus question: https://www.metaculus.com/c/ai-survey/30751/best-performance-on-frontiermath-at-end-of-2025/#comment-312894
also this blog post from AI Digest evaluating benchmarks so far: https://theaidigest.org/ai2025-analysis-may