
"Today we're launching FrontierMath, a benchmark for evaluating advanced mathematical reasoning in AI. We collaborated with 60+ leading mathematicians to create hundreds of original, exceptionally challenging math problems, of which current AI systems solve less than 2%.
Existing math benchmarks like GSM8K and MATH are approaching saturation, with AI models scoring over 90%—partly due to data contamination. FrontierMath significantly raises the bar. Our problems often require hours or even days of effort from expert mathematicians.
We evaluated six leading models, including Claude 3.5 Sonnet, GPT-4o, and Gemini 1.5 Pro. Even with extended thinking time (10,000 tokens), Python access, and the ability to run experiments, success rates remained below 2%—compared to over 90% on traditional benchmarks."
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ16,800 | |
| 2 | Ṁ9,575 | |
| 3 | Ṁ6,510 | |
| 4 | Ṁ3,281 | |
| 5 | Ṁ1,666 |
People are also trading
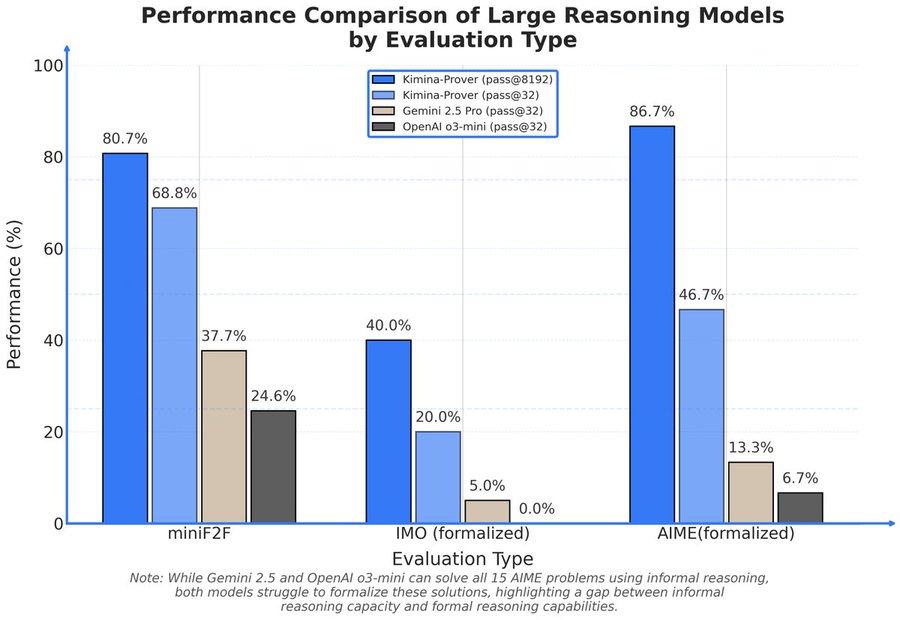
@MalachiteEagle Not yet... But o1-pro's AIME benchmark is similar to this new model Kimina (86%). I believe these formal theorem provers are the real contenders.
@Grothenfla i'm curious what you think of the new natural language models that got gold on the IMO? Like has your view updated? I think that also alphaproof-like systems will become quite good but it's less clear to me than it was when you wrote that comment that they would be better than the general reasoners
@Bayesian Yes, I have updated my view after Gemini's and OpenAI. To be honest I thought that we were very far away from a achievement like this. We still know little about these LLMs but now I think it is possible that they become as good as the best mathematicians in the coming years. But I still think systems like alphaproof still have a better chance in becoming superhuman mathematicians similar to AlphaGo and AlphaZero becoming superhuman in their respective areas.
@Grothenfla yeah i pretty much agree! the only consideration that goes against that is that i could imagine there being like several orders of magnitude (200x?) more research effort and compute allocated to general reasoners than to alphaproof/alphazero-like systems, and there could be enough far transfer or wtv, that this ends up being wrong? Ig i'd add that the narrow math systems would likely become much better at proofs for a similar amt of effort, but probably are hopeless for some tasks mathematicians have to do that are more diverse than theorem proving, like deciding which research direction to go into next and so on. exciting times..?
@MalachiteEagle by end of year we might already have o6 (build into gpt5 or whatever they will call it)
@Bayesian Did something change your mind? It seems like Grok 3 isn't quite at the level of o3 on math and coding benchmarks, even with reasoning enabled.
@Bayesian Though of course, 10% error rate is also an estimate, right? In the world where an AI model reaches 90%, the error rate is probably a lot lower.
@TimothyJohnson5c16 yeah 10% error is an estimate, the errors they found were like 6% iirc, and they estimated # of errors they would have missed
@NebulaByte i think i mean that about 10% of (question, answer) pairs in the benchmark are eroneous in some way, either that the question has some hidden assumptions that make it not necessarily solvable, or the answer is incorrect (the person solving the problem to add it to the benchmark made a mistake in some step) or something like that