The next big model that OpenAI that's the successor to GPT-4, whatever its called.
 1,000
1,000People are also trading
apparently the market disagrees but my understanding of the situation is that gpt-4o was likely the base model for o1, and that o3 and gpt-5 were further finetunes of o1? (also seems possible that gpt-4.1 was the base for o3 i suppose.) so this seems extremely likely to me?
the original gpt-4 was an undertrained 1.8T MoE, and there doesn't seem to be a huge advantage to doing RLVR with a larger model (see: Claude 4.5 Sonnet outperforming Claude 4.1 Opus on various SWE tasks), so it would greatly surprise me if GPT-5 was larger than GPT-4. and the inference api costs for GPT-5 are much lower than the equivalents for models like GPT-4 and GPT-4.5, which supports this hypothesis
i suppose this is likely to take a stupidly long time to resolve, but it seems very mispriced to me
GPT-5 is probably more total params, but the MoE uses probably on the order of 32B params (based on Kimi/Deepseek/GLM) vs GPT-4s ~222B active
GPT-5 is almost surely smaller than GPT-4.5 in params since they spend more on RL rather than pretraining a large base model.
In general, one GPT should be 10x on some measure of input cost
so
GPT-3 was 175B
GPT-3.5 is probably on the same order, but the 3.2x compute multiplier came is mostly via research optimizations in hardware/software
GPT-4 was released <6 months after 3.5, so they had all the data/etc. in place and just ran it on a larger architecture (presumably 1.8T = 8x222B or 16x111B with 2 active experts)
GPT-4.5, was just the next iteration of their scaling law, so I’d assume it’s 5.7T or so (3.2x more than GPT-4)
My speculation would be that GPT-5 gets a ~10x multiplier from reasoning, so I’m guessing on the order of 2-3T, but instead of 1/8 of the params being active I’d estimate it’s 1/32 or possibly even 1/64, one reason for that is if we look at the input to output pricing ratio, GPT-4 and GPT-4.5 had the output as double the input (30/60 and 75/150) whereas GPT-5 matched Gemini 2.5 Pro’s pricing of 1.25/10 which is an 8x ratio, indicating some 4x efficiency gain in the processing of input tokens (tbh I don’t know the exact mechanism for why MoE is cheaper for input - it makes sense for output since there’s fewer active params, but I need a better understanding of the attention mechanism during the forward pass, nvm it’s the same, only difference is output involves generation/sampling new tokens. anyways I think it’s related to the MoE sparsity since dense LLMs like Llama 3 had equal pricing for input and output tokens)
————————————————-
Anyways that’s my view on the relative size of GPT 3 until GPT 5, the models in between (3.5 turbo, 4 turbo, 4o, 4.1 are somewhat cost optimized versions). Also consider how OpenAI was able to cut the cost of o3 by 80% (10/40 to 2/8), I’m still not fully sure how they did that, but I think it indicates their markup is on the order of 5x (since o3/o4-mini was double the price of Deepseek r1, and it’s fair to assume they’re probably around 40% as large as r1 and OpenAI is just a more advanced lab that Deepseek) plus they made some efficiency gains to not be making a loss, they really needed o3 to compete with Gemini 2.5 Pro in June 2025 or so.
We should also look into the cache discount, the models until o3-mini (aka 4o based) had a 50% cache discount and the ones based on 4.1 (basically 4o but more focused on coding) had a 75% discount, and the GPT-5 series of models has a 90% cache discount.
So let’s consolidate that
0% cache discount: GPT-3, GPT-3.5 series (likely means no MoE, dense)
50%: GPT-4, GPT-4o, o1, o3-mini, GPT-4.5 (these are all like MoE with ~1/8 params activated)
75%: GPT-4.1, o3, o4-mini (these are even more efficient / inference-friendly architectures, likely MoE with some advances mirroring Deepseek R1 breakthroughs, I’d assume roughly 1/32 params are active)
90%: GPT-5(.1/.2) (even sparser to cut down costs as they planned to make reasoning more widely accessible but needed to keep it cost friendly for their 800M+ users, I’d estimate 1/64 or possibly even 1/128)
Note how GPT-5.2 was a 40% price hike, this roughly aligns with 10^0.2 which means around 60% more params, but 10-15% efficiency gains in pricing.
Ok that’s probably the bulk of my analysis,
To get the full picture,
I’d say maybe also look into how o3-mini was a 63% discount from o1-mini
do similar analysis on Google/Anthropic (they generally have a 5x b/w input vs output), xAI, open source models (oss, Kimi, Deepseek, GLM, Qwen)
Consider Cursor and Windsurfs models (Composer and SWE-1/1.5) which I believe mirror the 1.25/10 pricing of GPT-5 but are fine tunes of Chinese models (the rumor is SWE-1 is Qwen and SWE-1.5 is GLM)
@ChinmayTheMathGuy Do you have any sources on how input pricing is related to MoE sparsity? This seems plausible to me, but besides the modern Chinese open-source models being much sparser than previous ones, I haven't read anything that would suggest that's the reason rather than some other improvement in processing input tokens (and these price shifts have occurred concurrently with models almost universally supporting 1 million token context lengths). If there are any research papers or other documents explaining this in detail I'd be very interested
Also this is not really relevant to this market, but I was under the impression that generally, incremental version numbering increases like 5.0 -> 5.1 imply that the same base model is being used (although GPT-4, GPT-4o and GPT-4.1 were almost certainly all different base models). The rapid turnaround from 5.0 -> 5.1 -> 5.2 seems like further evidence for this, it seems unlikely they were able to do entire pretraining runs in that time frame, although the price changes you pointed out are evidence against it. I would make a market on this if there was any hope of learning param counts of these models anytime soon...
@Bayesian No, it's not crazy. OpenAI demonstrated an extremely granular MoE architecture with gpt-oss-120B, which was trained for less than $4 million. Based on that architecture, it's very likely they can easily train a scaled up variant of the model with 1,750B parameters for about $100 million. And it's very unlikely they spent only $100 million on training GPT-5.
@bh Possible, but not certain. Details about the model might leak. There are also some methods to estimate the number of parameters. It's just the model speed that is not a good indicator.
@Bayesian OpenAI very likely serves trillions of tokens per day with GPT-5 (see Google below with 30T tokens per day), which even at the lowest end of plausible estimations (3T tokens per day) amounts to inference costs of least 10 millions dollars per day. Even if they would hypothetically plan on keeping GPT-5 for only three months before fully deprecating it, doesn't it seem weird that they wouldn't or couldn't spend an additional 100 million in training for reducing operating costs by more than 1 million dollars per day?
https://techcrunch.com/2025/07/23/googles-ai-overviews-have-2b-monthly-users-ai-mode-100m-in-the-us-and-india

even at the lowest end of plausible estimations (3T tokens per day) amounts to inference costs of least 10 millions dollars per day
Not true. a LOT of google's token use for instance likely comes from very small models where almost all the tokens "processed" are as input and cached and are being processed by tiny models, like when reading people's emails or google docs or whatever else, within google products.
Even if they would hypothetically plan on keeping GPT-5 for only three months before fully deprecating it, doesn't it seem weird that they wouldn't or couldn't spend an additional 100 million in training for reducing operating costs by more than 1 million dollars per day?
Definitely not weird. they spend training as long as the training gets them useful gains, but it's not easy to use up enough gains bc data-wise they are limited. and if they "better use the data" by scaling the model up, it makes inference more expensive in a way that is kind of non obvious to model and idk what the like strategically best curve is like
so yeah i suspect gpt-5 has around as many parameters as gpt-4 and would lean toward fewer but i don't actually know
Not true. a LOT of google's token use for instance likely comes from very small models where almost all the tokens "processed" are as input and cached and are being processed by tiny models, like when reading people's emails or google docs or whatever else, within google products.
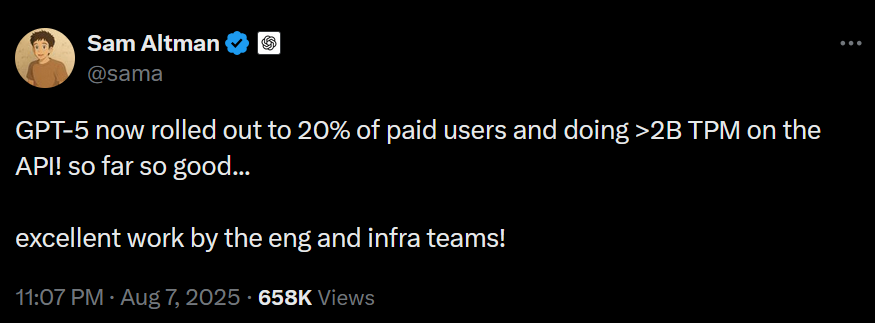
That's ~3T tokens per day even at 20% rollout. That includes input and cached tokens, but GPT-5-thinking produces so many output tokens, that they probably have the largest share by far.
Definitely not weird. they spend training as long as the training gets them useful gains, but it's not easy to use up enough gains bc data-wise they are limited. and if they "better use the data" by scaling the model up, it makes inference more expensive in a way that is kind of non obvious to model and idk what the like strategically best curve is like

That's exactly what you'd expect, if you spent more compute on training: less output tokens for the same results. A rough approximation is that you can substitute test-time compute with training compute, which would imply 2x to 5x more training than o3. With the dense model scaling laws that would result in only 30%-50% less throughput, but GPT-5 is almost certainly not dense. For sparse models the throughput loss can be negligible or they can be even faster when sparser than the baseline (which is probably the case for GPT-5. Either that, or they use a lower quantization, perhaps as low as 1.58bit / parameter). As for the training data, yes, OpenAI seems to have run out of sufficiently high quality human data a few months ago, but I haven't heard from any major AI company that they encountered significant problems in training with synthetic data.
In any case, here's some independent estimation (https://www.theguardian.com/technology/2025/aug/09/open-ai-chat-gpt5-energy-use):

Please clarify "The next big model that OpenAI that's the successor to GPT-4, whatever its called." Is this market about GPT-4.5 (just released, plausible claimant to that description) or GPT-5 (speculated to be released in ~two months, the model named in the market title)?
Edit: Oh, market creator's account is deleted. What now?
Which GPT-4 and which GPT-5? Initial release of both?
It seems that OpenAI sometimes makes models with different parameter counts available as different versions of the same external name. For example, it looks like GPT-4o just shrunk.