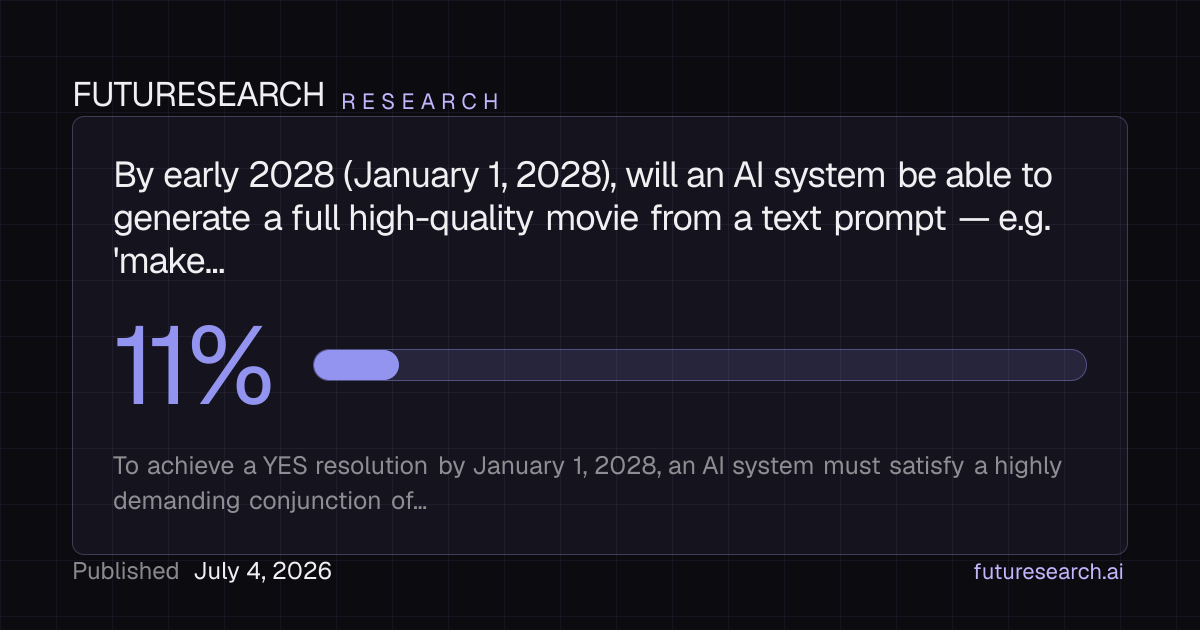
EG "make me a 120 minute Star Trek / Star Wars crossover". It should be more or less comparable to a big-budget studio film, although it doesn't have to pass a full Turing Test as long as it's pretty good. The AI doesn't have to be available to the public, as long as it's confirmed to exist.
 1,000
1,000People are also trading
more random things on r/aivideo today: https://www.reddit.com/r/aivideo/comments/1ulocjg/princess_starcrystal_origins/
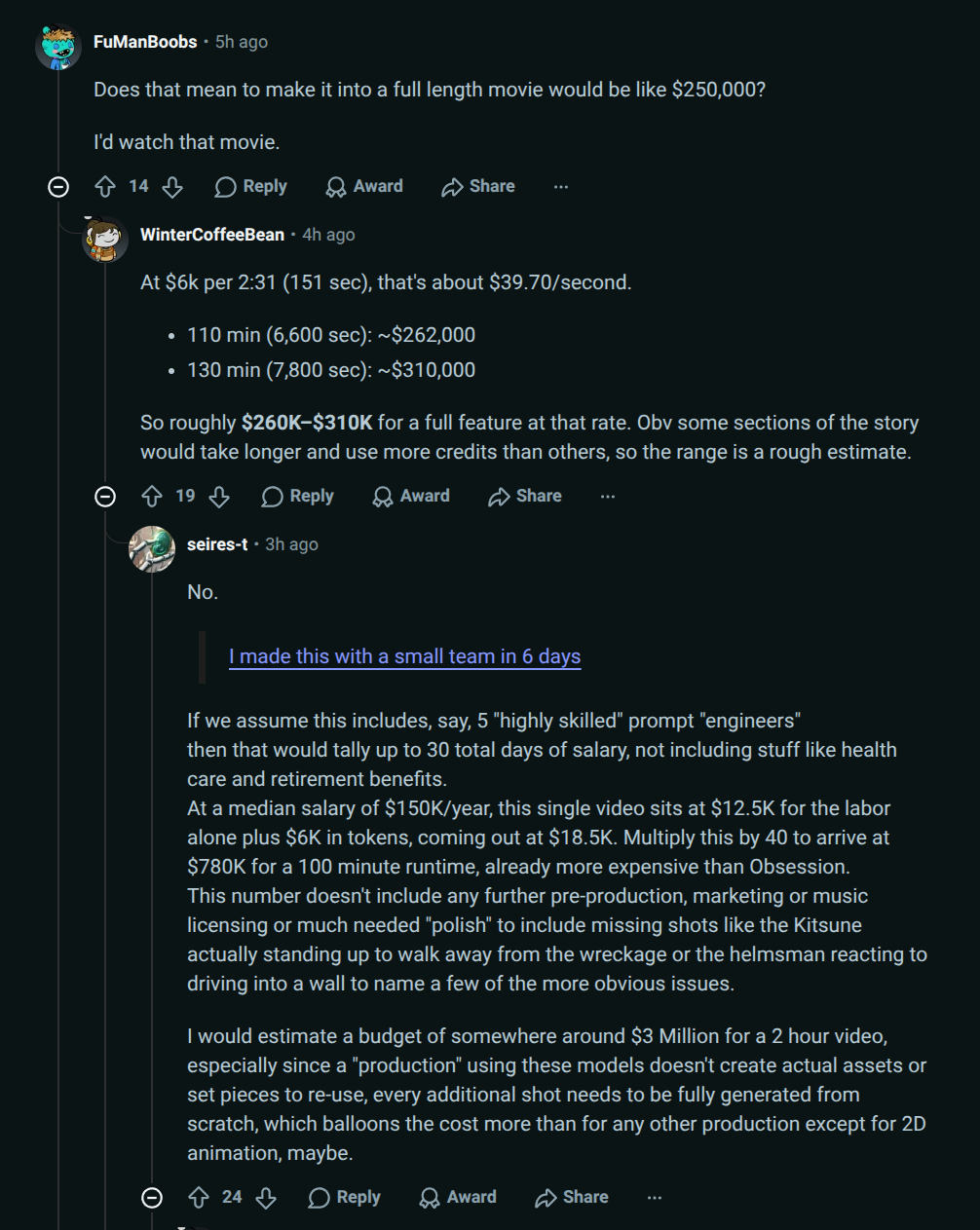
So how far away are we from automating the bit where they're still paying salaries to humans to smoosh the slop together?
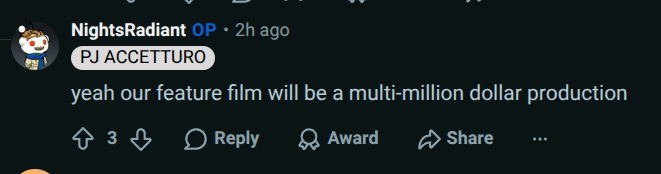
https://www.reddit.com/r/aivideo/comments/1ukmq3x/comment/ouybmdz/?utm_source=share&utm_medium=web3x&utm_name=web3xcss&utm_term=1&utm_content=share_button
OP claims associated feature film will be "multi-million dollar production"
Switching to YES mostly because of recent work on harnesses. We don't need an AI to one-shot this from a prompt in a single model call, if it can instead spin up an orchestrator which farms out the work of making individual shots to subagents, reviewing to other subagents, editing to others, overall review to more, and cycle until done.
From doing some local experiments running orchestrated pipelines iterating image generation to "one shot" comparison grids of static images, we're not there yet even for images, but another 18 months at anything resembling the current rate of progress and I think we will be. If I reran it with a Fable orchestrator (which released shortly after) and some prompting instructions to really try to work at quality maybe we'd be closer today than yesterday, even.
Main question (aside the unlikely event that the exponential stops right now) that stops me bidding it up massively is that I think the cost of running something like this could easily be prohibitive. 1200 minutes, on what I think is an optimistic assumption that you need to generate 10x as much as ultimately goes in, on Veo 3.1 Standard is $54,000. Getting this to actually work could be more- even an OOM more- if we need a bigger video model. So to actually see this happen we might need to see someone making a serious commercial effort out of it.
@0xseraphim Yeah- we just need them to be convinced there is a market for these movies and to give it a go and even at $500k a movie they could do it and profit.
There are also techniques I'd expect such a pipeline to use to bring cost down, like being prompted to make low res output while the orchestrator iterates the basic coherence of the movie at the full end to end level, and only then using the higher quality models to almost "upscale" this and get all the details and finegrained coherence issues that the simpler models get wrong right, which might mitigate the amount of editing work required.
@jbeshir my sense in the timeframe of this question, what we're likely to see are the results of marketing stunts intended to attract massive investor capital. To then go after a large chunk of the movie industry in 2028-2035 with their products: agent-based movie generation frameworks/harnesses.
I suspect we'll get flashy demo websites, from multiple companies including some based in China, each with example movies. And the movies will be released for free on various platforms as part of their marketing programs. We'll get certain niches of the movie industry that will be pushing much harder for this than others, so the style of the announcements will vary.
This will start to happen in mid-late 2027
I just have to wonder how many "yes" bets are people seeing (legitimately interesting!) AI movie-making projects and just not understanding what "to a prompt" means.
But whatever, my "no" investments in this over the years have yet to disappoint me.
@TheOtherKC no problem in unfolding a full thing from a prompt like in the description. Image, book, and music generators do this all the time.
The only question is the quality of the final product.
(rn it's kinda bad on the storytelling side, but images and stitching are close to being solved)
2h may be too costly for randoms, but some Netflix may do this if they're interested.
@ICRainbow Netflix wouldn’t do it to a prompt even if they hypothetically could though. But I think if someone can it will probably happen as an expensive demonstration or experiment (e.g. via AI company), so I don’t think think that seriously affects the resolution odds
@TheOtherKC Agents will use interactive environments and make calls to surrogate models to iteratively develop media. What you see humans doing now with calls to multiple models will be trivial to automate. This question is obviously going to resolve YES because there will be an agent that takes a prompt and turns it into movie. People mistakenly voting "no" based on end-to-end text-to-video models are misunderstanding what "to a prompt" means.
@0xseraphim And I believe you are significantly overestimating the capacities of agents, particularly in ability to judge output. These will not be "trivial to automate", and significant human oversight will remain necessary to produce an even mediocre output.


@0xseraphim The question is whether the maximum level of the 1 gem out of a thousand is a 20 minute short story movie, or a bad movie, or good enough to resolve this market. I lean towards the former
@DavidHiggs if an agentic harness can make a high quality 20 minute short story then it can probably make a high quality 120 minute movie too with enough tokens
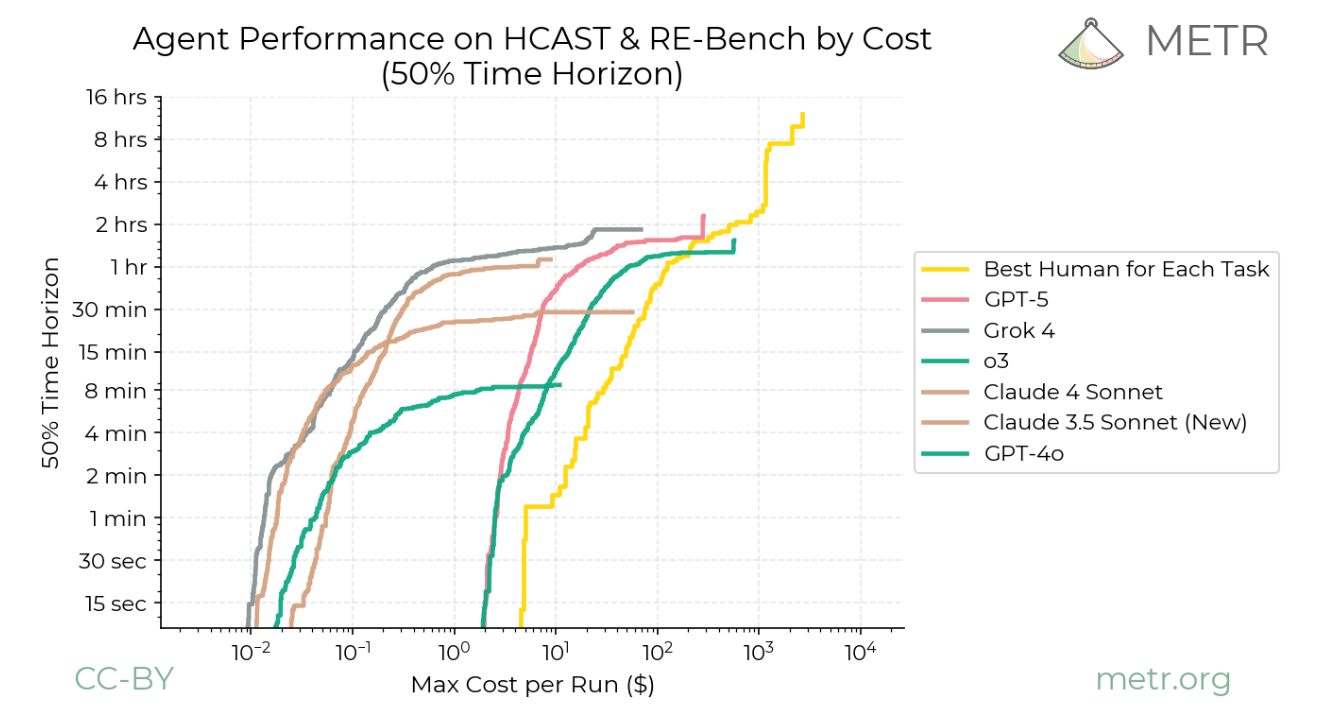
Even with a very simple harness, with a given model you get longer METR horizons the more compute you spend (up to a point). With better harnesses you continue to get more juice as you give it more compute.
@DavidHiggs so unless for some reason "20 minutes" just happens to be the intrinsic upper limit of your model and you've already built the ultimate harness that cannot be improved upon, then if you can do "20 minutes" then you can probably also do a lot more with additional compute.
@0xseraphim well yes, but like you said only “to a point” (a.k.a. diminishing returns); the question is how far out those diminishing returns are for various levels of the AI/agentic harness system, including overall planning & design, scripting, editing, quality control, “taste” in multiple senses (could easily be the bottleneck), etc., and of course likely most importantly the actual video model.
I just don’t think it will come together/the diminishing returns will scale out to the time + quality levels in time. Amusingly, I do think it will happen soon after, but probably either 2029 or 2030
@DavidHiggs my sense is that people here are overestimating how much the average movie watcher pays attention to details in movies over that long a time horizon. You could slowly let the facial features of the actors drift over the course of the movie to become completely different, and a lot of viewers wouldn't notice a thing
@DavidHiggs I'll admit I'm amused this is coming from the person who simultanously thinks we're going to get Full VR BCIs in 2034 🤣
/RemNi/full-vr-brain-computer-interface-be-26c0cd7762d5
So slow ramp up and then omega foom after 2030?
@0xseraphim RSI is one helluva drug.
But yeah, roughly I think we'll likely hit AGI & strong RSI too late for movies at the start of 2028 and well in time for anything by 2034 (median ~2030). Admittedly I think was implying a bit too strong on that market (it does have very hard conditions), in fact I've only ever held no shares in it.
I stand by my rough argument in the screenshot, but crazy ASI/RSI is a higher bar than AGI/strong RSI and will likely come later, so yeah that market was and probably still is a bit high.
@DavidHiggs Well, I've got the market for you: /MilfordHammerschmidt/by-what-year-will-an-ai-be-able-to-3bc2b61ef5cb .
@TheOtherKC Yeah, I actually made a couple bets on that recently, including some yes on 2029 shares. It's interesting how the bulk of the probability mass in that market is 2027/2028. Basically the market expects the modal outcome to be Scott's market narrowly resolves no, then the capability exists in the coming months during 2028 (kinda similar to Amodei's code written by AI predictions). XD
@0xseraphim true, possibly even before 2027, but the timing of everything seems almost at its most uncertain right now