 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ13,683 | |
| 2 | Ṁ8,643 | |
| 3 | Ṁ2,441 | |
| 4 | Ṁ2,165 | |
| 5 | Ṁ1,637 |
People are also trading
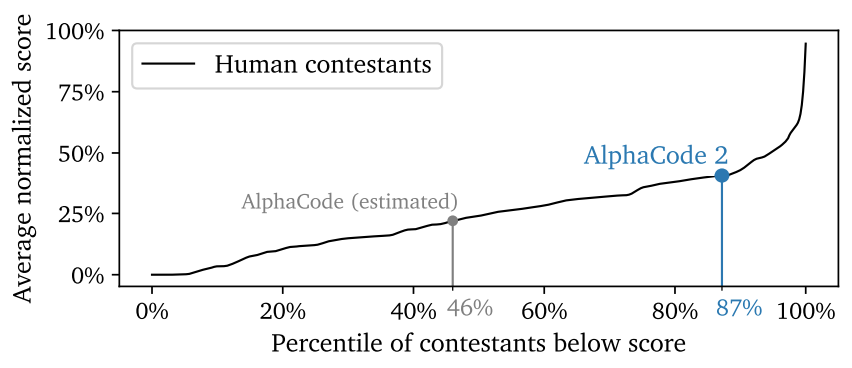
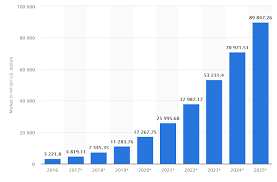
tarting from this histogram (Wikipedia ),we can see that the market size of AI from 2016 to 2023 has been growing steadily. AI, exemplified by tools like OpenAI's Codex, continues to advance and automate certain programming tasks. However, the complete replacement of human programmers appears unlikely in the foreseeable future. This is because the nuanced and creative aspects of programming, as well as the need for ethical judgement and understanding of complex human needs, remain beyond AI's current capabilities.
while AI, exemplified by tools like OpenAI's Codex, continues to advance and automate certain programming tasks, the complete replacement of human programmers appears unlikely in the foreseeable future. The nuanced and creative aspects of programming, coupled with the need for ethical judgment and understanding of complex human needs, remain beyond AI's current capabilities. The evolving role of programmers may involve greater collaboration with AI, emphasizing creativity and problem-solving. Ethical considerations and the irreplaceable human touch in coding underscore the necessity for a balanced approach to AI integration, ensuring it complements, rather than supplants, human expertise.
A survey indicates 59% believe AI may replace programmers, with 21% foreseeing it within 5-10 years. However, 34% think it will occur post-2031. Computer programmers have a 52% automation risk score. AI coding tools like Codex and Copilot aid programmers but won't fully replace them, as creativity and ethical judgment remain pivotal.
Aman. (2023, May 23). Will AI replace programmers? (2023). Thelearness. https://thelearness.com/will-ai-replace-programmers/
As this will probably resolve NO I made a duplicate market for 2024 Will AI outcompete best humans in competitive programming before the end of 2024?
@42irrationalist But the money I put in doesn't come out? Doesn't seem like the same thing. I would rather play with mana I earned through the website anyway.
@Tater It doesn't come back to you, but you can donate it to charity!

Tangentially relevant, DeepMind claims to have discovered an improvement to sorting algorithms using AI.

@tailcalled according to people on Twitter, it only removed one instruction, which hardly seems like an innovation worth a Nature paper
@tailcalled also c'mon, figuring out a better sorting algorithm is way different then doing competitive programming
@tailcalled Note that while the Nature article that made the news is recent, the change in question was introduced way back in January 2022.
https://reviews.llvm.org/D118029
@RobinGreen You underestimate the muted yet extremist enthusiasm of the code golf gallery. Imagine a 100,000 competitors on TopCoder, HackerRank, etc. doing the slow golf clap at once.
They're at 34% right now and estimate top humans at 90%. The strongest argument for YES is that this is something that they can self-train on (like games, where they've made fast progress), but the economic incentive to optimize for competitive coding over "median coding, but across a wide variety of domains" seems small, and they've made a pretty explicit shift from research-for-awesome towards implementation-for-product, so the existing trend line is probably even too high

@MatthewRitter Also I think the beginner problems vs. expert problems is comparable to the difference between solving intro calculus problems vs. doing IMO problems.
You can beat quite a large amount of humans by doing extremely elementary problem solving and just being able to code correctly and quickly.
@levifinkelstein Great point. I'm remembering how much of standardized testing was just about not getting bored and distracted (and noticing when a question was designed to be in the top decile of difficulty)
Y’all should nominate your markets here to be showcased:
https://manifold.markets/Austin/manifold-may-showcase-will-25-users?r=Rm94dHJvdA