METR tracks the maximum "task length" (for humans) of tasks that frontier AI systems can complete with 50% success. This task length is viewed as an important measure difficulty for AI systems since mid-late 2025 AI systems seem to struggle with autonomy over long time scales. So far, METR has projected an (approximately?) exponential growth in task length.
I (Cole Wyeth) expect that that this exponential will become a sigmoid in the near term, while Daniel Kokotajlo (an author of AI 2027) seems to expect exponential or super-exponential growth.
We placed a related 250 USD bet here: https://www.lesswrong.com/posts/cxuzALcmucCndYv4a/daniel-kokotajlo-s-shortform?commentId=gvRoTZuKZKGhbiEWA
I will attempt to interpret any reasonable ambiguities in the above terms in Kokotajlo's favor - as follows:
Kokotajlo wins if METR's frontier 50% task length is greater than or equal to 8 hours for any model which finishes training by March 31st 2027, whether or not that model is publicly available at that time. Unless it looks close I'll resolve the market (and the bet) 2 or 3 months later - open to changing this if Kokotajlo thinks it is too quick.
Even if the bet resolves early, I am not bound to pay Kokotajlo until March 2027 (otherwise the bet is not truly 50:50), though I may pay early for convenience at my discretion. However, if Kokotajlo wins I will immediately resolve this market.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ642 | |
| 2 | Ṁ556 | |
| 3 | Ṁ346 | |
| 4 | Ṁ95 | |
| 5 | Ṁ90 |
People are also trading
There are very few 8+ hour tasks in the METR suite, and most of them are drawn from a different dataset (RE-Bench). It seems very hard to reason about what the trajectory will be at the 8 hour mark, because the dataset does not really extend that far. Regardless of which way this turns out, I'm not sure this result will tell us much unless the dataset is enriched with more long tasks. Does this bet only consider the set of tasks in the benchmark today, or does it accept new tasks being added as model time horizons increase?
@Nick6d8e I will resolve this on METR's assessment, by default the graph they maintain here: https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
Personally I trust METR to use reasonable tests at 8+ hours as necessary.
@Nick6d8e METR's current suite is definitely long-duration enough to yield a 50% 8 hour time horizon. It just might be somewhat noisy or less robust. Here's what the fit looks like for GPT-5. The error bars on the right buckets aren't that huge, and there would be real signal if an AI model saturated the entire set of tasks, or even the <4 hour ones.
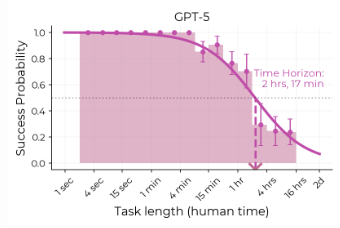
@JoshYou anyway I have actually declined to make markets for METR past next August because I'd like to see what their next batch of tasks looks like and how it changes their estimates if at all. But that's because I think >24 hours by end of next year is likely.
@JoshYou I definitely agree that it is possible to get a time horizon of 8 hours given METR's current suite, and even possible to get times that are longer than any of their tasks (since they're just computing a logistic regression fit). My concern is just that the tasks peter out by the time you get to 8 hours, and the RE-bench tasks (which all have a duration of exactly 8 hours) come from a different distribution than the rest of the dataset, and have a different scoring system. So I just think there will be a lot of variance at the 8 hour mark depending on how well calibrated these special tasks turn out to be with the rest of the data. But it would not shock me if by the time models start knocking on the gate of 8 hours, METR has added a bunch of new items to their dataset and this is no longer a problem.