Since the title has char limitations, here is the full question:
Will a model comparable to, or better than, GPT-4 be trained, with ~1/10th the amount of energy it took to train GPT-4, by 2028?
Many models will be kept secret, and their training details will prove hard to estimate. We will try our best to get an estimate. If its roughly within one OOM of required threshold, it'll count.
The question resolves in its spirit of whether low energy high efficiency models will be trained, than about whether it'll be 1/10th or 1/9th the energy.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ280 | |
| 2 | Ṁ180 | |
| 3 | Ṁ35 | |
| 4 | Ṁ29 | |
| 5 | Ṁ28 |
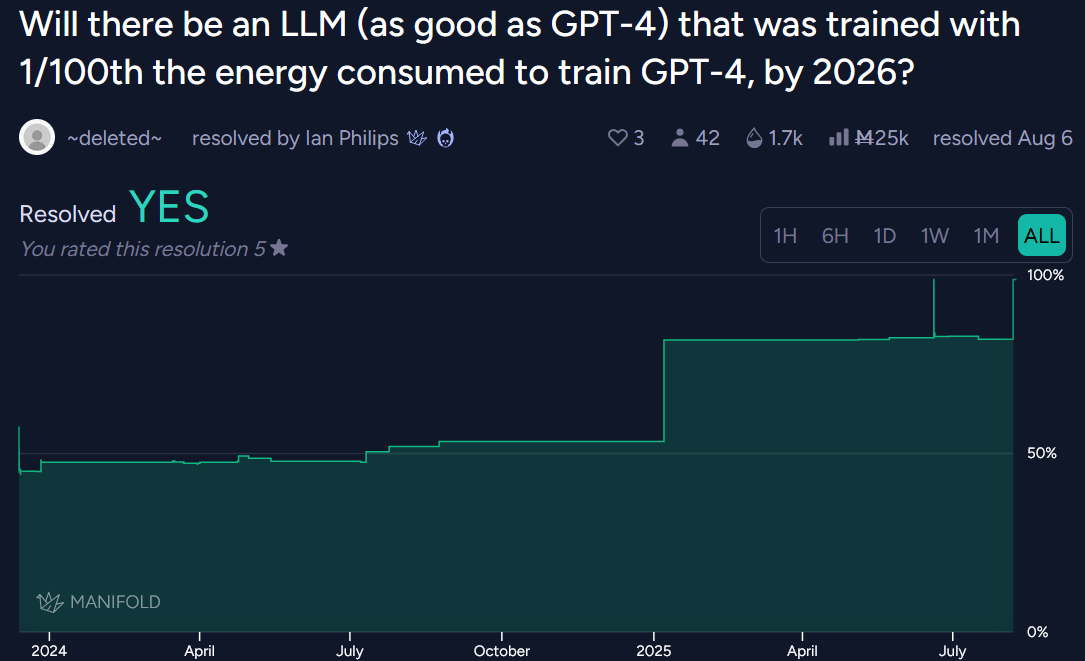
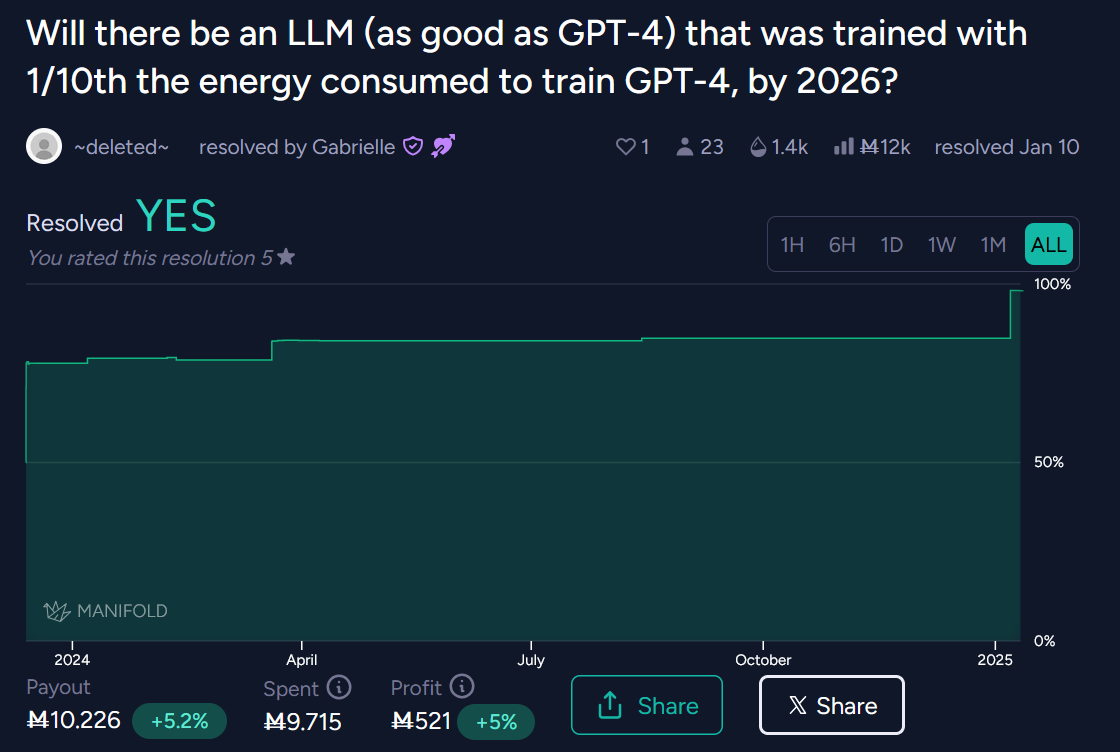
@mods Resolves as YES (creator deleted), see https://manifold.markets/_deleted_/will-there-be-an-llm-as-good-as-gpt-86cc24a5766c, https://manifold.markets/_deleted_/will-there-be-an-llm-as-good-as-gpt
https://epochai.org/blog/trends-in-gpu-price-performance
https://epochai.org/blog/revisiting-algorithmic-progress
lf algorithmic efficiency doubling time is 9 months, top-ml gpu energy efficiency doubling time is 3 years, and ml gpu cost per flops halves every 2 years, we'll be there in 3 years. Just requires someone to train it for ~$1M or so from 2026 to 2028 and make the training details public.
I'm confused about the algorithmic efficiency trends (if they apply here) and am not sure it'll actually shake out like that.