
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ281 | |
| 2 | Ṁ69 | |
| 3 | Ṁ45 | |
| 4 | Ṁ15 | |
| 5 | Ṁ14 |
People are also trading
@traders I'm fairly convinced by the below arguments. If it was closer this might be a mess, but there's a good amount of margin on costs. If you think this is a mistake please speak up.
@mods Resolves as YES (Gigacasting has been inactive for over a year). See comment below for the detailed calculation. @Fynn raised the objection that the compute costs declared by OpenAI don't seem to include the costs for generating synthetic training data, but that doesn't seem like a valid objection because
a) Synthetic data is reused for training a whole bunch of models and refreshes, so attributing the costs to a single model does not reflect the actual amortized costs
b) Inference is much cheaper than training
Given a) and b) it should be very clear, that the amortized, training adjacent costs can't be more than the training costs. These direct costs are well below 500,000$ so the total stays under $1mm.
The details are also included below in my answer to @Fynn
@Gigacasting Resolves as YES.
gpt-oss-20b fits the bill with just about 210,000 H100 GPU hours of training (page 5 of the model card https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf)

Vast.ai rents the H100s for less than $2 per hour, meaning that OpenAI trained gpt-oss-20b for about 420,000$:
gpt-oss-20b destroys GPT-4 in a direct comparison. It's not even close. GPT-4 still occasionally struggled with primary school math. gpt-oss-20b aces competition math and programming, while performing at PHD level on GPQA (page 10 of the model card, see screenshot below):
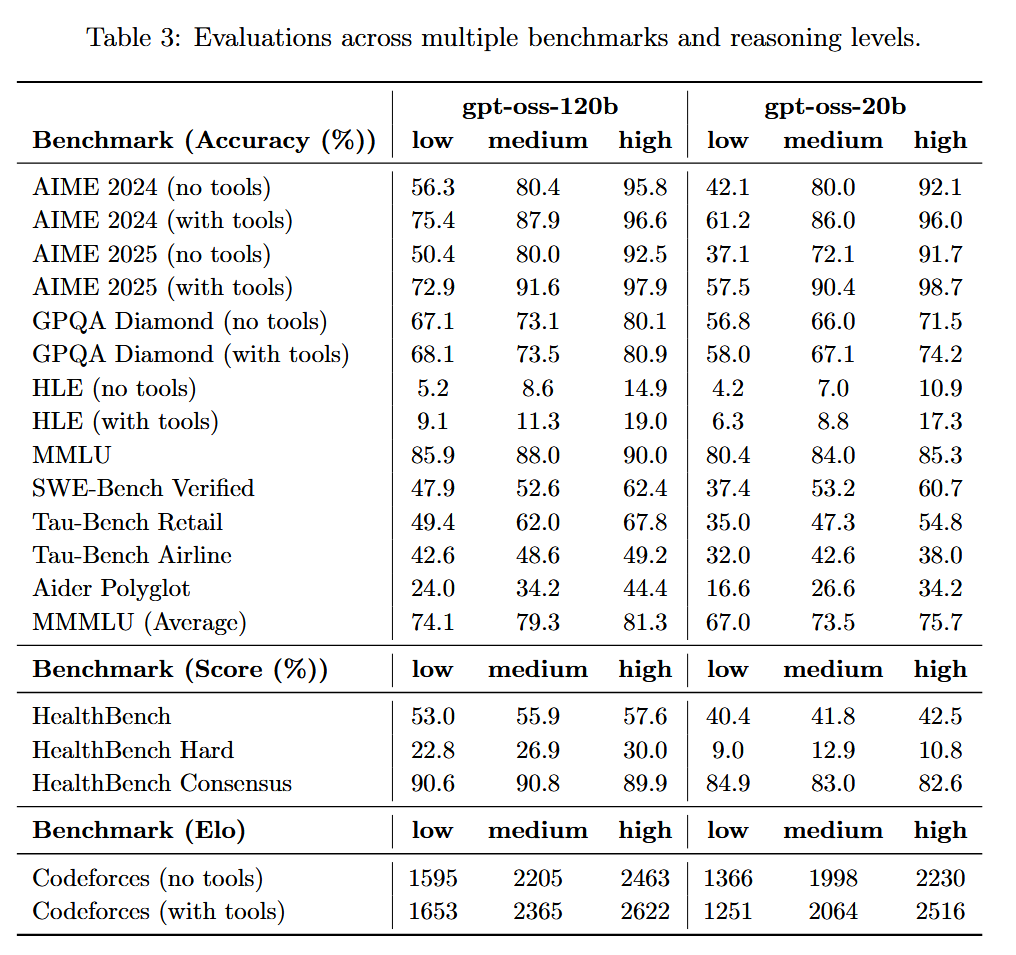
AIME 2024 (no tools)
• 20b: 92.1%
• GPT-4 (orig): ~10–15% (proxy: GPT-4o reported 12% and the 2023 GPT-4 wasn’t better on AIME-style contests). Result: 20b crushes it.
(https://openai.com/index/learning-to-reason-with-llms)AIME 2025 (no tools)
• 20b: 91.7%
• GPT-4 (orig): no reliable public number; based on AIME-2024 behavior, likely ≤20%. Result: 20b ≫ GPT-4.GPQA Diamond (no tools)
• 20b: 71.5%
• GPT-4 (orig baseline): ~39%. Result: 20b ≫ GPT-4.
(https://arxiv.org/abs/2311.12022?utm_source=chatgpt.com)MMLU (5-shot)
• 20b: 85.3%
• GPT-4 (orig): 86.4%. Result: roughly parity (GPT-4 a hair higher).
(https://arxiv.org/pdf/2303.08774)SWE-bench Verified
• 20b: 60.7%
• GPT-4 (orig): 3.4% (20b simply crushes GPT-4)
(https://openreview.net/pdf?id=VTF8yNQM66)Codeforces Elo (no tools)
• 20b: 2230 (with tools 2516)
• GPT-4 (orig): no official Elo; GPT-4o scored ~808. So original GPT-4 likely sub-1k on this setup. Result: 20b ≫ GPT-4.
(https://arxiv.org/html/2502.06807v1)
@ChaosIsALadder Gigacasting is no longer active, you would have to ping the mods. In the case of gpt-oss I disagree because it is likely trained on lots of synthetic data, which costs compute to generate. Though I think this question should resolve yes for sure this year.
@Fynn The problem with counting synthetic data towards the training of this model is that the synthetic data is not only used for training one model. It's reused over and over again, meaning that the amortized cost is low. That's why no company is attributing the full costs to a single particular model.
Aside from that, inference is much less costly than training (about 9x, see calculation below), and the training costs are only 0.42 million. Even if the cost of generating the same synthetic data were attributed to each model repeatedly (which it shouldn't), it's not plausible that the generation costs more than the training.
Costs for inference vs. training: Inference is a forward pass only that requires just two FLOPs per parameter (one addition and one multiplication). Training is 6 FLOPs (2 FLOPs for the forward pass and at least 4 FLOPs for backpropagation). That would be 2 FLOPs for inference vs. 6 FLOPs for training, but they're not the same FLOPs. Inference is nowadays typically done on 4-bit, while training has to be done at higher precision, typically a mixture of 16 and 32-bit. It's still at least 3x slower per FLOP than 4-bit inference, so inference ends up being at least 9x faster than training.
@firstuserhere so by moores law gains alone you would expect 16 fold reduction, bring you down to 6 million. There are also chip architecture gains not just from adding transistor, training efficiency gains, finding ways to filter the training data to not waste compute on worthless low information examples. (For example trying to memorize hashes or public keys that happen to be in the training set).
Also if the gpt-4 source is similar to the gpt-3 source it's a tiny python program of a few thousand lines. Open source versions exist and over the next 7 years many innovations will be found that weren't available to OAI.
@GeraldMonroe oh wow looks like my predictions were correct for the most part. There were many innovations made but the main one was synthetic data.