
EDIT: Realizing that future versions of Gemini this market is interested in comparing might still not be called "Ultra". So changing the language to include any future version of Google's model referred to as "Gemini".
This is essentially the same question as the one listed below but resolves at the end of 2024 instead of May 1st and includes any future version of Gemini (until the EOY deadline).
For completeness, below is essentially the same description from the first question but with a different date and references to future versions of Gemini (not just "Ultra").
Access to Gemini Ultra hasn't been publicly released as of December 16th 2023 yet but according to Google's technical report from their blog post claims to beat out GPT-4 on various benchmarks.
It's a challenge to evaluate LLM-based chat assistants directly and their multiple methods, but one way was developed to use human preferences in a "Chatbot Arena" as presented in this paper & blog post by the Large Model Systems Organization (LMSYS) team. There is a "Chatbot Arena Leaderboard" on HuggingFace from this team with this idea that uses human preferences to create an Elo rating to rank the different LLM-based chatbots.
As of December 16th, GPT-4 models sit at the top three spots with Gemini Pro sitting below GPT-3.5-Turbo-0613 but slightly above GPT-3.5-Turbo-0314.
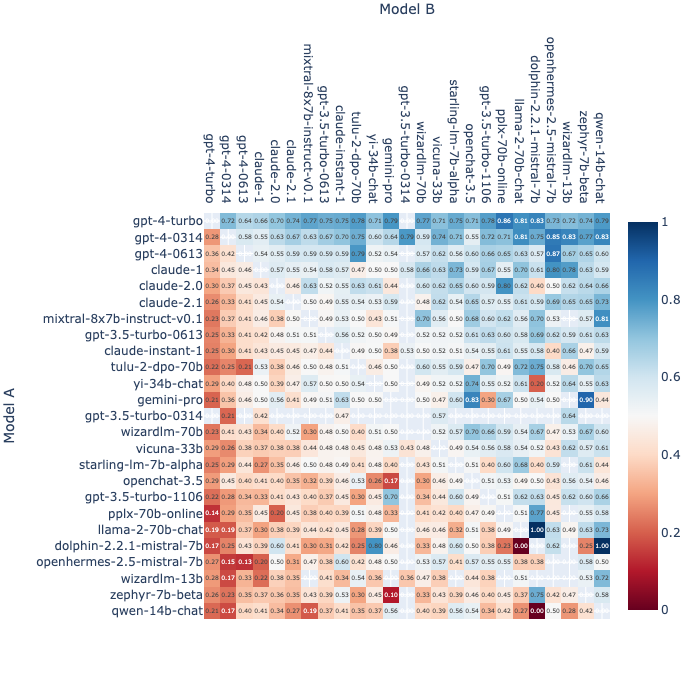
Fraction of Model A Wins for All Non-tied A vs. B Battles (2023-12-16)
Highest to lowest ranking of models goes from top to bottom

Bootstrap of MLE Elo Estimates (1000 Rounds of Random Sampling) (2023-12-16)
This resolves to "YES" if some version of Google's Gemini (if there are multiple versions) has a higher Elo rating than any OpenAI GPT-4 model on the public leaderboard at any point by December 31st 2024 (23:59 PDT). Note, this is only comparing any GPT-4 model and not necessarily the highest rank or most recent model.
This resolves "NO" if no version of Google's Gemini (like "Gemini Ultra") appears on the leaderboard but does not ever score a higher Elo rating than an OpenAI GPT-4 model by December 31st 2024 (23:59 PDT).
This will resolve "N/A" if any of the following occurs:
The "Chatbot Arena Leaderboard" on HuggingFace (via this link: https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard) is no longer publicly accessible before the December 31st 2024 deadline.
A new version of Google's Gemini comparable to or more capable than "Gemini Ultra" never appears on the leaderboard before the December 31st 2024 deadline. (As of December 17th 2023, only "Gemini Pro" appears on the leaderboard).
There are no longer any OpenAI GPT-4 models on the leaderboard before the December 31st deadline and a new version of Gemini has not received a rating (while the GPT-4 models were still on the board).
There might be other edge cases that I might not have thought of but hopefully that covers any that are likely to occur. I may edit/clarify the description if there are new developments or suggestions by others.
The spirit of this is to have a public evaluation metric to compare Google's most capable Gemini model versus one of the most capable models there is today (OpenAI's GPT-4 model).
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ41 | |
| 2 | Ṁ35 | |
| 3 | Ṁ25 | |
| 4 | Ṁ5 | |
| 5 | Ṁ2 |
People are also trading
I resolved to "YES" since "Bard (Gemini Pro)" achieved a higher score than "GPT-4-0314" & "GPT-4-0613") see comment on related market.
Frankly, I was surprised that a "new" version of Gemini Pro come up on the leaderboard today. But since I specifically used the phrasing ***This resolves to "YES" if some version of Google's Gemini...*** and not "future" in that specific line, I believe that this market resolves. If that specific line referenced a "future" version, then the debate would be if this "Bard (Gemini Pro)" entry counted as a "future version". But since it wasn't, I think the only fair thing to do is resolve "YES". (I may create another market that addresses some of the edge cases presented today.)
Thank you @HenriThunberg for sharing the leaderboard results and also @Jacy & @SantiagoRomeroBrufau for additional discussion on whether this market should resolve.
If you thought this market was interesting, highly suggest that you check out a related market of mine that focuses on Gemini Ultra with a deadline of May 1st
https://manifold.markets/VictorsOtherVector/gemini-ultra-will-achieve-a-higher
EDIT: This comment is irrelevant now since the market has resolved to "YES"
Seeing how a version of Gemini Pro had a relatively higher ELO with a relatively small sample size of ~3000 (see @HenriThunberg comment), I'm considering adding a few conditions on resolving this market. This was somewhat addressed by @Jacy comment on the related market w/ a shorter timeline: https://manifold.markets/VictorsOtherVector/gemini-ultra-will-achieve-a-higher#vCqVaPuIK2etlPCEpAAV
I expect that when/if Ultra drops, the sample size will be relatively small at first before leveling out. This could mean that the score technically resolves the market (in the way it's written right now). I'm considering including part of the description of resolving this model that the Gemini Ultra model must have at least some number of samples on the leaderboard, must be "released" for a period of time before comparing scores, and/or the CI being narrow enough to a GPT-4 score to be relatively confident that Ultra is "better".
Definitely open to ideas! I'll make sure to update the description if I implement any other condition for market resolution.
@VictorsOtherVector I think you should create another market for that.
I think the current market should be resolved.
“This resolves to "YES" if some version of Google's Gemini (if there are multiple versions) has a higher Elo rating than any OpenAI GPT-4 model on the public leaderboard at any point by December 31st 2024 (23:59 PDT). Note, this is only comparing any GPT-4 model and not necessarily the highest rank or most recent model.”
Right now, those criteria are clearly met: A Gemini model is above a GPT-4 model:
It is even above a GPT-4 model if you account for the CI (although that wasn’t a requirement as stated in the market).
@VictorsOtherVector I don't think you should resolve markets in ways that are unambiguously inconsistent with their title or description, even if you don't feel that the real world events fit the "spirit" of the market.
@VictorsOtherVector moving the bar after creating the market seems like a worse option than creating a new market representing the changes you have in mind. People have traded on what's stated in your description/title.
@Snarflak Maybe... But according to LYSYSM, it sounds like it could be a new version of Gemini Pro for Bard (Jan 2024). See this comment.
This issue of an "updated" not being clearly communicated has existed in the past (such as with ChatGPT). I do wish it was clearer what version proprietary models were. That could be a reason why the other two versions of Gemini Pro don't perform as well; it's possible that they stayed on the older versions when they were first released. I can imagine that if you were developing with that model version via the API that even in updated/better model could make things worse for your use case.
So in short it could be because of a small sample size, but now I'm wondering if it's just a different model version. But I guess we'll see as more samples come in if that score still stays higher than some of the GPT-4 models.
@Shump I have a couple guesses but my main one is that three different Gemini Pro versions are either basically the same or relatively the same. The non-Bard versions (as of this moment while I write the comment) are at 1114 & 1122 but w/ about +/-15 which I interpret to be nearly the same.
The Bard (Gemini Pro) version has (at the time of this comment) a score of 1215 with a similar confidence interval. However, the sample size is ~3000 compared to the other two Gemini Pro model sample sizes that are more than double that (~6500). If the Bard version is basically the same, I expect the scores to get near each other as more samples are collected.
However, it's possible that the version in Bard is actually a different version from the other 'Gemini Pro' models. Or at the very least, there are more recent submissions on the Bard version than the other two, and all of the models now run an "updated" version. This could translate to the Bard version being more reflective of an "updated" Gemini Pro compared to the other Gemini Pro models on the leaderboard still incorporating scores from an earlier model (the non-updated).
These are of course guesses that I will only assume from publicly accessible knowledge 😄
> (Quick disclaimer, I just started this month working at Google, focusing on ML)
@VictorsOtherVector Congrats on your job! I'm wondering if maybe the Bard version has some extra RLHF done on it compared to other versions.
@Shump btw, here's some more info directly from LMSYS (who run the arena): https://twitter.com/lmsysorg/status/1749818447276671255?t=8TJkDTyJjycdKJ0qxGY-Iw&s=19
Not necessarily helpful in explanatingwhy the different model versions score differently but seems implied that the Bard version is specifically from Jan 2024
@VictorsOtherVector I don't think there's evidence that the bard version got faster updates, but I guess even the fact that it was added later to Chatbot Arena can make a difference.
My juicier theory is that Google is already A/B testing Ultra in Bard.
@Shump oh yeah, this is just speculation. But wasn't implying Bard would get faster updates; more like versioning the model for Bard isn't as important from a business point of view because businesses would likely rely on the API form over the chatbot.
And considering that the API is accessible on Google Cloud (Vertex AI) used by businesses, I think it's a good bet that there's at least a slight incentive to keep things "consistent" over "better". However, he results could absolutely be not because of this.
But that theory of A/B testing Ultra Bard is definitely an interesting idea!
This resolves to "YES" if some version of Google's Gemini Ultra (if there are multiple versions) has a higher Elo rating than any OpenAI GPT-4 model on the public leaderboard at any point by April 30th 2024 (23:59 PDT). Note, this is only comparing any GPT-4 model and not necessarily the highest rank or most recent model.
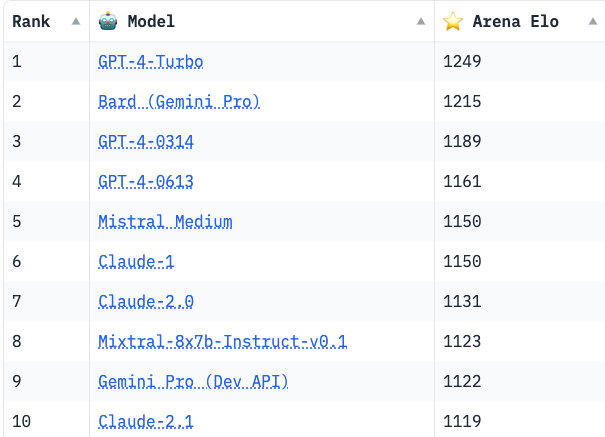
This condition has been satisfied, no? Gemini Pro is now above GPT-4-0314 and 0613.
@HenriThunberg Gemini Pro result doesn't resolve the market since this market is only for Gemini Ultra. But interesting/promising since Ultra in theory should be better than Pro
@VictorsOtherVector oh so since this market was created after Gemini Pro release, it doesn't count as a newly released model even though it now has a higher score than when released?
I can see that, but I can't say it isn't confusing. Btw I quoted from the wrong market (where I retracted my comment), in this one it says "some version of Google's Gemini", which I think should make way for a YES already. But, up to you!
@HenriThunberg Oh no! This is on me; you're absolutely right that this has the potential in resolving the market!
I had made a change on this market with the idea that there could another version after "Gemini Ultra".
Considering that the score of this "Bard" version of Gemini Pro is debatably not reflective of its "true" score (relatively small sample size) and the overall "spirit" of the market, I'm on the side of not resolving this market (just yet).
I would say the future "versions" should only include "announced versions" (by Google). That does make it a weird edge case where a "Gemini Pro" model is "improved" but not really an official announcement of an "improved"/"different" model actually does better than a GPT-4 model (on the leaderboard). But I think this keeps in the spirit of the market while still attempting to keep the resolution "objective".
I think I'll update the description to include this line of thinking, but definitely open to ideas!
(And here I thought I wrote a good enough description to take care of the "edge cases" 😅)
@Soli thanks for sharing!
Definitely related but for this market I wanted to have a focus on how Gemini compares with the top model of today. But that doesn't necessarily mean Gemini will be the "best" model.
For example, here's a scenario where the two markets differ. Say GPT-5 is released before Gemini Ultra and GPT-5 takes the top of the leaderboard. Then say Gemini Ultra is released, gets a higher rating than all GPT-4 models but still lower than GPT-5.
There are more scenarios like this where maybe the best Gemini model beats out older GPT-4 models but doesn't get the top spot.