Access to Gemini Ultra hasn't been publicly released as of December 16th 2023 yet but according to Google's technical report from their blog post claims to beat out GPT-4 on various benchmarks.
It's a challenge to evaluate LLM-based chat assistants directly and their multiple methods, but one way was developed to use human preferences in a "Chatbot Arena" as presented in this paper & blog post by the Large Model Systems Organization (LMSYS) team. There is a "Chatbot Arena Leaderboard" on HuggingFace from this team with this idea that uses human preferences to create an Elo rating to rank the different LLM-based chatbots.
As of December 16th, GPT-4 models sit at the top three spots with Gemini Pro sitting below GPT-3.5-Turbo-0613 but slightly above GPT-3.5-Turbo-0314.
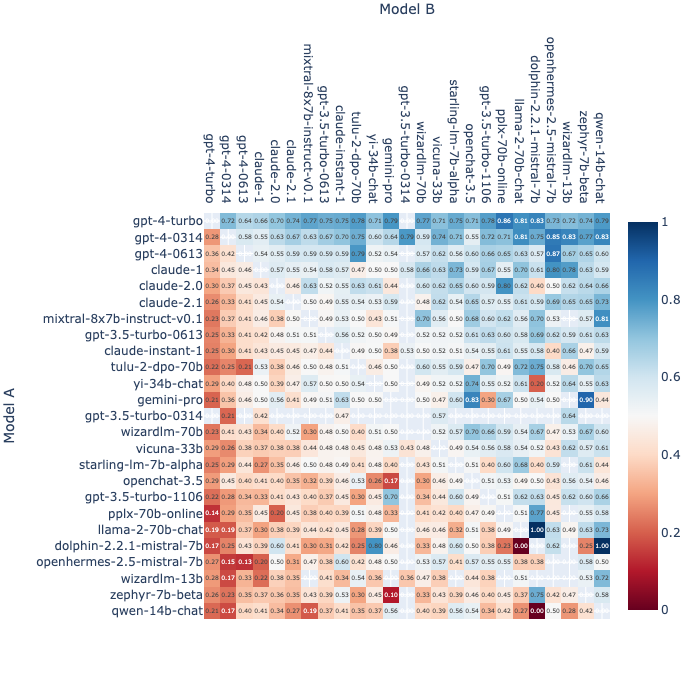
Fraction of Model A Wins for All Non-tied A vs. B Battles (2023-12-16)
Highest to lowest ranking of models goes from top to bottom

Bootstrap of MLE Elo Estimates (1000 Rounds of Random Sampling) (2023-12-16)
This resolves to "YES" if some version of Google's Gemini Ultra (if there are multiple versions) has a higher Elo rating than any OpenAI GPT-4 model on the public leaderboard at any point by April 30th 2024 (23:59 PDT). Note, this is only comparing any GPT-4 model and not necessarily the highest rank or most recent model.
This resolves "NO" if Google's Gemini Ultra appears on the leaderboard but does not ever score a higher Elo rating than an OpenAI GPT-4 model by April 30th 2024 (23:59 PDT).
This will resolve "N/A" if any of the following occurs:
The "Chatbot Arena Leaderboard" on HuggingFace (via this link: https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard) is no longer publicly accessible before the April 30th 2024 deadline.
Google's Gemini Ultra never appears on the leaderboard before the April 30th 2024 deadline.
There are no longer any OpenAI GPT-4 models on the leaderboard before the April 30th deadline and Gemini Ultra has not received a rating (while the GPT-4 models were still on the board).
There might be other edge cases that I might not have thought of but hopefully that covers any that are likely to occur. I may edit/clarify the description if there are new developments or suggestions by others.
The spirit of this is to have a public evaluation metric to compare Google's Gemini Ultra model versus one of the most capable models there is today (OpenAI's GPT-4 model).
Related Markets
The market below proposes the same question as the one listed above but resolves on after April 30th 2024 instead of the end of 2024 and only includes Gemini Ultra (not future Gemini models).
Note this was also created by me
Similar to this market but asks about any model (from OpenAI, Google, etc.) that specifically beats the current (2023-12-20) version of GPT-4-Turbo:
Note this was also created by me
 1,000
1,000People are also trading
Announcement of "Gemini 1.5" model with up to a 1M context: https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/
Wanted to put some quick clarifications in a comment:
This market resolves "YES" if a Gemini Ultra model surpasses any GPT-4 model (not necessarily the most recent or best) at any point of time before the deadline, no matter how brief.
This market resolves "N/A" if Gemini Ultra never shows up on the leaderboard before the deadline.
I started working at Google in Jan 2024 (before creating this market) but won't be using any non-public information as part of this market (resolution or otherwise). I also won't be betting in this market (I sold my shares that I did have and used that to subsidize the market).
These should already be present in the description but after the resolution to the related market for any Gemini model. I also updated the question to say "... an OpenAI's GPT-4 model..." to make it slightly clearer.
But seriously, you should probably read the description before making any bets ;)
@VictorsOtherVector dislike.
"The spirit of this is to have a public evaluation metric to compare Google's Gemini Ultra model versus one of the most capable models there is today (OpenAI's GPT-4 model)."
By comparing Gemini to the worst version of GPT-4 apparently
I'm going to be selling my 74 "YES" shares (spent Ṁ50) now because I don't want to make it seem like I have stake in this resolution. I created this market when I was still decently new to Manifold and didn't really consider what that meant. This was also before I started working in ML at Google (just this started this month) so I'll make sure to add a quick disclaimer on that on my markets/questions. I don't plan to trade on any other markets where I might have "insider info".
I believe I can add liquidity to this market. I'll take all the payout from the sell (should be Ṁ58) and use that to subsidize this market (once I figure out how to do that 😅)
> EDIT: It ended up being Ṁ58 not Ṁ54 between the time of me writing the comment & selling my shares. I've subsidized this market with that amount.
@HenriThunberg I guess you mean a NO resolution could be: (i) Ultra doesn't come out, (ii) Ultra comes out but isn't on the leaderboard, (iii) Ultra is on the leaderboard but lower than every version of GPT-4.
I think (iii) is quite unlikely but don't have a strong view between (i) and (ii), conditional on NO.
More broadly, that spike in Bard (Gemini Pro) is quite surprising, but I think there's a good chance it's a fluke because of the low sample size, and I find it suspicious that the leaderboard has such narrow confidence intervals given how much movement there is and that Gemini's are narrower despite only ~3000 and ~6000 samples—but I haven't been through their calculations.
@HenriThunberg I also think this bet is pretty uncorrelated with my other bets, and I think the market prices on Manifold in areas where I have strong views are relatively good at the moment, so I'm happy taking a large bet on small mispricings, especially ones that are likely to move a lot soon.
@HenriThunberg It's in the description that if Gemini Ultra doesn't appear in the leaderboard (not released) by the deadline, the market will resolve to "N/A" (not "NO" or "YES"). Hopefully that clears things up!
@Jacy On point (i), just clarifying again that if a version of Gemini Ultra never appears on the leaderboard, it will resolve to "N/A". It's been in the description since the market creation but I might make it more prominent so it's obvious to traders.
And addressing your point about low sample size, I think I might consider having a minimum sample size. Frankly, this result by Gemini Pro (Bard) surprised me at how sudden it was; I actually checked the board manually and I don't recall seeing such an ELO score for the model. I think it's not unreasonable that with 3000+ samples that the CI being relatively narrow if the responses are relatively consistent. (See @HenriThunberg comment on the related market.)
On Gemini Ultra, I expect that when/if Ultra drops, the sample size will be relatively small at first before leveling out. This could mean that the score technically resolves the market (in the way it's written right now). I'm considering including part of the description of resolving this model that the Gemini Ultra model must have at least some number of samples on the leaderboard, must be "released" for a period of time before comparing scores, and/or the CI being narrow enough to a GPT-4 score to be relatively confident that Ultra is "better".
Definitely open to ideas! I'll make sure to update the description if I implement any other condition for market resolution.
@VictorsOtherVector that's too bad. I didn't guess that there would be a criterion that is inconsistent with the title of the market.
@Jacy did you mean the conditions about the sample size?
After what I saw in the related market (now resolved), I think the fairest thing is to not change anything already spelled out in the description.
So if a Gemini Ultra model scores any GPT-4 model at any point before May 1st, then the market resolves "YES". And to be clear, "N/A" will resolve if the Gemini Ultra never appears on the arena's leaderboard before the deadline (as stated earlier in the description).
@VictorsOtherVector i was hesitant to bet until i saw the N/A criteria - it makes this almost a safe bet
@Soli I put the N/A criteria early on since I wanted the market to reflect what people thought of how well Gemini Ultra would be in comparison to GPT-4 over whether when it gets released
But now with a Gemini Pro version (Bard) beating out a couple of the GPT-4 versions, it does seem like a pretty safe bet that Gemini Ultra will at least compare similar to this "Bard" version on the board right now
NVM, I guess this market is only Gemini Ultra.
@HenriThunberg you're right that the Gemini Pro result doesn't resolve the market since this market is only for Gemini Ultra. But interesting/promising since Ultra in theory should be better than Pro.