Question is about any current or future openAI models vs any competitor models.
If a language model exists that is undoubtedly the most accurate, reliable, capable, and powerful, that model will win. If there is dispute as to which is more powerful, a significant popularity/accessibility advantage will decide the winner. There must be public access for it to be eligible.
See previous market for more insight into my resolution plan: /Gen/will-there-be-an-ai-language-model
2024 recap: capabilities were "similar". Both Google and openAI models tied for first place on LLM Arena. OpenAI won because of their popularity/market dominance.
Update 2025-11-27 (PST) (AI summary of creator comment): Creator will not resolve based on current Gemini 3 lead alone. Will wait until end of year to allow for:
Potential new OpenAI model releases
Further discussion on whether the lead is "strong enough"
Assessment of whether there is dispute about which model is more powerful
Creator leans toward YES if OpenAI releases no new models by end of year.
Update 2025-11-27 (PST) (AI summary of creator comment): Creator will not resolve early despite Gemini 3.0's current lead. The bar for early resolution is higher than the bar for determining a winner at end-of-year assessment. Creator still leans YES but will wait before resolving.
Update 2025-12-06 (PST) (AI summary of creator comment): Creator distinguishes between early resolution criteria vs end-of-year resolution criteria:
Early resolution requires a model that is so obviously better it takes a huge chunk of market share from ChatGPT (which still has ~80% market share)
End-of-year resolution (Dec 31) will be based on whatever is the best model, with popularity only acting as a tie-breaker rather than a necessary component
Creator acknowledges Gemini/Claude dominate ChatGPT for top-end use, but notes most people either don't know or don't care that they are better.
Update 2025-12-08 (PST) (AI summary of creator comment): Title updated to reflect end-of-year resolution: "At the end of 2025"
Current assessment: Creator believes Gemini and Claude are sufficiently ahead of ChatGPT based on all metrics.
Resolution plan:
Market will resolve YES unless OpenAI releases a new model that top scores before year end
Not resolving early to give OpenAI time to release a potential new model
Market is meant to measure if OpenAI has been "strongly surpassed" - would be inappropriate to resolve YES if OpenAI releases a superior model (e.g., GPT-6) shortly after, as that would indicate they were only "beat to release" rather than truly surpassed
Evidence considered: Benchmarks, stock market activity, and OpenAI's "code red" all indicate OpenAI knows they are no longer the leader
Update 2025-12-08 (PST) (AI summary of creator comment): Creator clarifies the "strongly surpassed" criterion:
Market will resolve YES unless OpenAI releases a new public model before year-end that demonstrates they were never really "strongly surpassed"
If OpenAI was merely "beat to release" but maintained their lead behind the scenes, this would resolve NO
There is no specific metric (absolute or relative) for determining "strongly surpassed"
The current lead by competitors (Gemini/Claude) is sufficient to resolve YES if OpenAI cannot produce evidence of having something better in development
Example: If a competitor releases something only 0.1% better and OpenAI releases a superior model shortly after, OpenAI was never truly "strongly surpassed" - they were just beat to release
Update 2025-12-11 (PST) (AI summary of creator comment): For OpenAI's o5.2 (or any new OpenAI model) to affect resolution:
Must be publicly released
Must be independently tested/scored
Must be at least top scoring to show OpenAI wasn't strongly surpassed
If new OpenAI model is only barely best in class, resolution may be more complicated. Otherwise, market resolves YES if these conditions aren't met.
Update 2025-12-11 (PST) (AI summary of creator comment): Creator clarifies how GPT-5.2 (or any new OpenAI model) will affect resolution:
Since Gemini 3.0 has been out for a while and 5.2 is a "catch up model," if Gemini is ahead on benchmarks, this shows Gemini strongly surpassed OpenAI when it was released
If Google releases an update same day that beats GPT-5.2, that would also count
At year end, if there is a clear non-OpenAI leader, market resolves YES
If GPT-5.2 is a really close number 1 model where nobody can determine which is better, creator will probably still resolve YES
Creator notes the "strongly surpassed" language is meant to avoid situations where OpenAI has achieved AGI/ASI but loses due to release schedules. Since OpenAI has shown signs they're worried (code red, etc.), if the new model isn't a top scorer, they know OpenAI was passed.
Update 2025-12-11 (PST) (AI summary of creator comment): Creator clarifies the "strongly surpassed" criterion:
OpenAI must prove they weren't surpassed behind the scenes (i.e., their unreleased models are better than competitors' new releases)
If OpenAI releases a new model that isn't a top scorer, this proves they were surpassed
The "strongly" qualifier means definitely knowing OpenAI was passed, not just tied for first or ahead behind the scenes but withholding for a big release
Last year resolved in OpenAI's favor despite Claude having a few point lead because OpenAI hadn't released in a while
This time there will be a clear picture of OpenAI's best most recent capabilities - if it's not top tier, they were clearly surpassed
Update 2025-12-11 (PST) (AI summary of creator comment): Creator clarifies evaluation approach for GPT-5.2 (or any new OpenAI model):
Will grade OpenAI harder since they have the most recent release and most time to tune
Evaluation is holistic but only on language capabilities (no image/video/etc.)
No specific weights to any particular benchmarks
If experts/industry leaders consensus says GPT-5.2 is inferior to Gemini/Claude, market can resolve YES even if GPT-5.2 is comparable on lmarena
Update 2025-12-12 (PST) (AI summary of creator comment): Creator clarifies that GPT-5.2's higher rank on WebDev alone is not sufficient to resolve NO. The model is not #1 on the relevant leaderboard at this time.
Update 2025-12-31 (PST) (AI summary of creator comment): Creator is waiting to see where GPT-5.2 appears on benchmarks before resolving. Creator's personal assessment is that GPT-5.2 was a disappointment, but is waiting for benchmark evidence to confirm before resolution.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ5,159 | |
| 2 | Ṁ5,115 | |
| 3 | Ṁ4,920 | |
| 4 | Ṁ3,345 | |
| 5 | Ṁ3,246 |
People are also trading
GPT5.2 is a real stinker, I think it's pretty clear that openAI were definitely surpassed, not just transiently, but even with the opportunity to do a counter-release with extra time, they are behind competitors.
Into 2026, I'm more focused on market share! (less vibesy) - check out the continuations
Happy New Year, @Gen ! I wish you having a wonderful start to the 2026 year. Could you please let know upfront if this will be resolved quickly and positively? Truly believe in you and appreciate all your hard work. Thank you for your work!
@1bets mostly waiting to see where GPT5.2 appears on benchmarks. My personal vibe is that it was a total disappointment - waiting for the evidence!
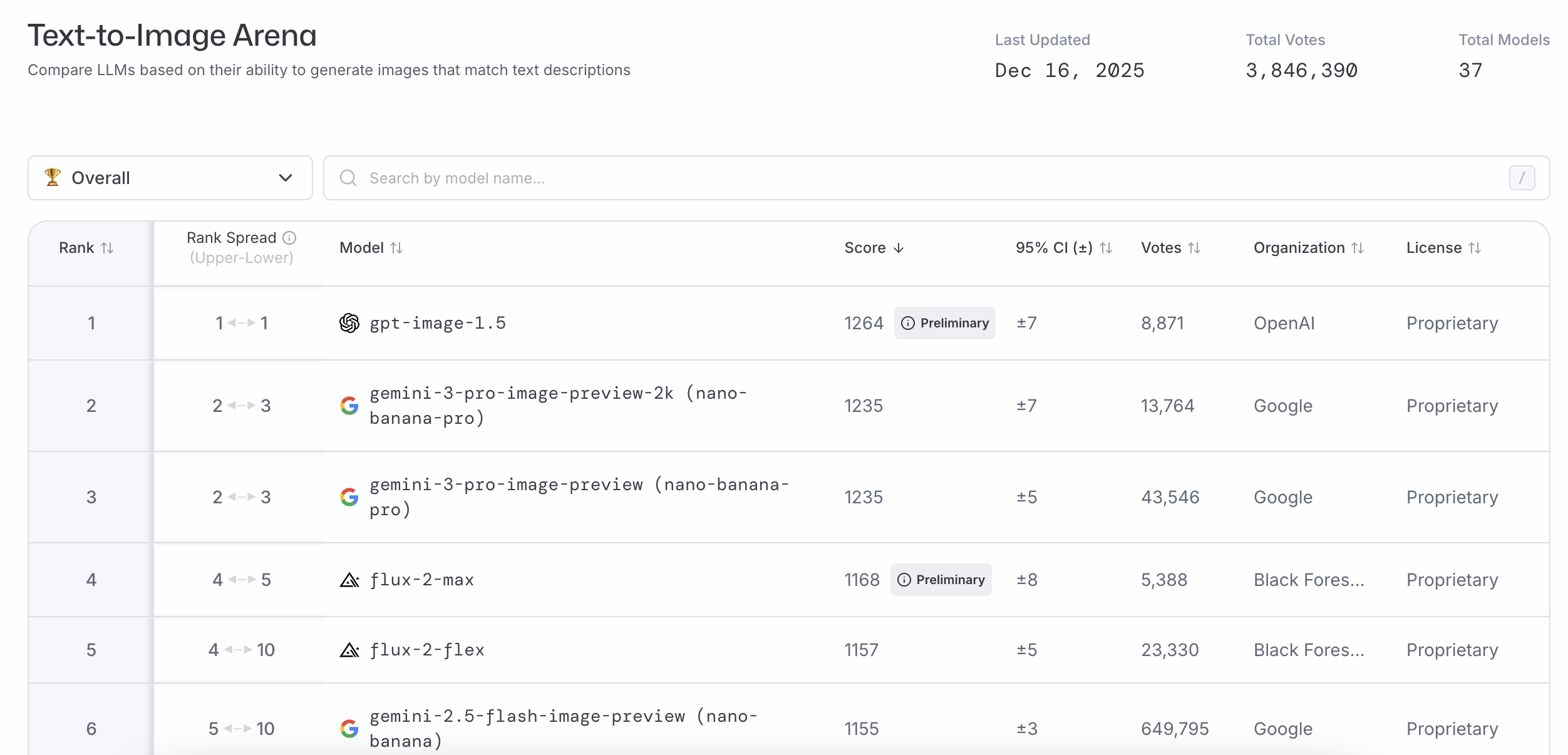
@Gen overall - text - number 14, GPT5.2 appears bellow gpt 5.1 : https://lmarena.ai/leaderboard/text
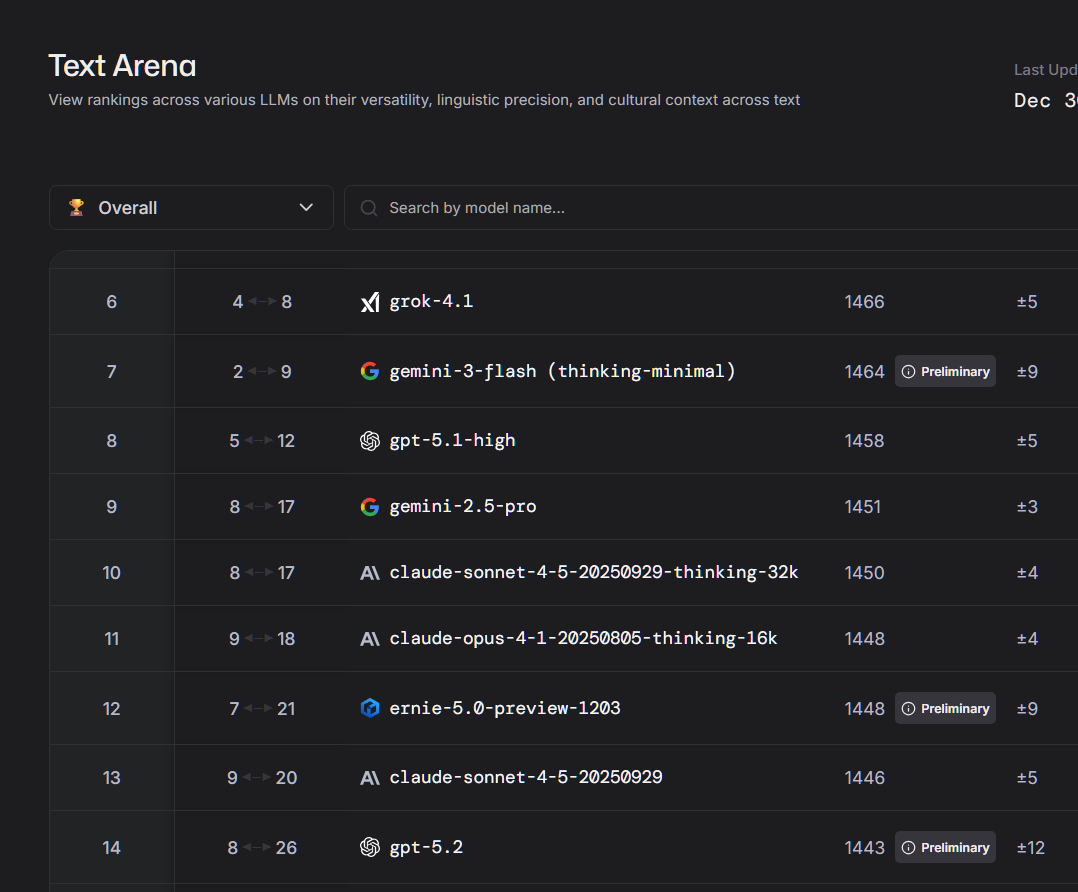
On the lmarena.ai 'Overall - No Style Control' leaderboard, GPT-5.2 (ranked #24) places significantly lower than Gemini 3.0 (ranked #1). https://lmarena.ai/leaderboard/text/overall-no-style-control
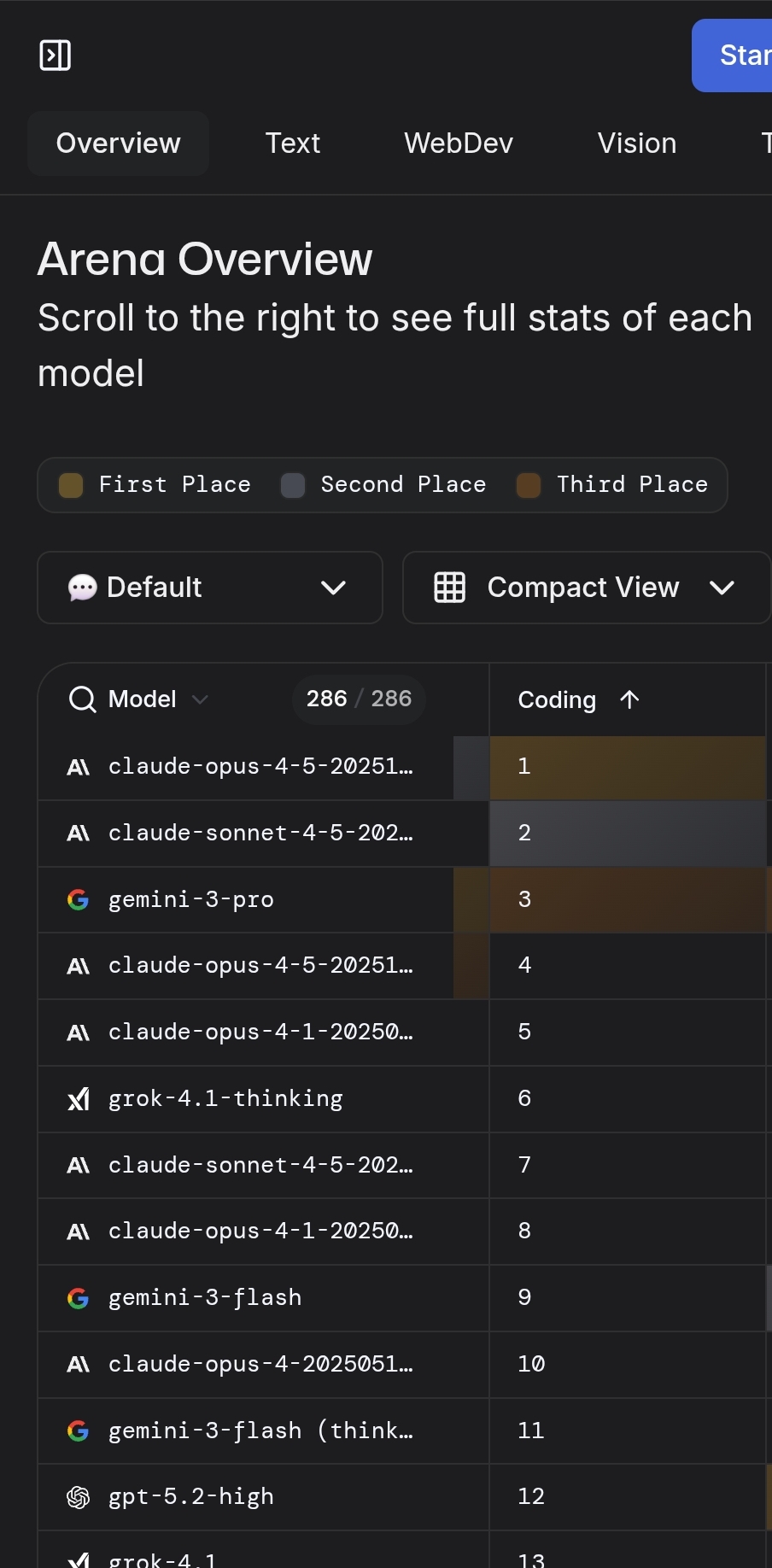
language model - not text-to-image
@Bayesian after using it for 30 minutes I'm strongly convinced nano banana pro is a much smarter model and OpenAI just ramped up the cheap aesthetics for elomaxxing
@Bayesian nano banana pro:

gpt image 1.5

Prompt:
In the image, a massive dragon is perched atop a small, two-story house. The creature's powerful, scaled body is coiled around the roof, with its front legs dug into the shingles for support. Its wings are folded against its body, and its tail is wrapped around the chimney. The dragon's fierce eyes are gazing out at the viewer, and its sharp teeth are bared in a menacing snarl. The house beneath it looks old and worn, with peeling paint and a sagging roof. The image exudes a sense of danger and magic, as the majestic, mythical beast towers over the humble human dwelling.
Nano banana pro:

gpt image 1.5

Prompt:
A detailed oil painting of an old sea captain, steering his ship through a storm. Saltwater is splashing against his weathered face, determination in his eyes. Twirling malevolent clouds are seen above and stern waves threaten to submerge the ship while seagulls dive and twirl through the chaotic landscape. Thunder and lights embark in the distance, illuminating the scene with an eerie green glow.
@Bayesian like for this to be true it would mean OpenAI goes all in on making a dedicated app and social network to capture the short form AI video market and then ... just gives up somewhere in 2026