The market will resolve positively when a LLM model appears which fulfils the following conditions:
It is publicly available to be downloaded (for free or for a fee <$1000).
It can be run on a consumer PC with one CPU and at most one consumer GPU. (It's ok if it requires a high-end model like RTX 5090.)
It achieves the average inference speed of at least 60 words per minute on the high-end consumer hardware.
It is ranked on par with GPT-4 models on Chatbot Arena Leaderboard. It should beat at least one version of GPT-4 models presented in the ranking. If Chatbot Arena no longer exists or doesn't list the model in question, another similar ranking can be used.
I do not bet on my own questions.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ270 | |
| 2 | Ṁ241 | |
| 3 | Ṁ204 | |
| 4 | Ṁ73 | |
| 5 | Ṁ63 |
People are also trading
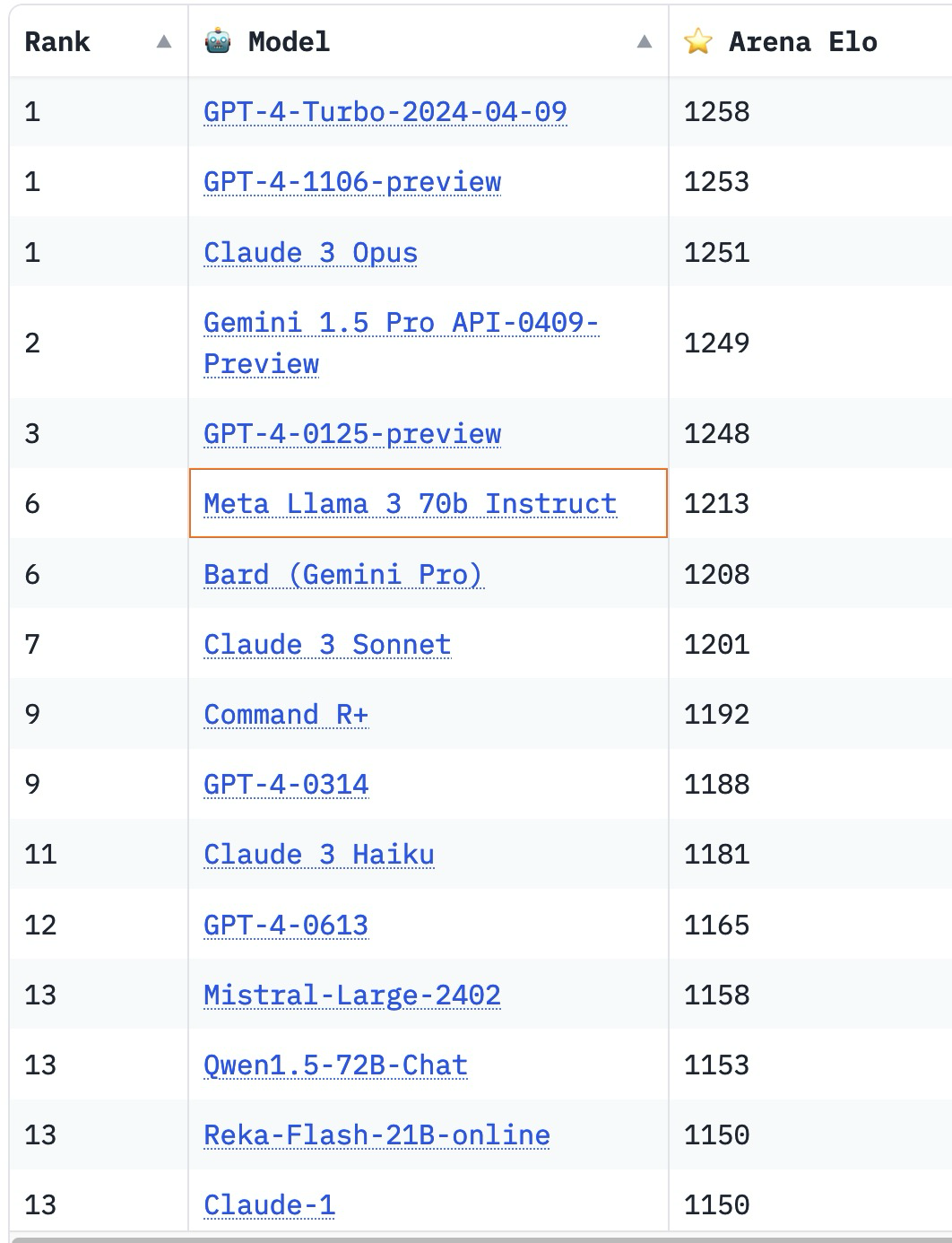
@traders s Resolved by running Gemma-2-9B-it on a PC with RTX 4090. This model is currently in the 20th place on LMSYS Chatbot Arena Leaderboard, ahead of GPT-4-0613.
I came around to play a little bit with the top models from Hugging Face. Llama-3-8b-Instruct runs perfectly on an RTX 4090 and is just 8 points behind the weakest GPT 4 model.
The same model completely stalls on a M1 Pro Macbook with 32 GiB of memory, so I'm expecting that Llama-3-70b-Instruct will not work reliably on a Mac Studio even with 192 GiB of memory.
Looks like this should resolve to "Before 2025"? We now have reports of >1 word/second on a desktop computer.

@nsokolsky I would wait for some proper benchmarks. These are quantized models, I'd assume they have somewhat worse performance.
@Bair https://arxiv.org/pdf/2404.14047.pdf analyzed the quantized models performance but didn't benchmark against GPT-4.
@nsokolsky @Bair The original Llama-3-70B-Instruct is bfloat16, 140 GB in total. I am not certain how much additional memory you need to actually run inference, but I think it should be about an order of magnitude less than the total size of the weights, so it theoretically should fit in a Mac Studio with 192 GB of unified memory.
I'm not sure whether running the quantized model is faster or slower than non-quantized model, but running 16-bit model shouldn't be more than 4x time slower than 4-bit model provided that full weights fit into memory.
So it seems plausible to me that if you can run Q4 at 14 tokens/sec then you should be able to run non-quantized model at >= 4 tokens/sec.
But, of course, I'll wait until some definite reports before resolving this.
@Sss19971997 I saw a short video on Twitter of Llama 3 running on an M1 Max and it seems to be fast enough, but it was difficult to tell. It might also depend on the size of the context, so that only the first few tokens are generated with a usable speed.
@traders I don't have a Mac with enough memory, so I can't try it myself. If anyone has one, or knows some more detailed article or video, I would appreciate a link.
Llama 3 fulfills the conditions for being on par with GPT 4 models according to LMSYS Leaderboardd.
@OlegEterevsky Can we look into some clarification on criterion #4? I hadn't seen it when betting (which is definitely my bad!), and I think it's possibly misleading with regard to the title.
GPT-4-0314 and 0613 are already at ELO 1189 and 1163 and place 7/10 in the ranking, respectively. My assumption was that it would be enough to be better than these two, not having to beat GPT-4-Turbo-2024... or GPT-4-1106-preview. I personally think that's more representative of being "a GPT-4 class model", than having to beat the SOTA.
Also, ELO scores for current GPT-4 models are likely to decline further even if they don't get worse, as new better models are released and beat GPT-4 more often (relative to now). This would happen even if quality of GPT-4 stays the exact same for the rest of the year.
@HenriThunberg Good point, I'll change the criterion #4 to a requirement that the model beats at least some version of GPT-4.
@Sss19971997 60 words per minute, right. The GPU in Apple Silicon is not particularly powerful. I haven't personally tested the GPU in M3 processors, but my guess would be that it will be way slower than a token per second.
I'll be happy to be proven wrong.