
This market matches Computer Use: OSWorld from the AI 2025 Forecasting Survey by AI Digest.
The best performance by an AI system on OSWorld across any method as of December 31st 2025.

Resolution criteria
This resolution will use AI Digest as its source. If the number reported is exactly on the boundary (eg. 60%) then the higher choice will be used (ie. 60% - 70%).
Which AI systems count?
Any AI system counts if it operates within realistic deployment constraints and doesn't have unfair advantages over human baseliners.
Tool assistance, scaffolding, and any other inference-time elicitation techniques are permitted as long as:
There is no systematic unfair advantage over the humans described in the Human Performance section (e.g. AI systems are allowed to have multiple outputs autograded while humans aren't, or AI systems have access to the internet when humans don't).
Having the AI system complete the task does not use more compute than could be purchased with the wages needed to pay a human to complete the same task to the same level
The PASS@k elicitation technique (which automatically grades and chooses the best out of k outputs from a model) is a common example that we do not accept on this benchmark because the OSWorld paper implies that human evaluators where given one-shot attempts without access to the scoring function. PASS@k would therefore consitute an unfair advantage, as human evaluators would likely have done better if allowed multiple attempts.
If there is evidence of training contamination leading to substantially increased performance, scores will be accordingly adjusted or disqualified.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ5,646 | |
| 2 | Ṁ2,703 | |
| 3 | Ṁ1,906 | |
| 4 | Ṁ1,425 | |
| 5 | Ṁ883 |
People are also trading
@Manifold @mods resolves 72.5% according to official AI digest results: https://ai2025.org/?utm_source=newsletter
@Bayesian I had misread the criteria and comments, its an AI system not model + OS-world verified counts

@Bayesian also I double checked if N=10, Max Step=100, Runs=1 violates the pass@k metric and it doesn't.
pass@k under Chen et al. is defined as
Key properties of PASS@k:
k independent samples
Each sample is a full solution attempt.Binary correctness function
There exists a functioncorrect(x)∈{0,1}\text{correct}(x) \in \{0,1\}correct(x)∈{0,1}
Oracle-style evaluation
You can check correctness after the fact without affecting generation.Selection across samples
The metric explicitly counts success if any of the k samples succeed:PASS@k=P(maxi=1kcorrect(xi)=1)\text{PASS@k} = \mathbb{P}\left(\max_{i=1}^k \text{correct}(x_i) = 1\right)PASS@k=P(i=1maxkcorrect(xi)=1)
The OSWorld agents have a shared state and shared plan so not indepndent samples. Branches occurs mid-trajectory so not full task solution, only one trajectory completes, and there is no correctness function.
Its functionally the same as a human pass@1 but a human is allowed to think about trajectories in their mind, some of which may or may not be wrong.
@Bayesian they def changed it recently, kudos to jim for changing the odds and making me investigate lol
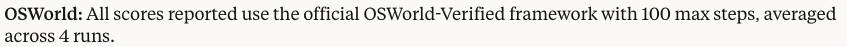
Comparing OSWorld original vs Verified:
Claude 3.7 Sonnet got 26 to 28% on OSWorld original with 50-100 steps. On Verified, this improves to 35.6-35.8%.
On OSWorld original, OpenAI reported that the 4o-based CUA got 32.6% after 50 steps and 36% after 100 steps in the original. But on Verified its score actually declines to ~31% with either 50 or 100 steps.
There might be more overlap in the leaderboards, I didn't check closely.
CoAct-1 claims 60.76%:
- https://www.marktechpost.com/2025/08/07/meet-coact-1-a-novel-multi-agent-system-that-synergistically-combines-gui-based-control-with-direct-programmatic-execution/
- https://arxiv.org/abs/2508.03923
It seems legit, although they do not report the $ cost, but I believe it should qualify.
This paper also mentions 3 other systems that achieve 50+, so even if CoAct-1 is somehow fake or does not qualify, I think it's very likely that qualifying 50+ is already achieved
@EliLifland what do you think about counting OSWorld-Verified results? I think they shouldn't count, since they're not measured to the same standard as all OSWorld scores to date.
@JoshYou Hm, it's a shame that they're no long reporting original OSWorld scores. Yes, should be resolved based on the original as best we can estimate, I'll probably email the OSWorld authors and if they don't provide a score for the original benchmark then I'll either resolve to my best guess estimate of the original benchmark score or N/A.
@EliLifland you can still see historic results for the original benchmark at "For self-reported results and progress trends across different modalities, click here." But I'm not sure if they will host any new scores going forward, and maybe no one will bother running evals with the old version at all.
By comparison, people run SWE-bench and SWE-bench lite (non-verified) somewhat often on new models and scaffolds. But SWE-bench was a much more popular benchmark than OSWorld to begin with.
OpenAI's new Operator gets 42.9%, but they say they found issues with the autograder and the actual score should be much higher. Wonder what the deal is with that...
https://help.openai.com/en/articles/10561834-operator-release-notes
The sweepstakes market for this question has been resolved to partial as we are shutting down sweepstakes. Please read the full announcement here. The mana market will continue as usual.
Only markets closing before March 3rd will be left open for trading and will be resolved as usual.
Users will be able to cashout or donate their entire sweepcash balance, regardless of whether it has been won in a sweepstakes or not, by March 28th (for amounts above our minimum threshold of $25).