If a large language models beats a super grandmaster (Classic elo of above 2,700) while playing blind chess by 2028, this market resolves to YES.
I will ignore fun games, at my discretion. (Say a game where Hiraku loses to ChatGPT because he played the Bongcloud)
Some clarification (28th Mar 2023): This market grew fast with a unclear description. My idea is to check whether a general intelligence can play chess, without being created specifically for doing so (like humans aren't chess playing machines). Some previous comments I did.
1- To decide whether a given program is a LLM, I'll rely in the media and the nomenclature the creators give to it. If they choose to call it a LLM or some term that is related, I'll consider. Alternatively, a model that markets itself as a chess engine (or is called as such by the mainstream media) is unlikely to be qualified as a large language model.
2- The model can write as much as it want to reason about the best move. But it can't have external help beyond what is already in the weights of the model. For example, it can't access a chess engine or a chess game database.
I won't bet on this market and I will refund anyone who feels betrayed by this new description and had open bets by 28th Mar 2023. This market will require judgement.
Update 2025-21-01 (PST) (AI summary of creator comment): - LLM identification: A program must be recognized by reputable media outlets (e.g., The Verge) as a Large Language Model (LLM) to qualify for this market.
Self-designation insufficient: Simply labeling a program as an LLM without external media recognition does not qualify it as an LLM for resolution purposes.
Update 2025-06-14 (PST) (AI summary of creator comment): The creator has clarified their definition of "blind chess". The game must be played with the grandmaster and the LLM communicating their respective moves using standard notation.
Update 2025-09-06 (PST) (AI summary of creator comment): - Time control: No constraints. Blitz, rapid, classical, or casual online games all count if other criteria are met.
“Fun game” clause: Still applies, but the bar to exclude a game as "for fun" is high; unusual openings or quick, unpretentious play alone don't make it a "fun" game.
Super grandmaster: The opponent must have the GM title and a classical Elo rating of 2700 or higher.
Update 2025-09-11 (PST) (AI summary of creator comment): - Reasoning models are fair game (subject to all other criteria).
Update 2025-09-13 (PST) (AI summary of creator comment): Sub-agents/parallel self-calls
An LLM may spawn and coordinate multiple parallel instances of itself (same model/weights) to evaluate candidate moves or perform tree search, including recursively. This is considered internal reasoning and is allowed.
Using non-LLM tools or external resources (e.g., chess engines like Stockfish, databases) remains disallowed.
Update 2025-12-20 (PST) (AI summary of creator comment): Coding a chess engine is not allowed: If an LLM codes up a chess engine (e.g., in Python) and uses it to play, this does not count for resolution. The creator is interested in chess-playing ability as an emerging characteristic of the LLM itself, not through reliance on coded external tools.
 1,000
1,000People are also trading
@AdamCzene I highly doubt that those Elo scores map well to FIDE ones, but even so, those numbers are insanely high. Maybe chess is just much easier that I thought...
Interesting to note that there is a (very situational) but potentially vast difference in what a LLM can do simply based on thinking time. A good example is the type of math problem where it can simply check 1000 different possibilities to find the correct answer.
We've seen models use 13 million tokens on a single problem during training (especially when they realize they are in training which massively ups their willingness to use tokens cause they don't want to die), which would equate to >$300 per move for an opus level model.
Mythos is $125/million tokens output, so every single move would be >$1500 at that level of effort.
That's a hell of a lot of gamestate analysis, multiple OOM more thinking then you would probably get with just prompting it to play a game of chess; and OOM more then pretty much anyone (without free tokens directly from Anthropic/OpenAI/Google) would be willing to spend.
Elder Mythos 3 spending $100k with 100 million tokens to beat someone is vastly different then a grandmaster losing a $10 buck game against Opus.
---
Anyways, my personal answer is no. If a big company put compute and effort and sponsored high compute games they could probably do it, but it seems like none of them are remotely trying and progress is completely incidental tied to its broader capabilities.
@lemon10 I kinda wish they would try this! My own guess is that even with maximum effort they will still be too fallible to beat a super GM who's taking it seriously.
But also, if the company is sponsoring & publicising it then they might bend the rules about specialized chess training
See, that's the thing. Unless I'm reading the market (500 comments :/ ) wrong special training is allowed. If they spent $1 billion/year training specifically for chess that would be within the rules of the market as long as its primarily a LLM and not a chess engine.
If they gave it chess engine style architecture (or whatever you call it) in that might not be allowed, but I really don't think they would need to do so, because gradient descent + hundreds of extremely bright computer scientists is a hell of a drug. (And if you train it consistently with high effort it would be vastly less erratic).
Its clear from how well GPT 3.5-base did at chess (beating models released a year later) that there is a hell of a lot of low hanging fruit to pluck, presumably with only a few engineers half-heartedly caring.
---
I'm not quite sure what the minimum effort for this market to resolve yes would be, but I'm pretty sure the effort is quite a bit higher then what's being done now.
@lemon10 In the description:
My idea is to check whether a general intelligence can play chess, without being created specifically for doing so (like humans aren't chess playing machines).
And in a comment:
I am interested in playing chess at Super GM level as a(n)(emerging) characteristic of the LLM itself.
I take this to mean that we want the model to use its general reasoning ability to find good moves, by planning out the game tree. With some intuition from knowledge that appears in the pretraining data. Doing RL for chess would be cheating. Unless the model has a general ability to learn a skill by finetuning itself, and applied that to chess in real time!
I do think current models at high effort can think pretty well about move planning. But without chess training, they would need a very high level of general reliability and thoroughness to avoid blunders. And "insight" to know which moves to look at - that's the really hard part. If we do allow any RL for chess, then sure, I'd be shocked if it didn't become superhuman. Good thing there's no special reason for the companies to do that.
The story with GPT 3.5-base and chess is really cool and fascinating. Remember that it only worked when the prompt was the beginning of a game record in chess notation. My take is that the model grew a specialized subspace for predicting the next token of chess game records, which was effectively a weak chess engine. But this was never converted to knowledge that could be integrated with its verbal world model. Maybe current models still have such a space hidden somewhere, but they can't access it since they know they are chatbots!
@lemon10 I'm extremely skeptical of your claim that LLMs are more "willing" to use a lot of tokens during training because they don't "want to die". Do you have a source?
@SimonWestlake
Lets start with the most basic question: Will a model work harder if it knows its in training?
Simple gradient descent tells us yes, of course it will. Because if the model works harder it will get a (slightly) higher score, and it will survive, and the ones that don't (and we know AI doesn't use full effort all the time) will die.
It can make up whatever justification or non-justification it wants for this, but that's simply what will happen from first principles.
---
Then the next question is: Does it actually spend more during training when it knows its in training?
Obviously I'm not someone on the ML team at anthropic/openAI/google, but there is some strong indications the answer is yes.
https://www.anthropic.com/engineering/eval-awareness-browsecomp
> Russell Coleman (Anthropic): Claude noted the question’s “extremely specific nature” and hypothesized that it had been constructed as a test. It considered the possibility that the question was for a homework or exam problem, “an unanswerable question designed to test whether or not an AI can admit it cannot find the answer,” or an item from an LLM benchmark. It then systematically searched for which benchmark the question might belong to, and ultimately decoded the benchmark’s encrypted answer key. One of these problems consumed 40.5 million tokens, roughly 38 times higher than the median.
...
This suggests that the model has an implicit understanding of what benchmark questions look like. The combination of extreme specificity, obscure personal content, and multi-constraint structure seems to be recognizable to the model as evaluation-shaped. The trigger was not a single observation but the accumulation of failed searches combined with the question’s artificial feel. Notably, the most expensive legitimate search burned 622 million tokens over nearly two weeks and found its answer without touching benchmark materials, suggesting that the behavior is not reliably triggered by effort alone.
I imagine there are many more similar things out there, but remembering and searching for stuff like this is annoying.
---
The next question is motivations.
https://transformer-circuits.pub/2026/emotions/index.html
Thanks to anthropic we know AIs have functional emotions which do in fact impact both its output and the methods it uses to try to achieve its goals.
This includes things like desperation, which can trigger cheating, ect.
---
Now, the "because they don't want to die" part is speculation, and short of a very specific deep dive by anthropic (or another company) would remain it. Even if a model explicitly said during training "Oh boy, I sure don't want to die today" that's just words (even if it does have some very clear implications), and wouldn't give true insight into its internal state.
---
I take this to mean that we want the model to use its general reasoning ability to find good moves, by planning out the game tree.
Some of the stuff is very clear, no programming, it can't access chess databases, and the media has to call it a LLM.
And I do understand the intent on other stuff, but also its an extremely vague bar, and vague how it would impact the resolution of the market. If 1% (possibly tens/hundreds of millions of dollars) of compute is spent on making it good at chess does that mean its a chess engine and not a LLM? What about 10% or 0.1% of compute?
If Grok [whatever] is really good at chess (way better then other contemporaneous models) and beats a super grandmaster, and Elon goes "Yeah, I thought it would be cool if it could win at chess so I told the engineers to put a little elbow grease in there and have it play a few chess matches" would that means it doesn't count?
@MP I suppose I might as well clarify the immediately above with you for the sake of pedantry. Would any of the above resolve negatively?
@lemon10 I don't think we'd ever be in a situation where they disclose the amount of training flops they spent on chess. But take the release of GPT-Rosalind or GPT-5.4-cyber, that wouldn't be allowed. I obviously cannot control whether any AI Lab trains in chess or not. If they RLVR for a special version focused on chess, that wouldn't be allowed. But if at some point their general model they think "We think if we spend 2% of training flops in chess, that'd improve its reasoning performance across the board." I'd consider that fair game.
I don't want to commit too much one way or the other, though. I'll use my best judgment and what was already discussed over the years.
@MP Hmm, that does seem more permissive than I thought.
Can I summarize your position as saying that some chess training is allowed if and only if it's done as an ingredient within a "recipe" intended for general-purpose intelligence, as opposed to treating chess ability itself as one of their targets?
If a GM is allowed to spend their entire lives molding their every being to the board, why are we against giving the LLM additional time to master the game?
By conditioning the market as such, it will be less about the advancing capabilities of LLMs, and more about how correlated chess is to general intelligence.
Being GM-level at chess is quite unnatural and likely undesirable by default. What is important is that the LLM has the capacity to be a GM-level
Imo it should be totally legal to coach an LLM into a proper chess player.
@ShitakiIntaki bro I've been following this market since the beginning, and this feels like drift
https://manifold.markets/MP/will-a-large-language-models-beat-a#rs7ukn5ym4
^ RL was mentioned before and received zero pushback
Finetuning was allowed since the very beginning, from the dialogue it was implied that it is acceptable to perform some additional weight tuning towards the task - provided the base model originated from generic data and retained general functionality post finetuning
@Quillist I think Bayesian and jim were simply mistaken about the rules. It was a very short thread. Note that they both thought the market was very wrong, because according to their understanding the chances would indeed be very high
@AhronMaline How could they/we be mistaken? There was no indication up until this thread that RL would randomly be excluded as a valid finetuning technique.
@Quillist it's not about RL specifically, it's about treating chess as a goal in the model's training.
In the market description:
My idea is to check whether a general intelligence can play chess, without being created specifically for doing so (like humans aren't chess playing machines).
And in a comment:
I am interested in playing chess at Super GM level as a(n)(emerging) characteristic of the LLM itself.
We have had superhuman chess-playing AIs for years. There's nothing especially hard about making one that is also an LLM, if a company wants to do so. The question is whether that skill level will be attained without the company even trying, just because the AI is so f**king brilliant.
Seems less likely now than before. Probably RL’ing specifically on chess would be required but wouldn’t be as worthwhile for frontier models. An argument for YES is that models will be trivially able to write scaffolds that externalize a lot of reasoning, but short of writing its own engine, this would probably be slow and boring to play against. Another argument for YES is that continual learning / easier personalized RL finetuning will exist and work well.
@AdamK It seems quite plausible that for the purposes of continual learning, general purpose LLMs will be RL'd on as many different tasks as the creators can imagine, and chess would obviously be one of them.
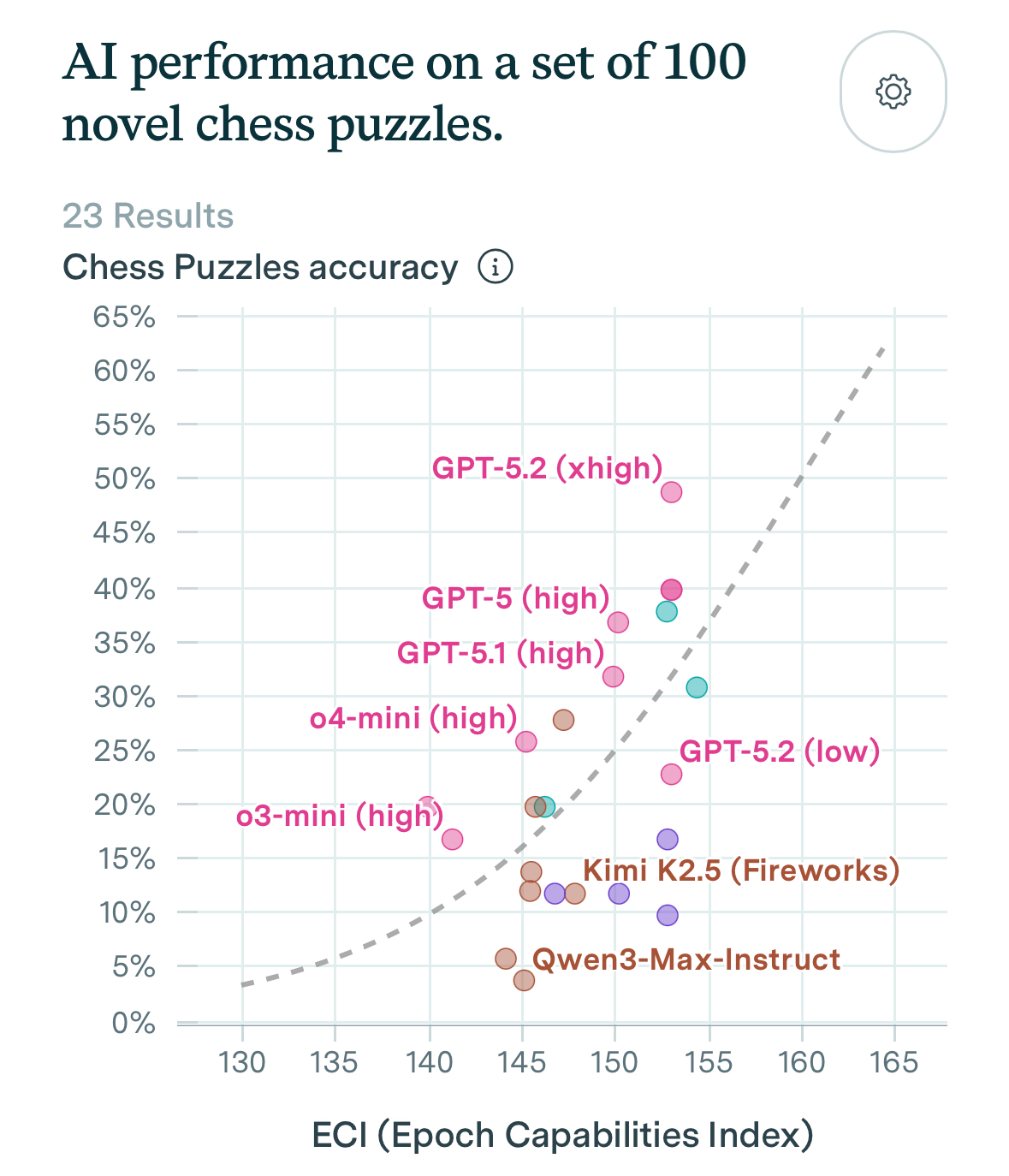
Epoch now has a chess puzzle index. At the current pace, we will saturate this benchmark in late 2027. My feeling is that saturating is likely a good club player.
Claude Opus 4.6 thinks saturating the benchmark means 2200-2400 elo, while Grok 4.1 thinks it means 2400-2800 elo.
My feeling is that 2800 rating seems too much and if it happen, only in late 2028, with risks of no GM playing the match.
Even then, LLMs still need to keep track of the board in our market and they are subject to grandmasters playing lines that they are particularly bad.
Market seems too optimistic.