
In total output, real-world use, plus prestige (open labs attracting the best talent)
PROB resolution--2022 would have resolved ~70-80% YES
Based on informed (and uninformed) comments, search trends, random Twitter hive minding, etc.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ1,696 | |
| 2 | Ṁ811 | |
| 3 | Ṁ425 | |
| 4 | Ṁ354 | |
| 5 | Ṁ219 |
People are also trading
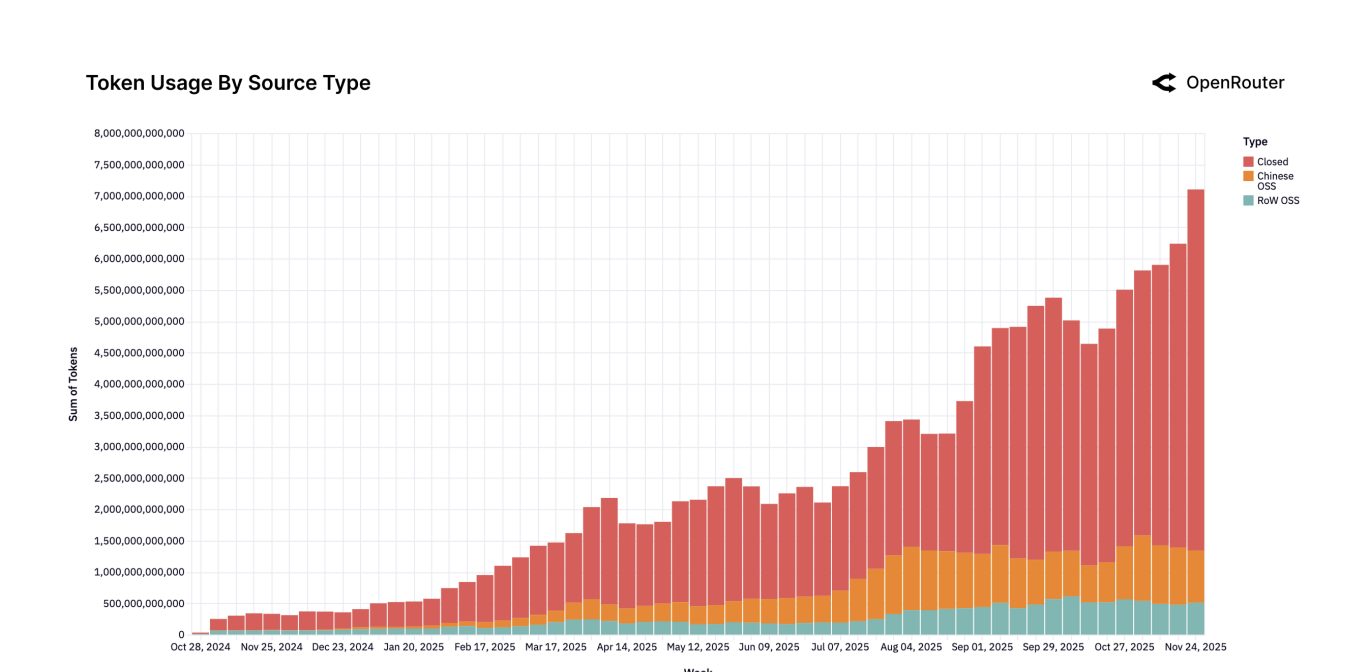
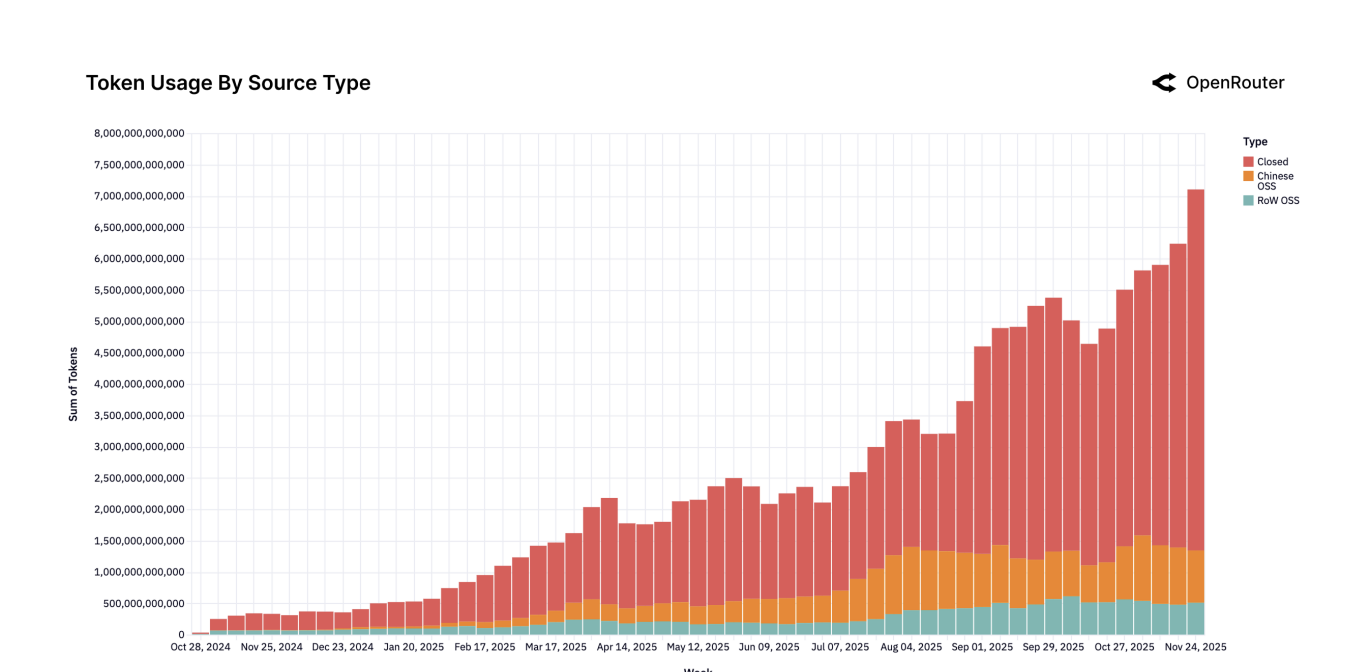
@traders Thinking about resolving this to (30% of token output as measured via openrouter - 5pp penalty for lower prestige) = 25% total. Anyone have any other good sources of info related to token output from OSS vs closed models? Going based off this info: https://openrouter.ai/assets/State-of-AI.pdf
@ian Feels a little arbitrary, but on the other hand, also feels about right both on vibes (some of the most notable releases of 2025 were the near-SOTA open models, including the whole litany of extremely capable small models from Qwen) and conceptually. Open models represent the floor of the AI capability accessible for research and unlimited personal use, and the floor being this close to the ceiling and continuously inching ever closer is a rather new development in the time spent since LLMs became a commercial product. So I feel like it's totally fair not to resolve it to zero with that in mind (even though I hold "no" shares in this market).
@moozooh OpenRouter is not an unbiased sample of token usage. Big closed source companies, like OpenAI, Anthropic, and Google to name a few, serve a very small fraction of their tokens through OpenRouter.
Sure, you can make the case that this market should resolve based on token usage. But looking solely at OpenRouter to make this estimate is absurd. OpenRouter served 136.78T tokens in 2025.
Numbers I've found claimed for closed source companies:
OpenAI: averaged 8.6T tokens per day in 2025, 3.15 Q for the API alone
Google: nearly 1 Q tokens in a single month (in June).
ByteDance: 30T/day in September
Others: unknown
Per previous logic for prestige penalty, this market should resolve to roughly -2%. 😛
OpenAI 6B tokens/min: https://techcrunch.com/2025/10/06/sam-altman-says-chatgpt-has-hit-800m-weekly-active-users/ and https://openai.com/devday/
Google 1Q tokens in June: https://www.datacenterdynamics.com/en/news/google-processed-nearly-one-quadrillion-tokens-in-june-deepminds-demis-hassabis-says/ and https://the-decoder.com/google-processed-nearly-one-quadrillion-tokens-in-june-doubling-mays-total/
Doubao 12.7T/day->30T/day: https://www.scmp.com/business/article/3329430/bytedances-doubao-doubles-token-use-six-months-chinas-ai-boom-gathers-pace
https://openrouter.ai/assets/State-of-AI.pdf
Yes, if and only if the question is interpreted as “winning on token throughput” rather than prestige, frontier benchmarks, or enterprise revenue.
On that axis, the answer is already yes. Measured inference telemetry shows open weight models processing a very large and growing share of global tokens, concentrated in exactly the workloads that maximize volume: long context programming, iterative agentic loops, and high frequency interactive use. Those workloads dominate total tokens, not dollars, and open models are structurally advantaged there due to cost, deployability, and integration flexibility .
What is not a yes is talent gravity, brand perception, or “who is the frontier lab.” Those remain qualitative and narrative driven. But tokens are behavior, not opinion.
So the precise conclusion is:
Open source has already won, or is at least co dominant in, token throughput, which is the only axis that is cleanly quantifiable today .
Under that definition, this is no longer a forecast. It is an observed state.
@Kearm20 why are you focusing on token throughput? The creator lists total output, real-world use, plus prestige.
@mods I have 20k open interest in this market and can't really decide it (it's a complex possible PROB resolution) we are discussing it on the New Year Resolutions call, but probably someone else will need to pull the trigger
@Gen I think they don't have much prestige, and their share of token output is a minority, we could resolve to prob approx. according to their output minus a penalty for lower prestige?
@ian I don’t mind, I made this bet because gigacasting was way way wayyyy too favourable towards open source at the time.
Deepseek is good, but I’m not expecting a very high prob. I’m fine with you throwing a number out there, I won’t dispute it
@Gen They have 30% of token output measured via openrouter, and a penalty of 5pp for lower prestige, so maybe resolve to 25%?
@shankypanky oh oops I think @BionicD0LPH1N raised some good points here.
I think I'll resolve to 5%
I can imagine it in the image generation space, since open models like Stable Diffusion have a level of customization that proprietary ones lack, and in this space it matters a lot. Even as Stability AI fumbles, there is a large amount of open-source efforts in this space picking up the slack.
I have a hard time seeing this happen to LLMs due to both the prohibitive cost of training them and the proprietary LLMs being "good enough" for consumer use cases.


