Based on this tweet from Spencer Schiff:
https://x.com/spencerkschiff/status/1910106368205336769?s=46&t=62uT9IruD1-YP-SHFkVEPg
and the market by @bens:
/bens/will-a-mainstream-ai-model-pass-the
Resolves YES if a mainstream AI model (Currently, only Google, OpenAI, Anthropic, xAI, DeepSeek and Meta count, but if some other lab becomes similarly mainstream they will count as well) can repeatedly solve this benchmark, using this image and other similar ones I draw. I will be the judge of this.
“Solving the benchmark” means being able to match the names to the colors of the stick figures, repeatedly and with simple prompts.
I will pay for api credits if needed (limit: ~$20 per model). I will prompt each AI model a few times (6) and see if it succeeds at least 4 times out of 6, but I won't be running the same model multiple times and use some kind of cons@32 technique to aggregate multiple attempts.
The image for reference in case the tweet is deleted:
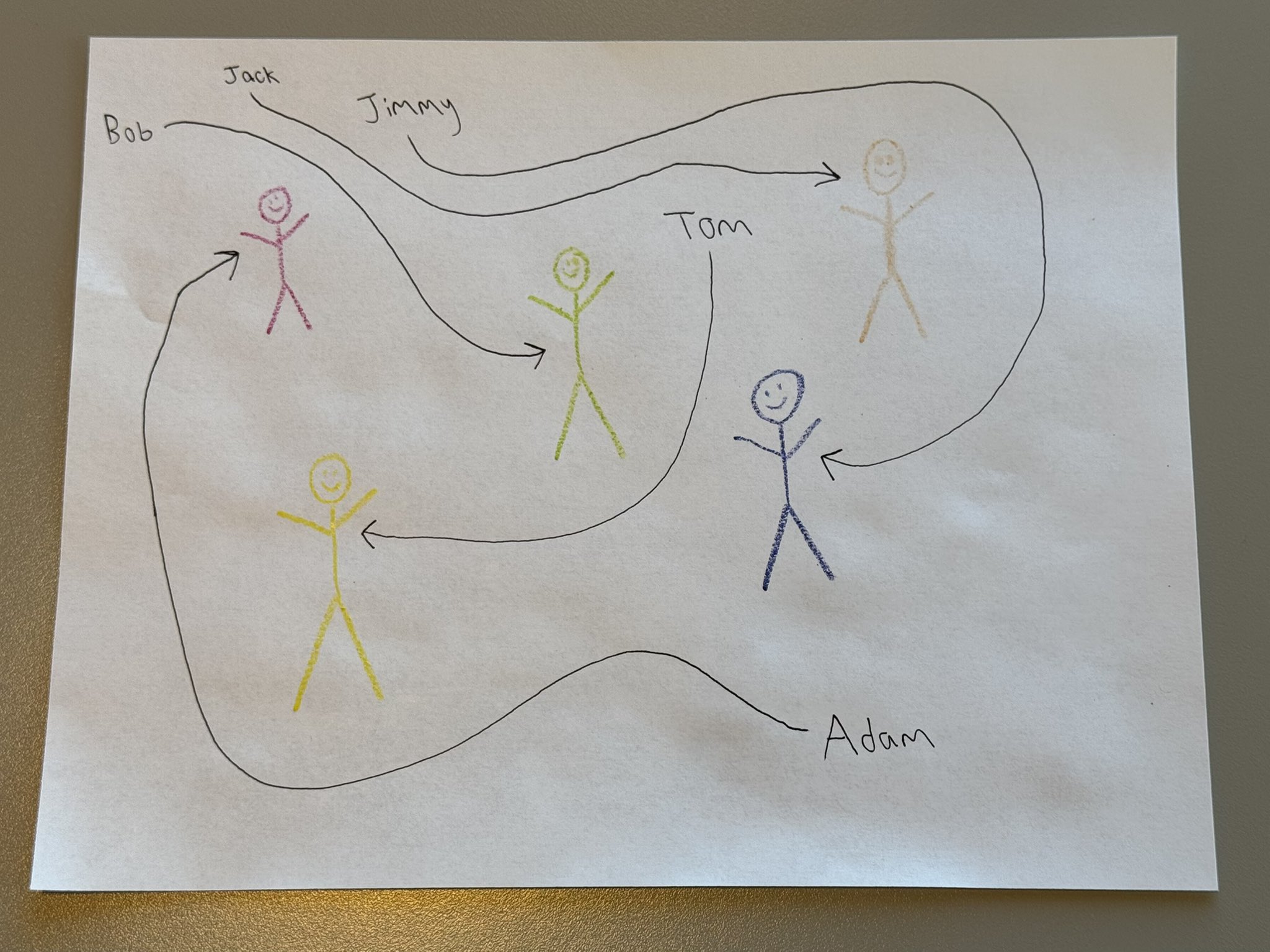
Models in 2025 could not solve this problem.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ548 | |
| 2 | Ṁ400 | |
| 3 | Ṁ269 | |
| 4 | Ṁ203 | |
| 5 | Ṁ200 |
People are also trading
This doesn't seem intractable relative to other things like reasoning, coding, etc. If the labs put a few months of research effort into vision reasoning I think it would basically be solved. It mostly comes down to whether stuff like open-ended RL or continual learning ends up being a higher priority (I think it might be, since those seem to have a quicker payoff for AC or SAR)
_