Based on this tweet from Spencer Schiff:
https://x.com/spencerkschiff/status/1910106368205336769?s=46&t=62uT9IruD1-YP-SHFkVEPg
Resolves YES if a mainstream AI model (so like, Google, OpenAI, Anthropic, xAI, DeepSeek) can repeatedly solve this benchmark, using this image and other similar ones I draw. I will be the judge of this (so please do not lobby me with your own attempts, except to alert me to the likelihood that a particular model can do this so I can try it for myself).
“Solving the benchmark” means being able to match the names to the colors of the stick figures, repeatedly and with simple prompts.
I’m not paying any money, so must be the free version of an AI model for me to verify! Again… FREE VERSION!
By the end of the year!
The image for reference in case the tweet is deleted:
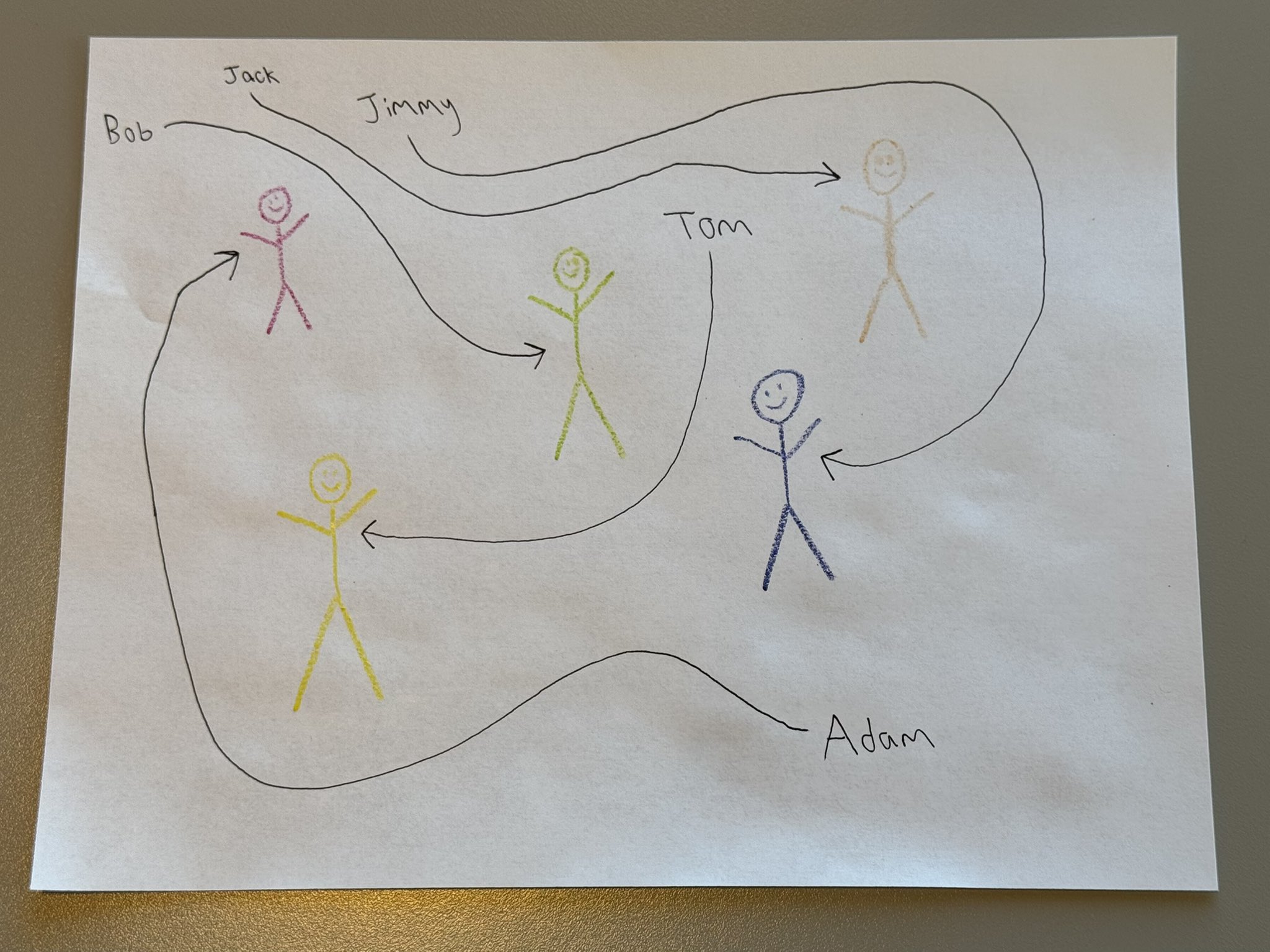
…and here is what ChatGPT gives me now:

…and Gemini 2.5

I will not bet in this market to remain objective.
Update 2025-11-18 (PST) (AI summary of creator comment): The creator may wait for AI Studio access to properly verify Gemini 3 performance due to mixed reports, rather than relying solely on the standard Gemini app interface.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ91 | |
| 2 | Ṁ65 | |
| 3 | Ṁ61 | |
| 4 | Ṁ45 | |
| 5 | Ṁ44 |
People are also trading
Gemini 3 gets it in the app. Every time the same prompt: "Match each name to the color of the stick figure its arrow points to"
I ran it 3 times. Here are my multiple chats:
https://gemini.google.com/share/0e05f16bc3dd
https://gemini.google.com/share/87b6b21e8f6b
https://gemini.google.com/share/5ab928a71f4e
Then I got rid of my system prompt. Mixed. Here are those 4 chats:
Fail - https://gemini.google.com/share/970a9348ed20
Success - https://gemini.google.com/share/f40ceb342033
@JaySocrates interesting, I’ll check tomorrow but I’ve already seen so many mixed reports of Gemini 3 on this test so I think we might need to wait for some way to do it thru AI studio
@JaySocrates it seems to do better when you mention the arrows. At least in my tests (in the app).
I'll make a version where api calls for less than a few $ are allowed if that is ok. i think freeness affects the question a fair bit and makes a bigger % of the question dependent on stuff like which labs decide to offer frontier models for free which i'd rather isolate from the specific capabilities question
@Bayesian ya that's fair, I mainly just didn't want to litigate something where someone was claiming some paywalled AI could do it and was sending screenshots of their tests.