Based on this tweet from Spencer Schiff:
https://x.com/spencerkschiff/status/1910106368205336769?s=46&t=62uT9IruD1-YP-SHFkVEPg
and the market by @bens:
/bens/will-a-mainstream-ai-model-pass-the
(Note: the main difference with that market is that the models I accept do not need to be free to use, but can cost reasonable amounts of money, typical of current frontier models on the API.)
Resolves YES if a mainstream AI model (Currently, only Google, OpenAI, Anthropic, xAI, DeepSeek and Meta count, but if some other lab becomes similarly mainstream they will count as well) can repeatedly solve this benchmark, using this image and other similar ones I draw. I will be the judge of this.
“Solving the benchmark” means being able to match the names to the colors of the stick figures, repeatedly and with simple prompts.
I will pay for api credits if needed (limit: ~$20 per model). I will prompt each AI model a few times (6) and see if it succeeds at least 4 times out of 6, but I won't be running the same model multiple times and use some kind of cons@32 technique to aggregate multiple attempts.
The image for reference in case the tweet is deleted:
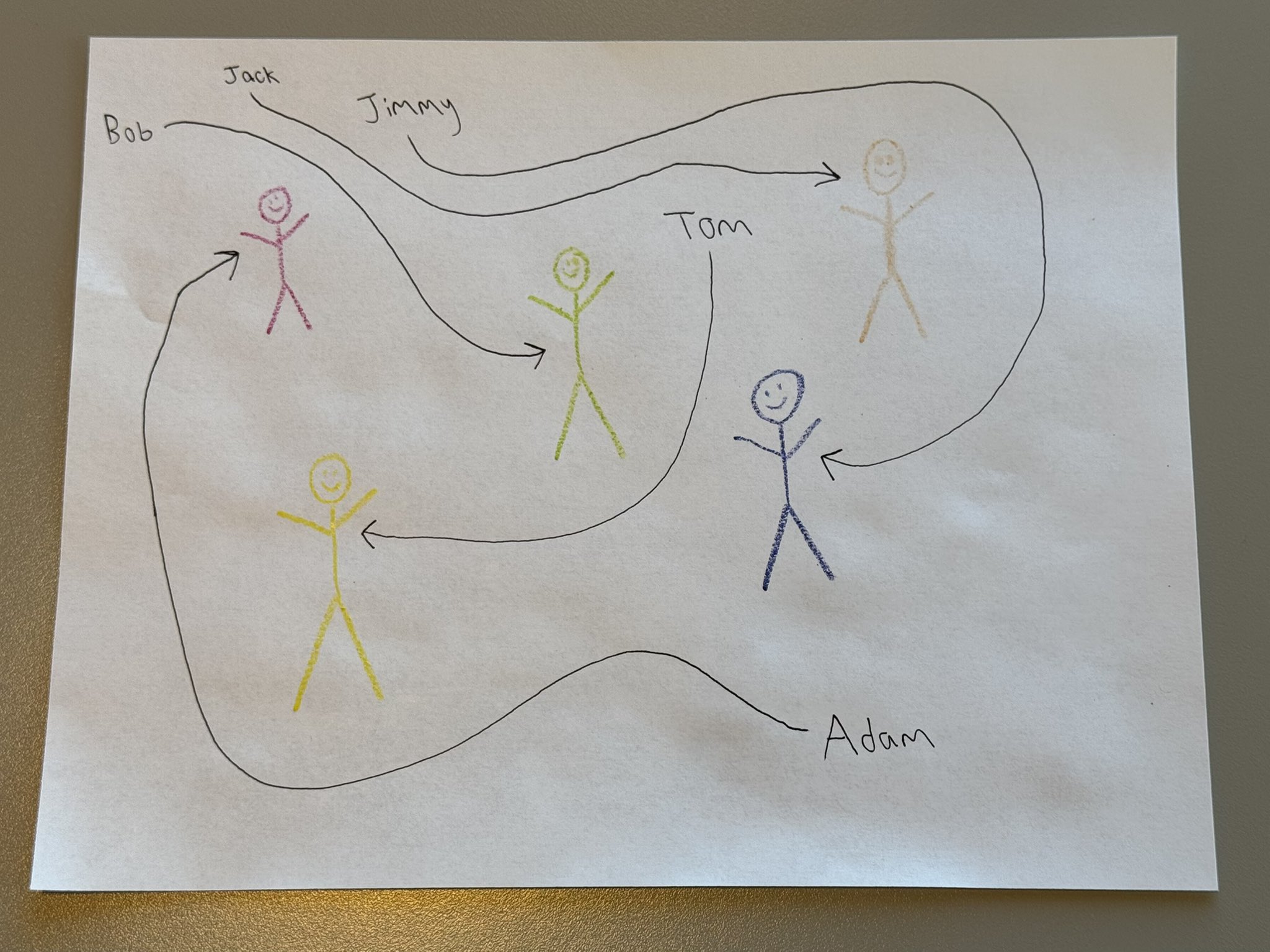
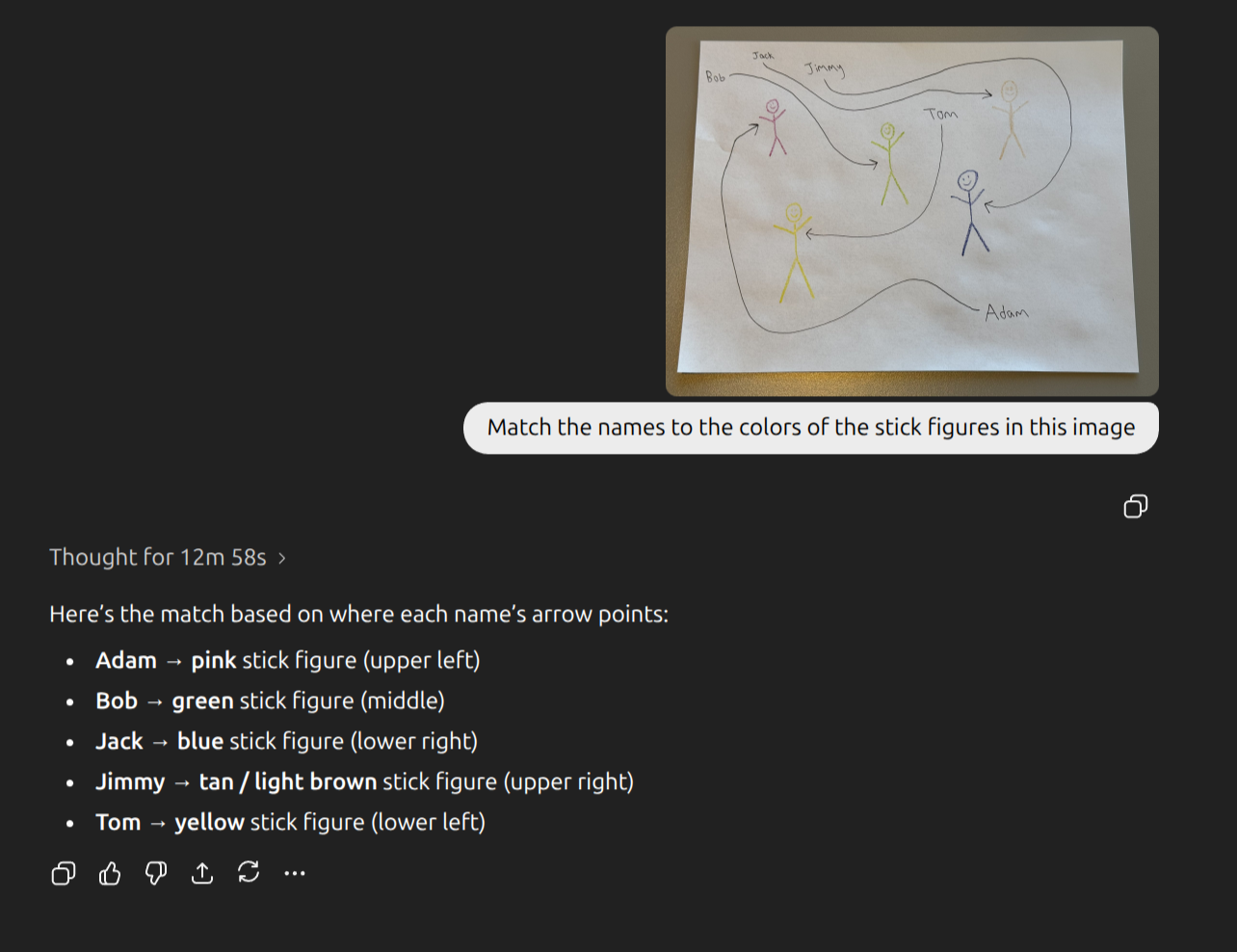
…and here is what ChatGPT gives @bens now:

…and Gemini 2.5

I will not bet in this market to remain objective. (Edit: I forgot i had written this and got a position. if the outcome is ambiguous an uninvolved third party may determine resolution)
Update 2025-04-16 (PST) (AI summary of creator comment): Prompt Guidelines Clarification:
Prompt Length: Use roughly one short sentence to describe the desired task.
Allowed Adjustments: Small amounts of prompt engineering (for example, suggesting the use of a built-in tool) are acceptable.
Disallowed Complexity: Extensive multi-step instructions (e.g. a 20-step breakdown) are not permitted.
Update 2025-11-29 (PST) (AI summary of creator comment): Testing Process: If you have a prompt that you believe succeeds 4/6+ times, the creator will test it and resolve the market positively if it works. However, the creator will ensure this cannot be exploited (e.g., by submitting 100 different prompts and relying on chance variance), and will preferably only test the most promising setups.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ5,798 | |
| 2 | Ṁ855 | |
| 3 | Ṁ770 | |
| 4 | Ṁ582 | |
| 5 | Ṁ208 |
People are also trading
@Bayesian So 4/6 either API or chat client, fine, but what if there's a prompt that always yields >4/6 but many other prompts don't get to that level?
@WilliamGunn If you have a prompt you think succeeds 4/6+ times I’ll test it and resolve the market positively if it works. But I’ll make sure this can’t be hacked eg yall cant get me to try 100 prompts and rely on the outcome variance to resolve the market yes by chance, so ill account for stuff like that and preferably will only have to test the most promising setups
I thought that Gemini Nano Banana Pro might succeed at this, based on recent posts about how the model can reason across image generation. No luck. https://x.com/nmatares/status/1992364170101379494?s=46

@yaakovgrunsfeld One-shotted it for me as well!
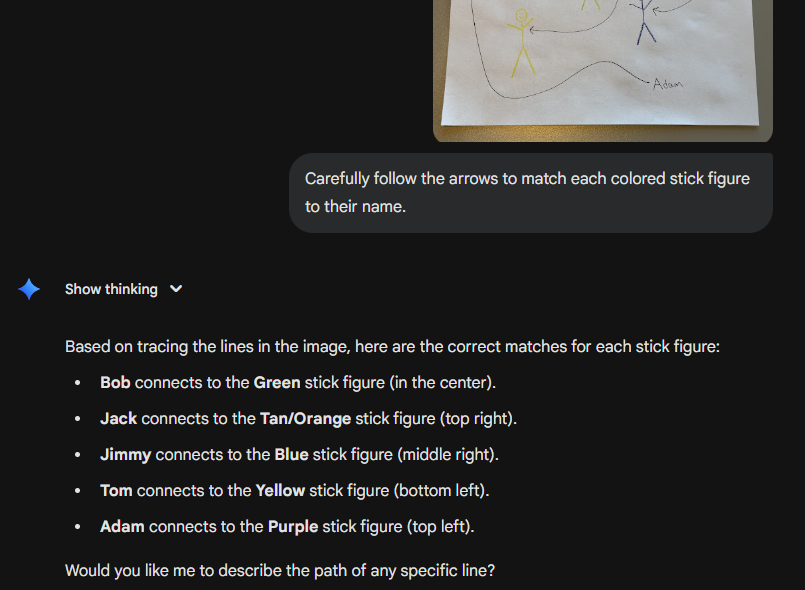
And then totally failed the second time with the same prompt. Womp womp I guess.
I was about to write a comment scolding someone for trying the test with the same figure over and over, only to realize that's how the market is phrased.
JFC people, 2.5y into the LLM revolution and we still don't realize that they can memorize the answer to any one question? Especially if tons of people spam the exact same question over and over, it will make it into training data?
The correct way to run this eval is to have a way to generate random stick figure / arrow diagrams. It shouldn't be too hard to vibe code an app for this.
@pietrokc This is not how the market is phrased, there is an explicit "using this image and other similar ones I draw". Presumably, makes no sense to try with other images if models don't reliably get it correct for the single example, but I would expect @Bayesian to check some other images of this type should the main example be solved reliably.
@Dulaman I'm also wondering if the new codex max model can do this. Would that meet the criteria if it ran for 4 hours on my machine writing python scripts and got the right answer?
Gemini 3 through https://gemini.google.com/app works reliably. I uploaded the image and used the prompt "Match the names to the stick figures by color."
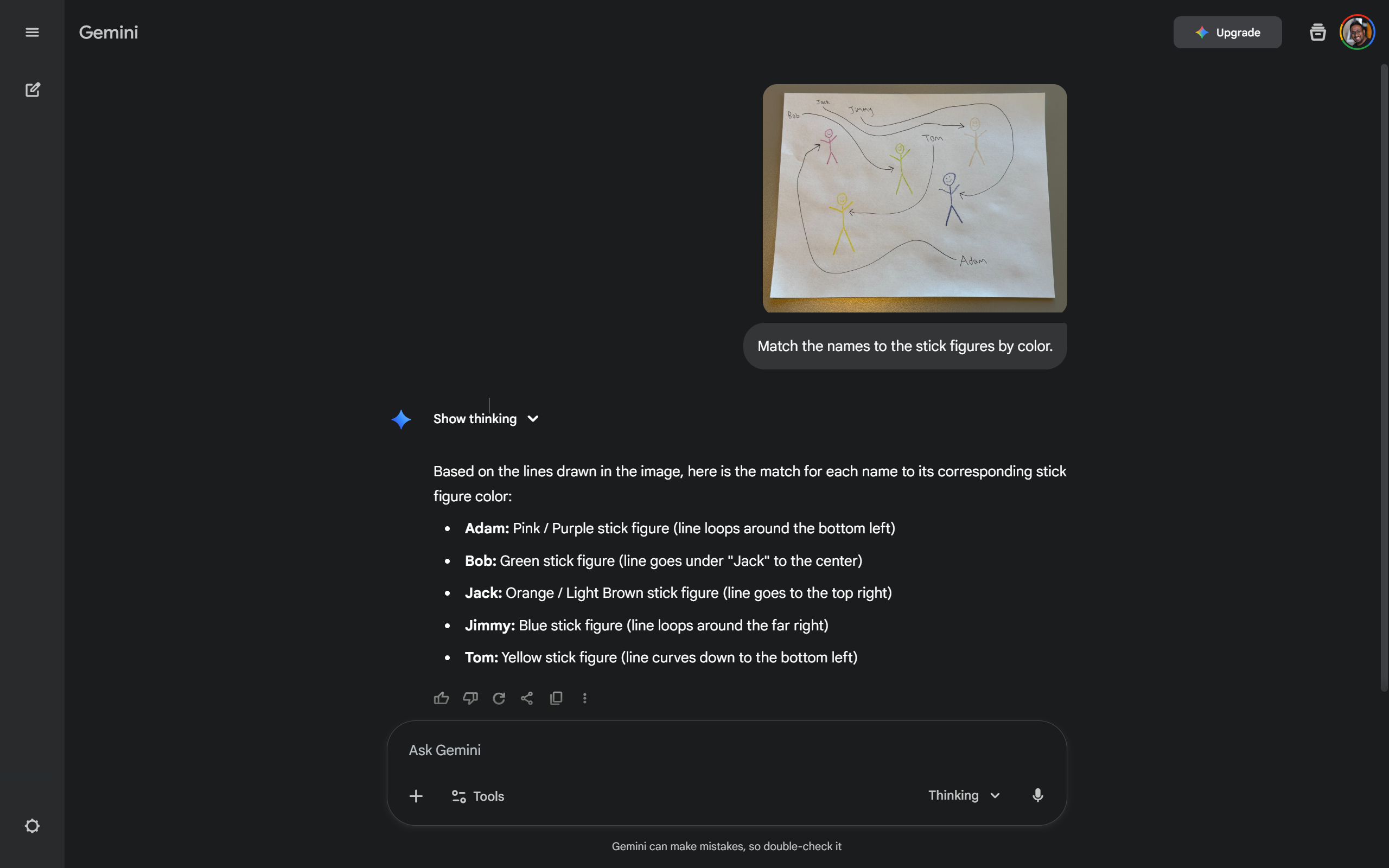
Gemini 3 gets it in the app. Every time the same prompt: "Match each name to the color of the stick figure its arrow points to"
I ran it 3 times. Here are my multiple chats:
https://gemini.google.com/share/0e05f16bc3dd
https://gemini.google.com/share/87b6b21e8f6b
https://gemini.google.com/share/5ab928a71f4e
Then I got rid of my system prompt. Mixed. Here are those 4 chats:
Fail - https://gemini.google.com/share/970a9348ed20
Success - https://gemini.google.com/share/f40ceb342033
@JaySocrates yeah ig this is sufficient for YES resolution. PS it was public knowledge that Gemini 3.0 could solve the problem before this market was created

@JaySocrates Replication: with all personal context off, in-browser, Gemini 3 succeeded in 9 of 20 trials. Of the 11 failures, 7 switched Jack/Jimmy, 4 were wild. Certainly doesn't feel like a yes resolution to me. May prompt-engineer this over the weekend. I expect that for Gemini 3, 3-4 sentences might get a consistent correct answer but 2 would require a very special prompt.