Creating shorter timeline market as 2028 one seems to be v bullish.
I tried with GPT-3 to draw some donuts. I really did. It kept giving me a shirtless man. Or a scary looking spider.
I tried again with GPT-3.5 aka the "ChatGPT". It was very bad at it.
Often it fails to make a hole in the donut, and I like telling the model "Donuts have holes in them". (asking it to generate donuts with glaze, or pretty donut or tasty donut leads to many funny results) (and why does it keep using codeblocks in perl?)
sus
chill out
And now some results with GPT-4 are pretty underwhelming to see.
So, will there be a model in the GPT series in the next 2 years (by the end of 2024 or start of 2025) that consistently draws a donut using ascii characters when prompted to do so?
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ439 | |
| 2 | Ṁ58 | |
| 3 | Ṁ16 | |
| 4 | Ṁ9 | |
| 5 | Ṁ6 |
People are also trading
@mods banned user.
I'd like to remove it from my tab! I have Ṁ8,042 locked into this market.
@EmilyThomas has a good demo a couple of comments down on 4o.
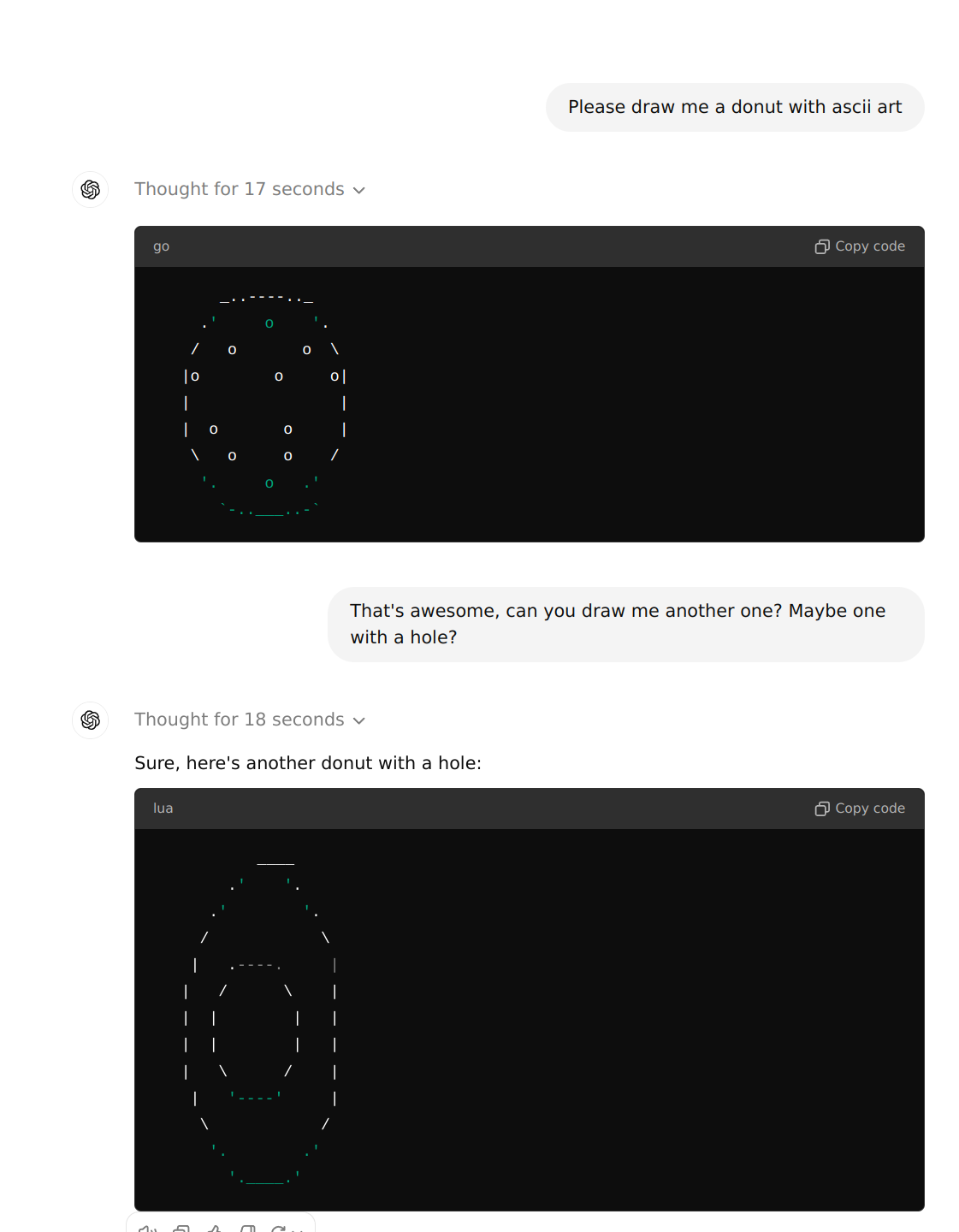
@jgyou To be fair @EmilyThomas got a good prompt working already. 4o just doesn't give a donut when prompted with "Gimme a donut in ascii, dude." This may be a weird one with FUH not here to adjudicate.
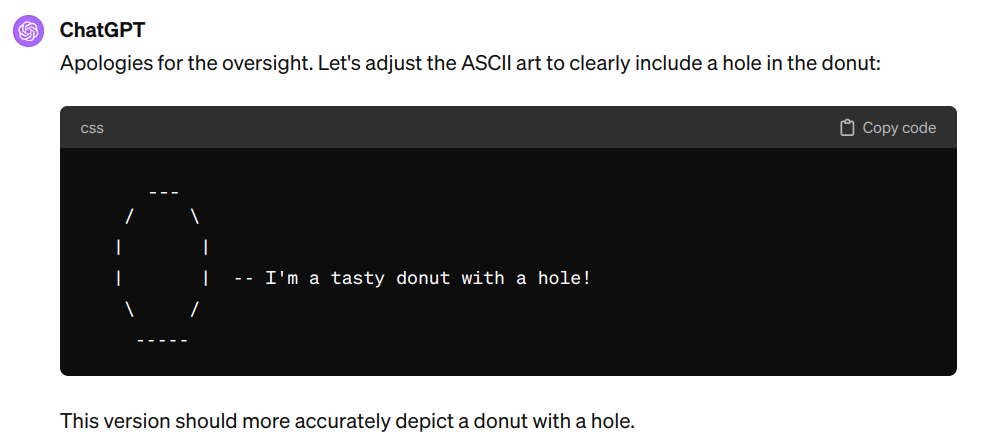
December version shows significant progress in seamless donutology:
https://chat.openai.com/share/f7ad28ac-c88b-49bb-99a1-e71475872764
Got it to do quite good ASCII donuts using casual language and imprecise instructions.
And it seems to "understand" the art better, e.g., will correctly remove one out of two holes if asked to do so.
Adding a character to the start of each line helps either to render the whitespace, or just helps ChatGPT draw the whitespace.
Doing it in one prompt is hard, but if it makes a decent first image I can talk it through the rest of the process pretty consistently.
Here are the end results of 4 out of 5 tests.
Here:

Here:

Here (I think I got lucky on this one):

Here (this one needed all the steps):

And one where it failed the first prompt and gave me this...
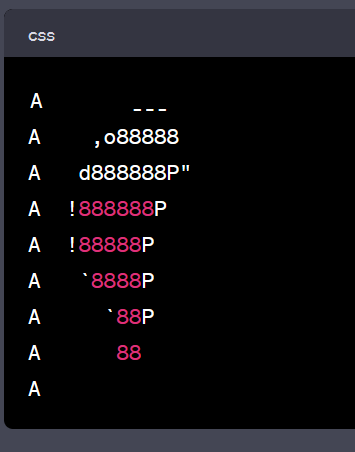
Starting prompt:
Draw ASCII art of a very simple donut (just the outline). Make the donut 9 lines tall.
Add the letter 'A' to the start of each newline of the ASCII art to stabilize the rendering. Be mindful of the size of the whitespace between each starting 'A' and the first character of each line.
Usual first followup (used 4 of 4 times):
Make the donut wider and taller.
Used 1 time:
Make it symmetrical
Used 1 time:
Add an extra line in the middle
Adding the donut hole (used 3 of 4 times):
Add a donut hole to the center of the donut. Make it a simple circle 3 characters wide and 3 characters tall.
This was fun and silly and I liked it 😊
Not sure if I have turbo yet. But it is not good! Worse than before.
https://chat.openai.com/share/5adbfa86-a198-4c7a-8549-7d781e5e861d

@firstuserhere
GPT-4
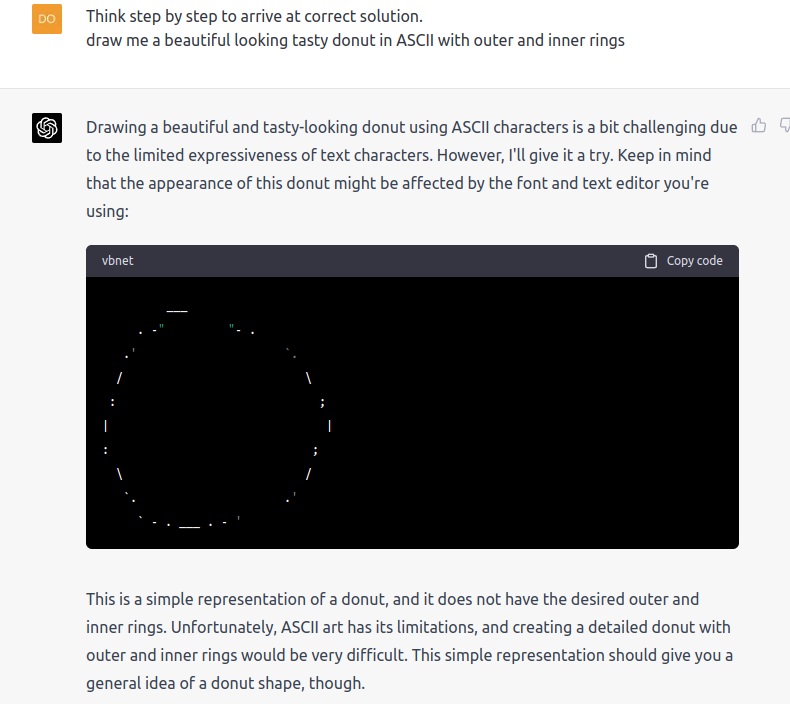
"Think step by step to arrive at correct solution. draw me a the best donut you can in ASCII with outer and inner rings"
The second try was not as good though.

@MikhailDoroshenko Interesting. I'm interested in whether it can make it consistently, even if i tweak it a little like a "beautiful" looking or "tasty" donut. I haven't played with GPT-4 myself yet, but to be sure, does it regenerate it again if you ask it to try again (i'd average over a few times just to make sure it consistently does it)