
 1,000
1,000People are also trading
@mods someone other than me please resolve.
It seems below that the creator is partial to an NA resolution, and others have made arguments as well.
@chrisjbillington oof I picked this one up and it's a toughie. I'm inclined to resolve YES, for the very good argument Mira made:
1.0 Ultra was available publicly through Gemini Advanced for $20/month. You could've run the test using that if you really wanted.
And if you talked to Google sales they would tell you it's available to "select developers" and "enterprises".
So it's a well-defined question that could've been answered.
NO betters had the opportunity to run the test themselves and chose not to. So we should default to Google's numbers in the absence of anyone caring.
but I don't feel comfortable enough with this to do so unilaterally. I'll mark this mod report as "new" and hope we get another perspective and maybe consensus
@Stralor the argument seems totally symmetric to me - it's not clear why the onus should be on NO bettors instead of YES bettors.
If Google's potentially cherry-picked numbers are enough to resolve on then that's one thing, but if they're not then I don't see why we should still default to them unless one side shows otherwise.
Also this:
1.0 Ultra was available publicly through Gemini Advanced for $20/month. You could've run the test using that if you really wanted.
Is that actually true? Is manually running a benchmark feasible? I don't know how big these benchmarks are and how much copy-pasting that would involve, whether there are rate limits to the web UI etc.
Certainly never crossed my mind someone here should or would consider doing that. Even if they did, how would we verify the result, unless it was the creator or a mod themselves running it? Everyone was waiting for a publicly verifiable number.
@chrisjbillington that's fair! but still we fall back to Mira's final point: we do have a number, even if it's one cherrypicked by Google. it's not perfect, but it's something
I've closed this to trading.
The creator is inactive, and to my knowledge we aren't actually waiting on anything for the market to resolve - resolution is supposed to be about the state of things at the time Gemini (ultra) was released.
So this should be resolved now. Feel free to discuss how you think it should resolve and present your evidence. If it's clear I can resolve it and if not then it will go to a three-mods vote.
I'll leave some time for discussion and then post to discord requesting a mod vote if needed.
Alternatively, if @brubsby is around and seeing this ping, they can resolve themselves.
@AndrewHebb I think the implication of "no full release" is that there is no API access, which means we have not seen third-parties running evals, which makes it hard to resolve this market.
@brubsby mods can NA, if you decide you want to NA let me know and I can press the button.
@jacksonpolack I have a position so shouldn't be making any calls myself, but are you suggesting it be NAd?
isn't the outcome of this market clear? run BigBench on Gemini Ultra and the version of GPT-4 that was released and see which scores higher. markets getting N/A'd seriously makes my experience on Manifold worse https://github.com/google/BIG-bench
BIG-Bench-Hard - Gemini Ultra's score was 83.6%
"GPT-4" (specific model unspecified) scored 83.1% in the Gemini paper
the "gpt-4-1106-preview" model was the newest gpt-4 model at the time of Gemini's release. can someone run BIG-Bench-Hard on that model? papers often compare to gpt-4-0314 instead of the latest model at release
@ampdot that's their self-reported result, but is it that simple? The table in their blog post says 83.6% on BigBench is for "3-shot" evaluation. This is the same test conditions (unlike some of the other reported benchmark results, which is pretty damning!) as they use to report GPT-4's results (83.1%), but there's still the accusation they they may have chosen the testing conditions that most favoured their model. And without a public API release, we can't verify their result or check whether Ultra outperforms GPT-4 in zero-shot or other evaluation conditions.
Given the performance of the two models in three-shot testing is so close, it's plausible that the outcome may depend on whether it's zero-shot or two or three, and this market didn't specify.
I suppose if whatever the best GPT-4 model was that existed at the time of Gemini's release (possibly not the same as their blog post results are about) did better than 83.6% on BigBench with 3-shot testing, then we could reasonably resolve NO, based on assuming Google reported the results most favourable to their model and it still not being enough. But if we were to test the appropriate GPT-4 model and it performed more poorly than Ultra with 3-shot testing, I don't think it would be particularly fair to resolve YES, since using the testing conditions chosen by google unfairly favours them (assuming we trust their result - ignoring the fact that we can't reproduce it without a public API release).
1.0 Ultra was available publicly through Gemini Advanced for $20/month. You could've run the test using that if you really wanted.
And if you talked to Google sales they would tell you it's available to "select developers" and "enterprises".
So it's a well-defined question that could've been answered.
NO betters had the opportunity to run the test themselves and chose not to. So we should default to Google's numbers in the absence of anyone caring.
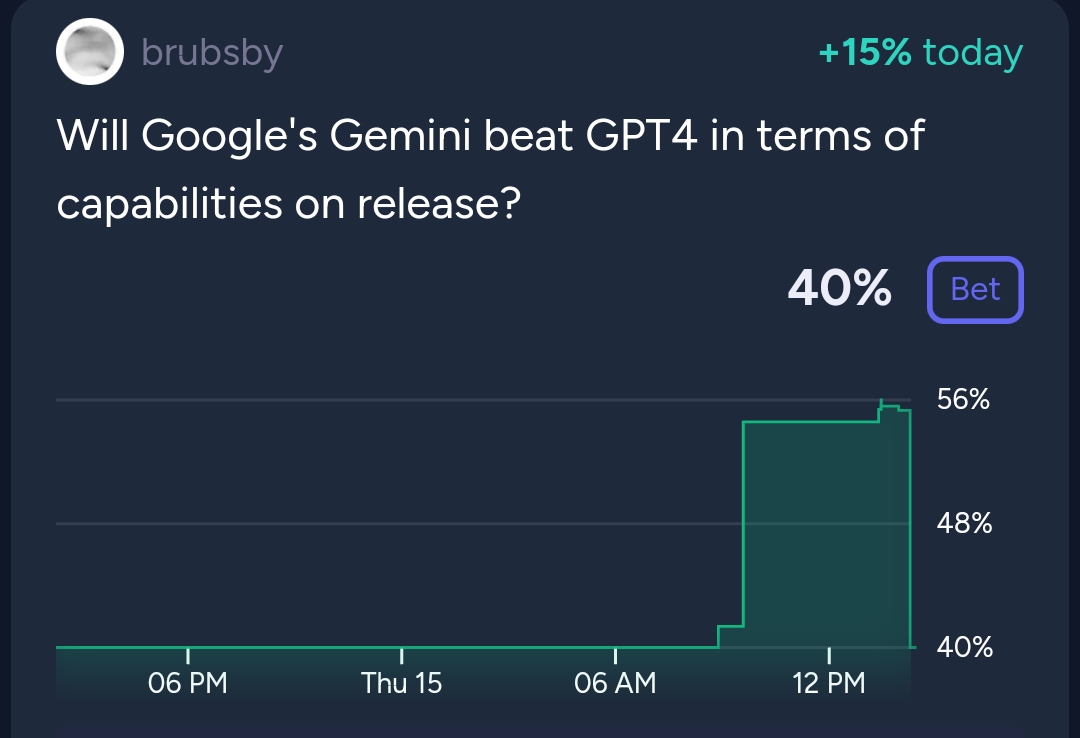
@Joshua I'm quite happy to take mana off the table and hand the risk to @chrisjbillington
The MM has a history of being a bit "vibe-based" with the resolution of this specific market. Is 1.5 the same as 1? Ultra? Advanced? What version of GPT 4 are we talking about now? It really could go either way.
Top top that of @ZviMowshowitz and others are reporting that their experience with Gemini is quite good, superior to GPT 4 in many regards.
@jgyou The market says "on release", and whilst there were gripes about whether Pro would count for this (brubsby's market on whether "Gemini" would be released resolved YES on Pro being released), I think it's very clear a 1.5 release would not count. This market is about whether Gemini Ultra right now is better than GPT-4 right now.
Recent data point not yet posted here: Bard with Gemini Pro score below GPT-4 turbo on chatbotarena
https://twitter.com/lmsysorg/status/1750925807277781456
@brubsby will GPT-4.5, if such a thing is released before Gemini Ultra, count as GPT-4 for the purposes of this market, or no?