
GPT-4's benchmark results as of its release in march 2023.
Acceptable upto 17 billion.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ31 | |
| 2 | Ṁ23 | |
| 3 | Ṁ16 | |
| 4 | Ṁ4 |
People are also trading
I reviewed the Yes claim from Jonathan for Gemini 1.5 8b and Gemma 2 9b.
I found a website called docsbot.ai which has a comparison feature between models that includes a benchmark comparison table:
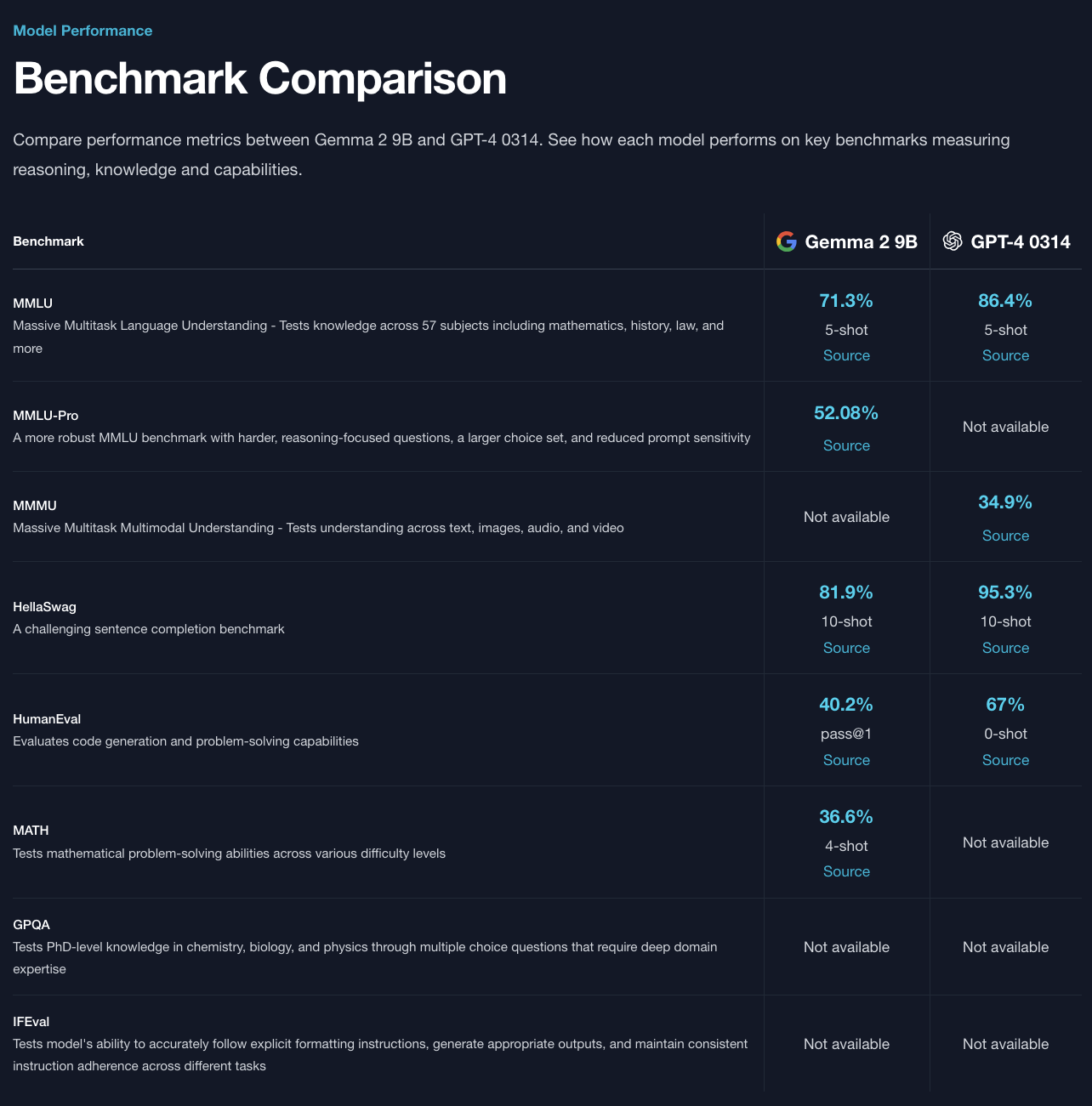
First, it looks like gemma-2-9b comes up short in ALL benchmarks, I don't think this reaches "match or outperform":
https://docsbot.ai/models/compare/gemma-2-9b/gpt-4-0314
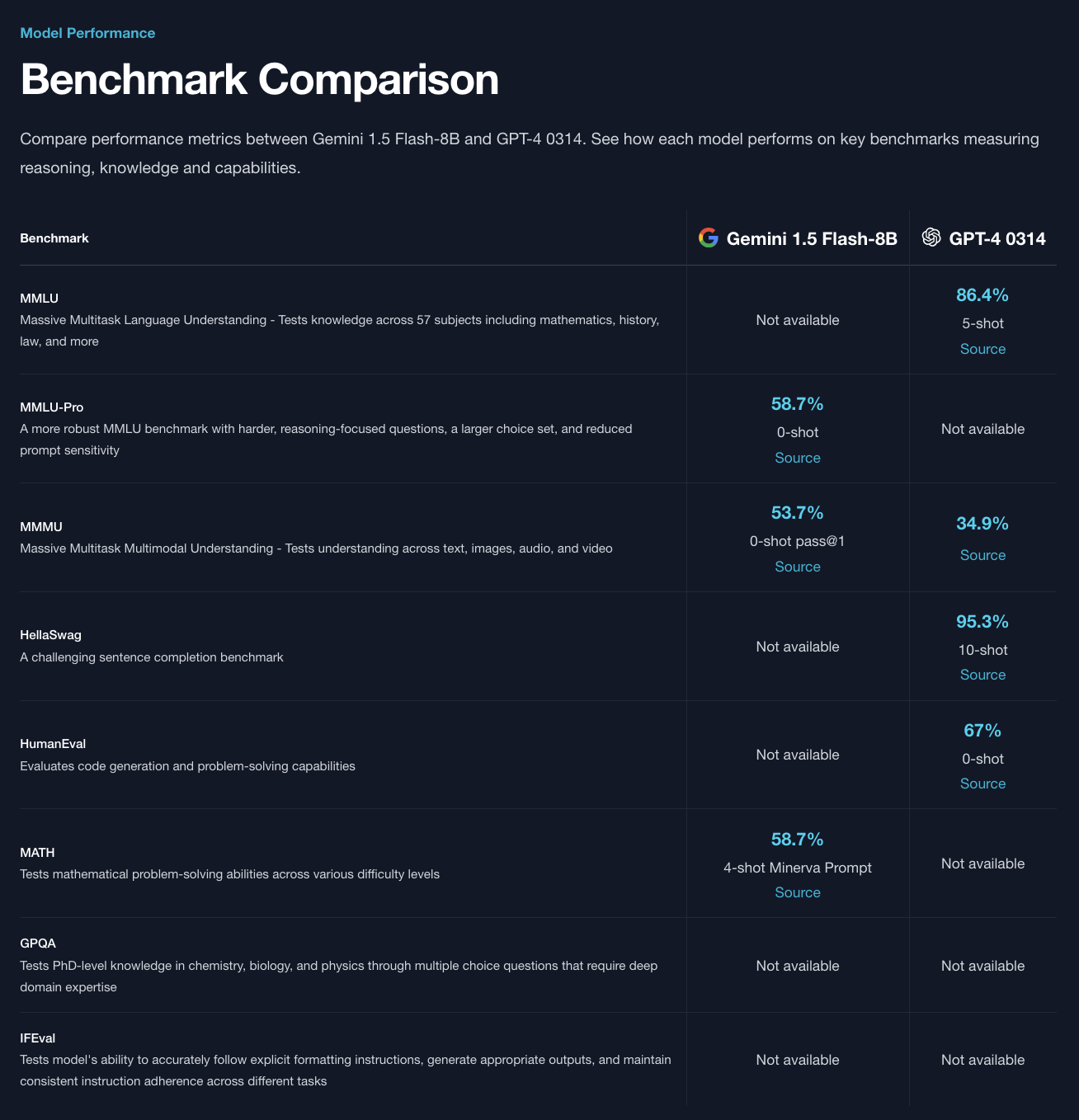
Next, gemini-1.5-flash-8b only has one benchmark in common with gpt-4-0314, but it does win on that benchmark:
https://docsbot.ai/models/compare/gemini-1-5-flash-8b/gpt-4-0314
I think this is enough to resolve Yes because it matched or outperformed on a benchmark. If I have terribly misunderstood things, maybe you can make an argument the other way. No one made any progress on this when Nathan Young looked at it 4 months ago and I am eager to resolve it.
I'll resolve this in 24-48 hours if no one has any complaints.
@traders Please review the above post, if there is something you disagree with, now is the time to share. I am trying to fulfill the creator's objective from this question. So far @jonathan21m has shown a comparison called LMSYS and I found a site with "Benchmarks" on it, but if this is not appropriate evidence, explain why.
@Eliza I sold my yes a loss a while ago because there were some better end-of-year market opportunities but I still think this resolves yes.
Obviously I agree tons of 15b models surpass the original GPT4 on blind voting. Furthermore the Llama 3.2 11b Vision model gets close to GPT4 on the MMLU even though GPT4 is 5 shot and Llama is 0 shot. Llama 3.2 11b trounces GPT4 on the MMMU.
TLDR; many 15b models surpass GPT4 on multiple benchmarks.
@mods can this resolve yes? According to LMSYS, the March 2024 version of GPT-4 is currently ranked 40th and is outclassed by Gemini 1.5 8b in 31st and Gemma 2 9b in 25.
@JonathanMilligan Okay but it isn't a "benchmark" see "GPT-4's benchmark results as of its release in march 2023." Right?
@NathanpmYoung If you look at the original paper where they introduce LLM arena they refer to it as a “benchmark” https://lmsys.org/blog/2023-05-03-arena/ and on the homepage they also refer to it as an eval benchmark. https://lmarena.ai/
