
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ293 | |
| 2 | Ṁ250 | |
| 3 | Ṁ57 | |
| 4 | Ṁ49 | |
| 5 | Ṁ44 |
People are also trading
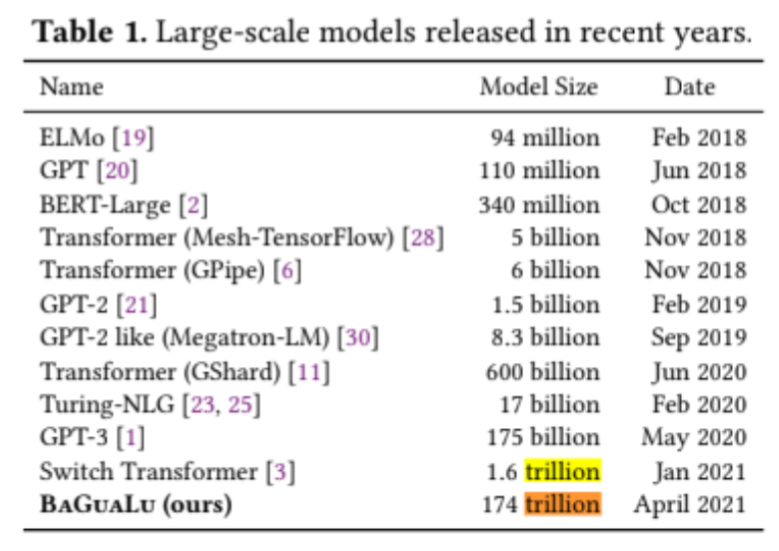
@Fynn After reading the comments I'm resolving this NO based on the reading of this as the serious use of a model with 100T parameters, and no positive evidence for this case. Of course feel free to discuss.
@traders so it seems that this exists if you clash a bunch of junk together, but it is essentially useless. This happened prior to the market being created, and yet the market was made, so it seems like it probably shouldn't count to have a useless mass model even if it does break 100T params?
Thoughts?
cc from the New Year Resolutions call @Bayesian @Kearm @Kearm20
@Gen I think it makes sense if you consider an "AI model" to be something that, in essence, is expected to perform the functions of an AI model. A set of weights that performs no useful function can be arbitrarily big, but will it be fair to call that an AI model?
There's a comment below in this market's discussion which correctly points out that the number of parameters is set in stone as soon as they are initialized; technically, no further training is necessary for that to happen if inflating their count is your only goal. But this clearly isn't what the market was intended to predict. My understanding is that it intended to predict whether a model of such magnitude would exist in the global market for AI models.
@Gen Given that there is no description, I think most people would assume that the title meant after the market was created. Otherwise what's the point? This seems to be validated by the fact that the market never went above 50% even after someone dug up this old model in the comments
@Gen This is what I understood when I bet on this market and after reading the comments: "An AI LLM with 100 trillion parameters is released by any significant, although not necessarily major, AI lab or research institution, and is released to the public or as a researcher-only access or something similar. And finally, that the model released is in some way competitive when comparing it to current SOTA LLMs via trusted benchmarks".
Judging by the trades, I'd say I was not the only one with a similar understanding. I'm aware this is just one interpretation. On the other hand, one could claim that maybe the Youtube, Facebook, or Netflix algorithms have had more than 100T parameters for some years, and that they are AI-based.
@Juanz0c0 There is absolutely zero chance any of those algorithms had 100T parameters at any point. The sheer cache/die interconnect speed requirements for running this at anywhere near meaningful speeds are beyond even the current hardware's capabilities, let alone what was available "some years" ago. GPT-4.5 is rumored to have somewhere between 10–20T and even that was essentially unservable just under a year ago.
@Sss19971997 yes, if it reaches 100 trillion (I don't remember llama2 param count, and yes 1400 of them would be a shit ton)
@WieDan yes but b100s are presumably a lot more expensive too, and companies will take a fair bit of time to set up their clusters, especially if they recently set up h100s and then the model training for a 100tril param model is a lot of time too, don't think it'll happen
@firstuserhere GPT-1 was 117M, GPT2 was 1.5B, GPT3 was 175B (the trend with the old scaling law)
GPT4 was 1.8T with a MOE setup.
So historically param count has 10x'd per generation.
https://arxiv.org/pdf/2202.01169.pdf
I'm not looking closely at this paper rn and this predates Chinchilla maybe conceptually but it vaguely seems like performance boosts from experts saturate past GPT-4 levels although I'm not sure if this applies to inference cost/speed.
@firstuserhere You never said it had to be any good. Making a bad model with 100T parameters ought to be rather easy, as long as you have the space to store them (I do not, however)
@retr0id exactly. 100T might not be heaps, but it's enough to not bother with unless you think you're going to achieve something.
@firstuserhere The model exists before it's done training. It exists as soon as the parameters are initialized.