Resolves to YES if at least one model scores at or above the human baseline, as evaluated by the creators of the benchmark, in 2026.
Resolves to NO if this does not happen.
 1,000
1,000People are also trading
@Bayesian nah I was just exiting my position after ARC-AGI-3 updated the human baseline: https://arcprize.org/blog/arc-agi-3-human-dataset
I think this is still likely no (and probably sold too quickly) but I just wanted to sell my position as the rules changed. Not sure what % I'd put this at yet. It is technically possible for an AI to score up to 115% now (though I still think it would be quite an accomplishment to do so).
Ya @ZviMowshowitz is there a document or something that defines how they're evaluating "above the human baseline" on the aggregate across the benchmark? Are they going to publish that value, so that it's normalized against the values they're using to assess AI?
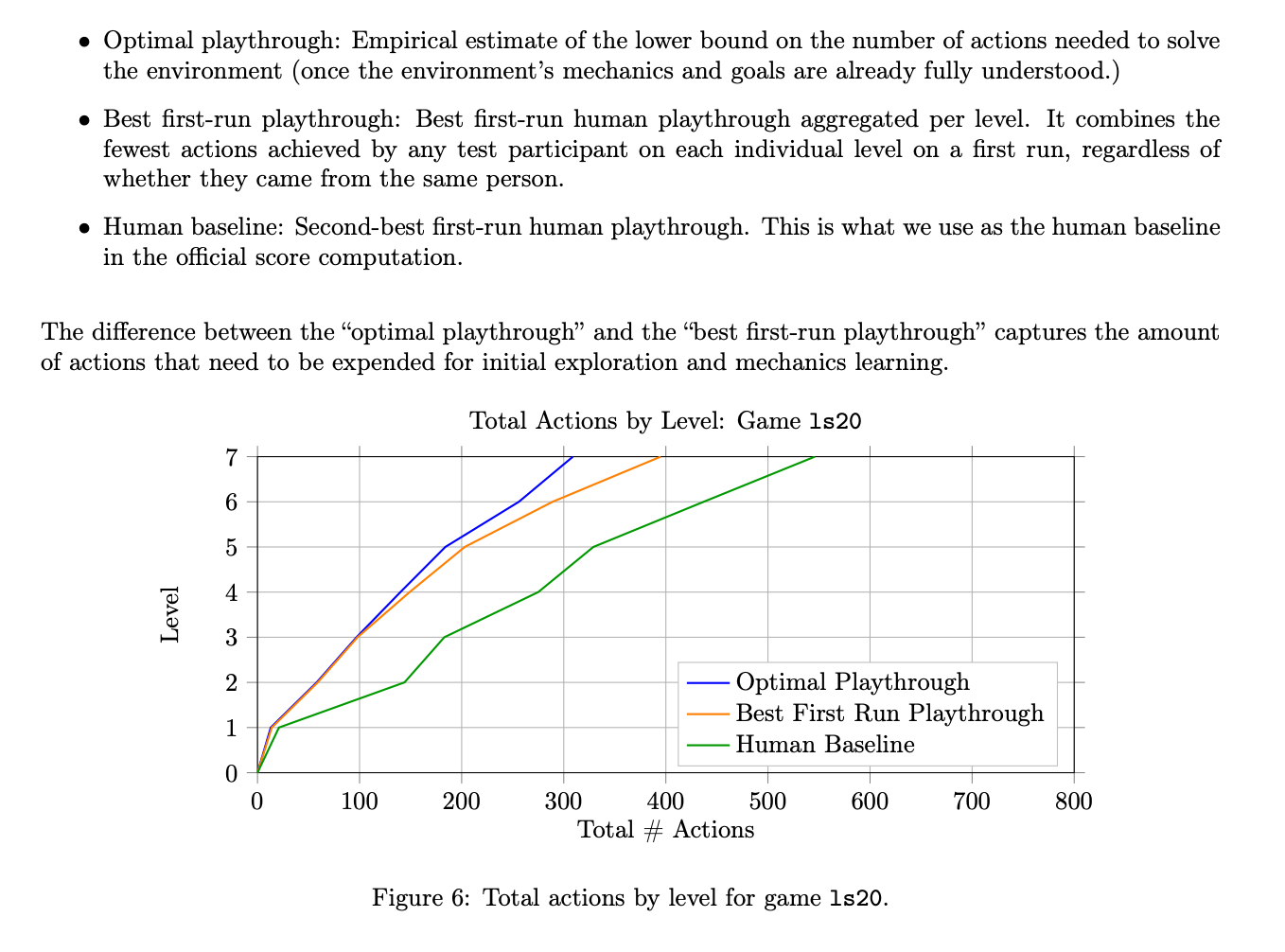
@bens @ZviMowshowitz this market says "at or above the human baseline, as evaluated by the creators of the benchmark" and their technical report defines the human baseline (using those exact words) as 100%. This is not at all representative of an average human, for reasons I have explained in another comment but I think the market description says it needs to go with ARC-AGI's definition of "human baseline". It's not possible to exceed 100%, as per the technical report "To stop a single glitch-level from distorting an entire environment score, we cap the per-level efficiency an AI can receive at 1.0x human baseline.", but theoretically if an AI matched or exceeded the second-best human performance on every level, it would score 100% and this would resolve YES.
@nostream i was under the impression that it’s 2nd best human perf per game / level, meaning if the game was ‘win rock paper scissors against a machine’, the 2nd best human for some given level would in most cases win, and so the ‘human baseline’ would be almost 100% despite 50% being the maximum attainable average score
@Bayesian right, I read something similar.
wanted to confirm that’s how this market operates since it makes the benchmark much harder.
(also, unlike ARC1 and 2 it’s efficiency graded and with a quadratic penalty, really pulling all the stops to make it as hard as possible. and no harnesses allowed.)
@nostream Right, plus they cap the scores at the human baseline, so even a perfect solution would still only be 100%.
I tried one of the puzzles myself, and I crushed the overall human baseline. Across eight levels, I used 469 actions, compared to a baseline total of 577: https://arcprize.org/replay/029460e3-fa75-405a-87dc-13565820bf1e.
But because I did worse than the baseline on a couple levels, my final score was only 76.6%.
@nostream to be fair for ARC AGI 2
they also said at least 2 humans solved each task so there is some level of consistency, so even though they claim human baseline is 100% the average score was ~60% which was passed 3-4 months ago
ideally this market would be similar
initially I was a big hater of the ARC-AGI 3 scoring methodology, namely
the shift from task completion to efficiency
First try only, doesn’t allow for learning from failure
No harness (I heard they already get like 97.4% with a harness so the benchmark is easily gameable)
The games themselves are super contrived again no vision just getting a massive json blob and a unhelpful system prompt (along the lines of
weird quadratic penalty, cap at 5x slower and 1x faster makes it even more contrived
Ideally we’d hear more from the labs themselves on whether they think this is a useful benchmark the way they viewed ARC AGI 1 and 2
Anyways in their defense
2nd is likely out of 10 not 500 since not everyone does every puzzle, think it’s like 90 mins and $110 plus 5 for each task completed so I’d assume they attempt ~30 per person so they probably have a corpus of ~1500 such games
So really this is like the 80th percentile of a slightly skewed (let’s say top quartile of humans) but fair benchmark representing the 90 to 95th percentile of human ability
so the only remaining critique is that it over indexes on gaming which humans have a ton of experience with whereas LLM can do things like Claude plays Pokémon and Chess with a harness and things like Dota with RLVR all the way back in 2018 or so. So I guess it follows the theme of ARC-AGI 1 and 2 of having an IQ test that isn’t leaked into the training data so forces labs to hill climb on this axis, though I assume this would take no more than 1-2 years assuming the no harness isn’t too strict for text only LLMs in which case it’d take ~3 years maybe. Definitely will be saturated in terms of task completion by EOY, but idk how big of a barrier efficiency is, I expect between 4% and 25% which is arguably around the human baseline / average
@bens Idk what human baseline means, they do basically fraud to say humans get 100%, very unserious company
@Bayesian ermm, ya I'm not sure, I'd guess it's some sort of aggregate of the number of moves it takes or...? idk
Tbh, I think the "number of moves" thing is kind of unserious. This penalizes AI for not literally training on this precise dataset, because why in the world would an AI exploring a new virtual environment be like "I must complete this in as few moves as possible"?
@Bayesian also do we hate ARC-AGI now? Idk the lore. Is Chollet unserious? I always thought the benchmark was cool but that the scoring and leaderboard were fairly inscrutable.
@bens the benchmark itself is pretty good! The implications made by chollet et al, their communication around human baseline, the analysis of what the benchmarks are ‘really testing’, etc. are often extremely bad and unserious