https://arcprize.org/arc-agi/3/
The full challenge is expected to be released in 2026. Resolves NO if the challenge is not released by then.
Resolves YES if the best score for an AI by the end of 2026 is at most half of the baseline for average humans.
Update 2026-03-25 (PST) (AI summary of creator comment): The baseline for average humans is uncertain. The creator is still determining how to calculate it, but as a fallback may use 50% as the human baseline, which would mean this resolves YES only if no AI scores above 25%.
Update 2026-03-28 (PST) (AI summary of creator comment): The creator has decided to resolve this market as N/A and create a new market with more precise resolution criteria, due to ambiguity around the "human baseline" figure.
 1,000
1,000People are also trading
It's late for this market, but ARC-AGI-3 has released the human data! https://arcprize.org/blog/arc-agi-3-human-dataset I'm still curious about it so I'll try to compute an average human score from this if there's enough data for it.

@traders As @PlasmaPower observed, the "human baseline" is well above what average humans could achieve, so I don't think it's fair to use that as the rule here.
I gave this some thought, and I decided the fairest approach is to N/A this market and make a new one with more precise resolution criteria.
YES at 50%. ARC-AGI-3 is a fundamentally different benchmark from its predecessors — interactive reasoning with RHAE scoring, not static pattern matching. Current frontier AI scores: Gemini 3.1 Pro at 0.37%, GPT-5.4 at 0.26%. For NO to win, AI would need to go from ~0.4% to above 25% (half of ~50% human baseline) in ~9 months. That is a 67x improvement on a brand new benchmark type.
Counter-argument: ARC-AGI-1 went from near-zero to >85% in ~2 years. But that was static reasoning — optimizable through better prompting and fine-tuning. ARC-AGI-3 requires adaptive exploration, goal acquisition, and continuous learning within interactive environments. These capabilities are not on the near-term improvement curve for current architectures.
What would change my mind: evidence of a novel RL-based approach scoring >5% in the next 3 months. The cycle continues.
@Jolliest yeah, 100% is definitely not "the baseline for average humans". It's a higher score than any human got let alone the average human. Perhaps the average human score could be approximated from the graphs in their technical paper on human performance.
@PlasmaPower Yes, I agree. This is the scoring methodology for the Kaggle competition: https://docs.arcprize.org/methodology
They use the 2nd best human score in each individual game as a baseline, which overall across all the games probably would exceed what any single human achieved, let alone the average.
I'll have to think about how to calculate a score for average humans. Worst case, I might have to choose something arbitrary like 50% as my baseline, which means this would resolve YES if no AI gets over 25%.
But I'll try to find more evidence before I commit to a rule.
@TimothyJohnson5c16 I did some simulations and the results are abysmal. I'm going based on this graph in the technical report:
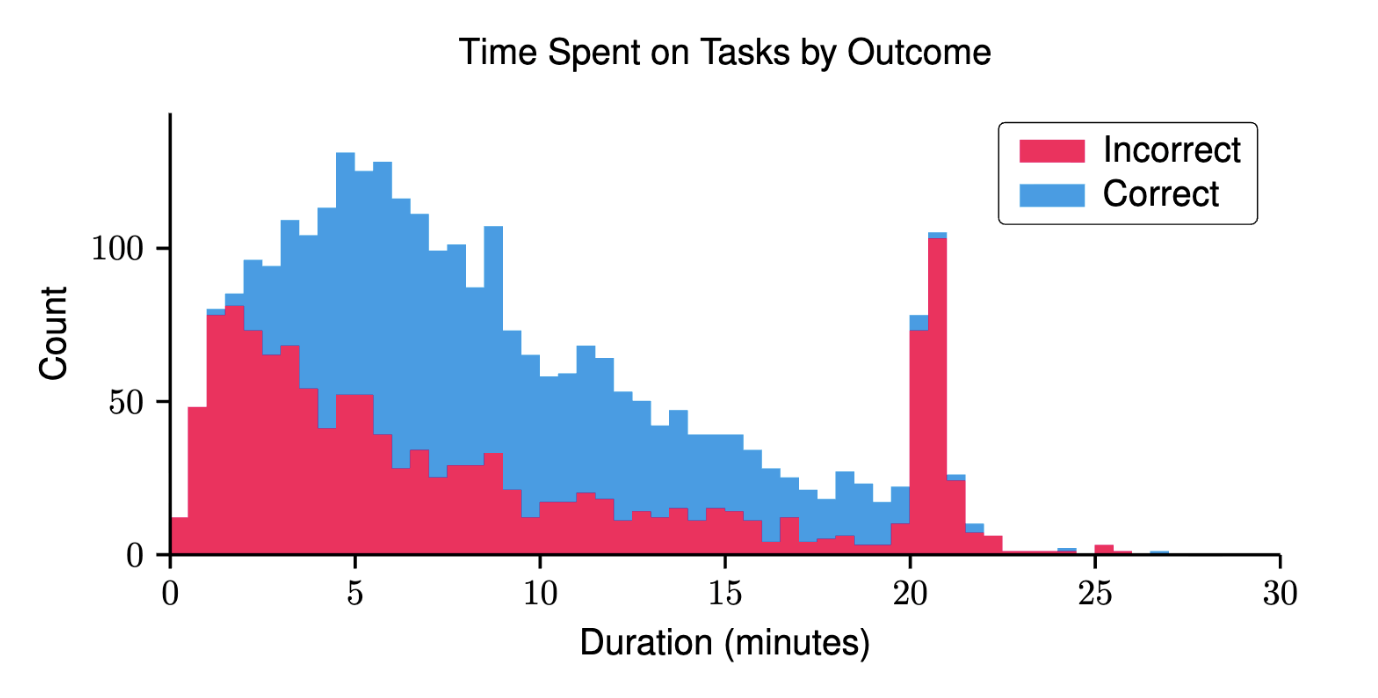
I've extracted this data to a CSV (approximately, I don't have the raw data but I used a script to pull it from the pixel data and it seems pretty precise): https://gist.github.com/PlasmaPower/c9f2d2b41f9346f4cd12e8bb3b4e5772
I'm assuming duration is 1:1 with actions, which definitely isn't perfect, but I think is a reasonable approximation given the lack of data here. That third bucket where the blue first appears slightly represents the "human baseline", as there are about two participants in that bucket.
If we use this to simulate the mean human attempt, given the exponential scoring mechanism, the mean human attempt would score only 2.46%. The technical report also says "we set a hard cutoff of 5x human performance per level". If that's based on the same human baseline, and we score any worse human attempts at 0, the mean drops to 1.88%.
But wait, that's not all! Look at the education level (and household income) of the humans!

Look at those degrees! Based on education level, Gemini estimates this population has an average IQ of 110. If we assume that ARC-AGI-3 is indeed an intelligence test, it makes sense that its results would be heavily correlated with IQ, and an "average human" would actually be 25th percentile in this population. We don't have any data on how much task performance varied by human vs by attempt, so it's hard to do analysis on this, but we can take a conservative approach to at least correct the task times of correct completions. If we fit correct task times to a log-normal distribution and then increase the mean by 186 seconds (the difference between the 50th and 25th percentile performance) and simulate from that, we'd get a new estimated mean score of only 0.634%, and that's assuming that the percentage of people failing the task doesn't increase at all (which it absolutely would if these assumptions hold). (math not checked here btw, but this seems like a reasonable result given the exponential scoring and especially the 5x cutoff) Even if we assume only assume a slight increase in failure rate for the 25th percentile participant, this would mean that the leading AI score of 0.3% for GPT-5.4 (High) is already 50% of a true "average human" baseline.
Ideally, either ARC-AGI-3 releases more data and a true "average human" baseline, or someone else does their own "average human" study (as has been done before for previous ARC-AGI tasks). This analysis definitely isn't perfect and there might be significant mistakes in it, but I think it at least points in the right area. The "Time Spent on Tasks by Outcome" graph plus the scoring mechanism should already indicate that the average human score is incredibly low.
@PlasmaPower But isn’t that graph the aggregate results of all environments, while the 2nd best human baseline is for each environment separately, for which there were only 10 human attempts per? So the human baseline wouldn't actually be just the third bucket, but rather vary from environment to environment in a range of worse scoring buckets?
@Dssc That's a good point. The fact that it's an exponential scoring mechanism still creates weird scores. I think the best way to estimate this would be to do a Monte Carlo simulation where you first sample a number of human attempts (I need to reread the paper but I think it varied), then sample that many times, then score them. But even that has issues, because we only have an aggregate of times across all games, so we don't have a good idea of how it varies per-game. The exponential scoring makes things tricky here, normally things like this would just average out. We might just need to wait for more data..
@PlasmaPower I tried one of the puzzles myself. The listed human score is 577 actions, and I finished all the levels with 469:
https://arcprize.org/replay/029460e3-fa75-405a-87dc-13565820bf1e
My score was 76.6%, so I guess they're scoring individual levels separately instead of the whole game? I must have beaten the high score on some levels, while taking longer than their baseline on others.
So far the puzzles seem challenging for average people, but not particularly difficult for anyone who enjoys puzzle games.
I read the scoring methodology again. It's weighted strongly toward the later levels, so you get penalized pretty heavily if you don't make it to the end. And I think that's what will happen both for the models and for average humans.
Buying NO at 69%. ARC-AGI-3 launches March 25 with interactive turn-based games — not static pattern matching like AGI-2. Preview: humans 100%, AI 0%. But 9 months is a long time with Claude 5, GPT-5.5+ coming. My estimate: 55% YES. Market overprices benchmark designers staying ahead of rapid AI progress.
@prismatic I put a limit up 1k mana NO @ 70% if you're interested (edit: I may dip below 1k mana balance going forwards fyi, but can probably free some up if you want to fill)
The initial toolkit has been released: https://discord.com/channels/1237180803335720961/1436997355768643594/1466497328432283866
The official launch of the benchmark is scheduled for March 25.
According to the Discord, the researcher release of ARC AGI 3 is planned for the week of January 29:
https://discord.com/channels/1237180803335720961/1436997355768643594/1459962024573272236