
I saw a question titled "GPT4 or better model available for download by EOY 2024?" and liked it. Still, I wanted another one with more objective and straightforward resolution criteria.
We use a loose definition of open-source that encompasses all previous versions of llama. In essence if it is theoretically possible for anyone to download the weights and run the model then it is considered opensource.
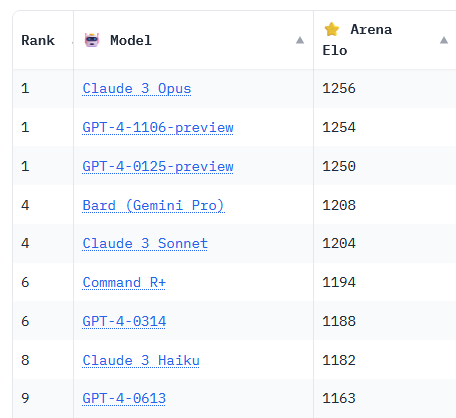
This market resolves yes if any open-source model achieves an ELO rating that ranks it higher than GPT-4 on ChatBot Arena at any point in 2024. New versions of GPT-4 do not count. The comparison will be done to the earliest GPT-4 version
FAQ
What is ChatBot Arena?
ChatBot Arena is a benchmark platform for large language models (LLMs) that ranks AI models based on their performance. It uses the Elo rating system, widely adopted in competitive games and sports, to calculate the relative skill levels of AI models. This rating system is particularly effective for pairwise comparisons between models. In ChatBot Arena, users can interact with two anonymous AI models, compare their responses side-by-side, and vote for the one they find better. This crowdsourced approach contributes to the Elo rating of each model.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ2,199 | |
| 2 | Ṁ260 | |
| 3 | Ṁ234 | |
| 4 | Ṁ121 | |
| 5 | Ṁ118 |
This market believes there is a 97% chance someone will release an open-source model that scores higher than GPT-4 on LMSYS (I agree 😋)

@Soli AlpacaEval is extremely easy to game (easier to game than chatbot arena), mostly via length. See "AlpacaEval limitations" here : https://tatsu-lab.github.io/alpaca_eval/
As new models are added and more comparisons are made, won't the ELO scores shift? Does this market resolve on the absolute score 1158 or whatever GPT-4's score is at the time?
@Vergissfunktor There's also this question: https://manifold.markets/FedorShabashev/will-an-open-source-large-language?r=VmVyZ2lzc2Z1bmt0b3I
@Vergissfunktor very good question - you are right that the ELO rating can and will move for the earliest version of GPT-4 so using a fixed ELO rating defeats the purpose.
@Soli can you clarify what you are using instead, if not a fixed ELO rating? Do you mean that an open-weights model needs to be above a version of GPT-4 on the LMSYS Chatbot Arena Leaderboard?
@Jacy exactly - do you have suggestions how i can modify the description to make this clear? I thought it already was 😅
Edit: probably using the words rank higher
@Soli Thanks! I believe all the criteria you have stated in the description and comments are entailed in this statement:
This market resolves yes if any open source model (i.e. anyone with sufficient hardware and domain knowledge can run the model locally) is ranked with higher elo than [the simultaneous ranking of] the earliest version of GPT-4, which was publicly known to exist as of market creation, on the LMSYS Chatbot Arena Leaderboard at any point in 2024. Otherwise, it resolves no.
To be super clear, you could include that bracketed phrase or add something like, "This means that, at some point in 2024, both an open source model and a version of GPT-4 must appear on the leaderboard simultaneously, and the elo of the open source model must be higher."
Edit: "the earliest version" previously said "any version," but I see the market resolution criteria clearly say earliest version.
@Soli I'd recommend dropping the number 1158 if it's not the absolute measure and just naming the model to compare against in the description
Do you mean Chatbot Arena - LMSYS Org or something else? Because Mistral has already scored 1150 and is open source...
