
Resolution Criteria:
This market resolves YES if Kearm successfully runs DeepSeek-V3 locally on his home GPU rig by 11:59 PM PT on January 5, 2025. Successful execution requires meeting the following benchmark criteria:
The GPU rig must achieve a benchmark score on the MMLU-Pro leaderboard that falls within an inclusive range of 3.5% above or below (a 7% total range) the official DeepSeek MMLU-Pro (EM) Exact Match benchmark score of 75.9.
The MMLU-Pro benchmark must be conducted using the EleutherAI LM Evaluation Harness, as specified here: https://github.com/EleutherAI/lm-evaluation-harness/tree/main/lm_eval/tasks/leaderboard
The official DeepSeek MMLU-Pro (EM) Exact Match benchmark score and methodology are detailed in the DeepSeek-V3 technical report: https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
If Kearm fails to achieve this benchmark by the deadline, the market resolves NO, regardless of progress or pending tests.
Original Description:
I am attempting to run a top 3 OVERALL LLM(After more testling like the best model in the world right now) but specifically DeepSeek-V3 LOCALLY on my home GPU rig and attempt get comprable(Within either 7% MMLU-Pro) between either offical API or Open Router by the 5th of January 2025. Current predicted market costs to run this model "locally" as in you have a server and 240W in your house is would 8xH200 so ~$256,000 USD in GPU'S ONLY. Now add in everything else, CPU, motherboard, DRAM, and cooling/server rack. Livestreamining this whole shebang at https://x.com/i/broadcasts/1MnxnDkgaMyGO
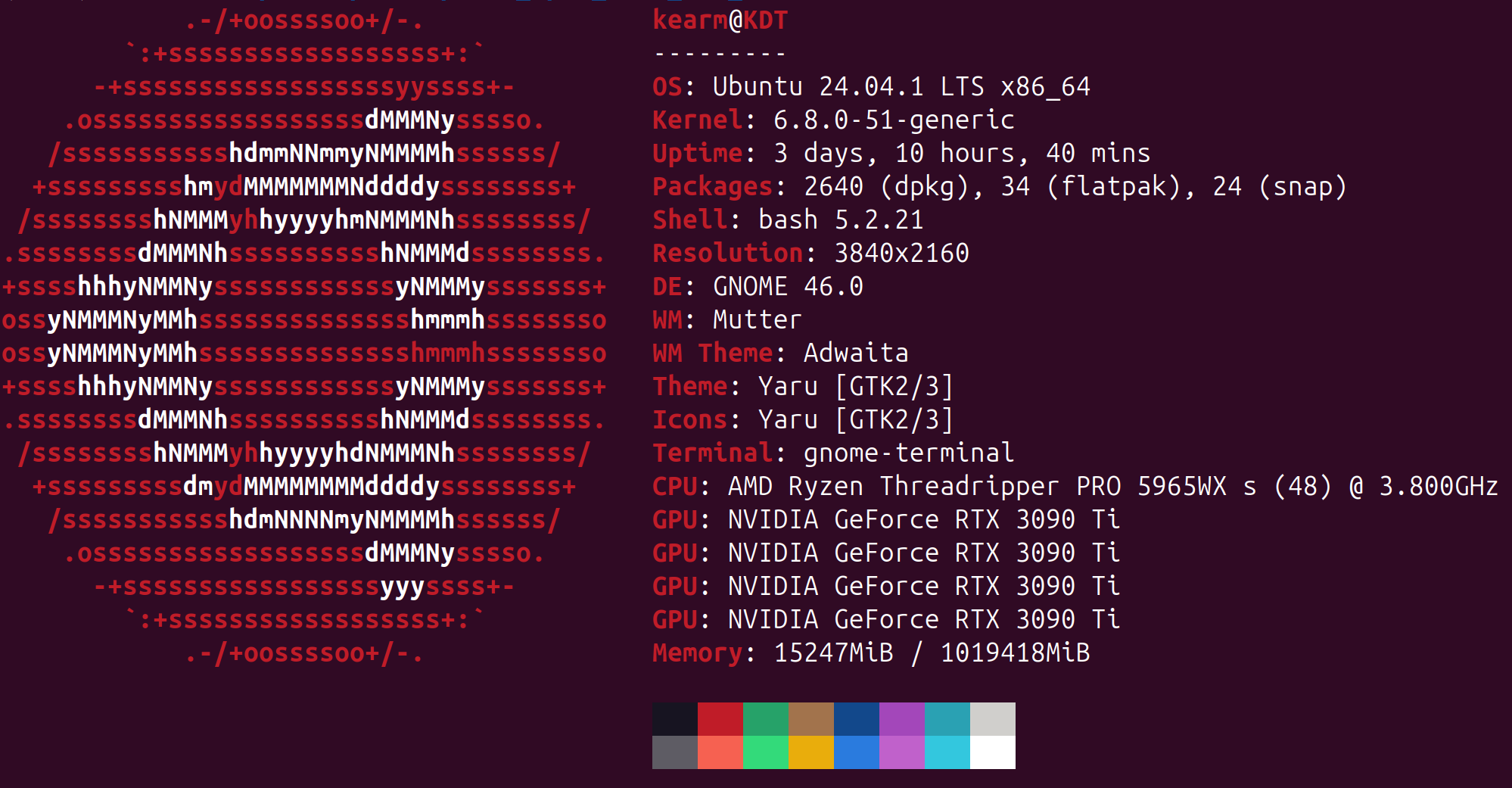
This is the machine's specs: Driver is 550.120(I've found it to be the most stable)
I may drop down to Jammy/22.04 LTS if needed.
Update 2025-04-01 (PST) (AI summary of creator comment): - Created a working Q8_0.gguf file.
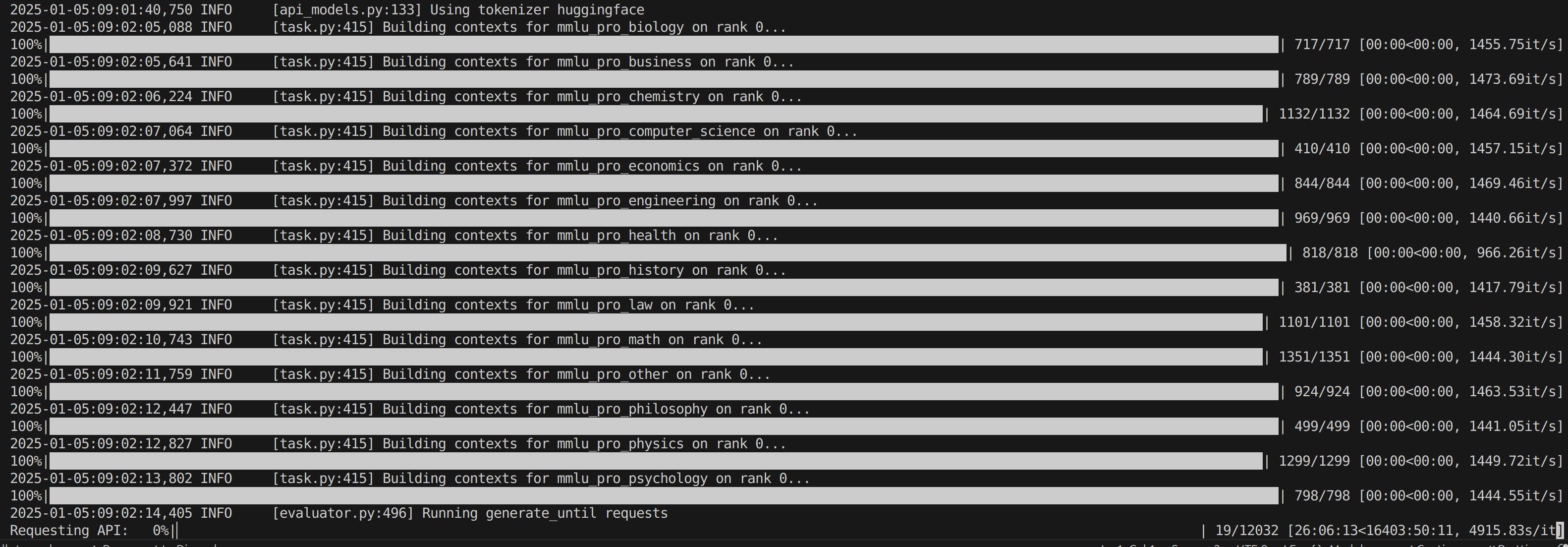
Benchmarking not yet run for MMLU-Pro or ANY OTHER BENCHMARK even a simple perplexity test.
Will use Eluther/lm-evaluation-harness commit 888ac292c5ef041bcae084e7141e50e154e1108a for MMLU-Pro benchmark unless a bug is found.
Livestreaming continues and screen recording started.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ110,788 | |
| 2 | Ṁ56,803 | |
| 3 | Ṁ31,639 | |
| 4 | Ṁ7,129 | |
| 5 | Ṁ4,743 |
People are also trading
To be UTTERLY CLEAR, this ~70-hour work session is a HORRIBLE IDEA for everyone. DO NOT ATTEMPT THIS as I have this:
A Team of Medical Professionals Monitoring You:
A psychiatrist who has known you for 20+ years and understands your mental health inside and out.
A neurologist who regularly checks your brain health with MRIs and other tests.
A therapist/psychologist who works with you consistently to ensure your emotional and cognitive well-being.
Rigorous Health Monitoring:
Epigenetic testing to understand how your body responds to stress.
Regular blood work to monitor hormones, immune function, and overall health.
Brain scans (MRIs) every two years to ensure no damage is occurring.
A Healthy Lifestyle When Not Working:
A strict diet and exercise routine to maintain physical and mental resilience.
A disciplined sleep schedule 99% of the time, with no all-nighters or sleep deprivation outside of these rare, highly controlled sessions.
Years of Preparation and Self-Awareness:
A deep understanding of your own body and mind, built over years of experimentation and monitoring.
The ability to recognize when something is off and stop immediately, even in the middle of a session.
A Rare, Unique Physiology:
Genetics and physiology that allow you to handle extreme stress in ways most people cannot. Even with all the above, this is not guaranteed to be safe for you.
@ChaosIsALadder The main problem at the moment is the task at hand which is the eval harness or llama-server which either one or both are bugged. If I make the file monolithic it fully loads the CPU and GPU so we are good until I attempt to connect with eval-haness then it and then it no longer loads the system correctly. There is also a level of uncertainty we are seeing in TPS which is very odd and likely something to do with the implementation as there is a crazy amount of weirdness in this model.
So the only main point I would disagree with is that with the imatrix 4bpw GGUF it is almost lossless from a MMLU-Pro standpoint as linked below. The reasoning why is the native FP8 training and sparse nature of this MoE make it VERY VERY good even quantized which is exciting for the future of AI in general.
Q4_K_M: 77.32
API: 78.05
I will let it run but current output is absurdly slow and I only a sudden hero implementation of MTP for speculative decoding to 1.8x the speed and/or a fix of what looks like a bugged eval harness would be needed.
I am looking at verbose output and interstingly so far it is getting all the questions corrrect. Will keep working at more agressive optimiations and attempt to fix the way that eval harness seems to call llama-server and let the current run run. There is also some crazy concurrency I could attempt as the eval only needs 2048 context so 16x concurrency would even be feasible on system ram, but it crashes the llama-server after a few moments of running right now.
To be UTTERLY CLEAR, this ~70-hour work session is a HORRIBLE IDEA for everyone. DO NOT ATTEMPT THIS as I have this:
A Team of Medical Professionals Monitoring You:
A psychiatrist who has known you for 20+ years and understands your mental health inside and out.
A neurologist who regularly checks your brain health with MRIs and other tests.
A therapist/psychologist who works with you consistently to ensure your emotional and cognitive well-being.
Rigorous Health Monitoring:
Epigenetic testing to understand how your body responds to stress.
Regular blood work to monitor hormones, immune function, and overall health.
Brain scans (MRIs) every two years to ensure no damage is occurring.
A Healthy Lifestyle When Not Working:
A strict diet and exercise routine to maintain physical and mental resilience.
A disciplined sleep schedule 99% of the time, with no all-nighters or sleep deprivation outside of these rare, highly controlled sessions.
Years of Preparation and Self-Awareness:
A deep understanding of your own body and mind, built over years of experimentation and monitoring.
The ability to recognize when something is off and stop immediately, even in the middle of a session.
A Rare, Unique Physiology:
Genetics and physiology that allow you to handle extreme stress in ways most people cannot. Even with all the above, this is not guaranteed to be safe for you.

@traders Since @Kearm20 seems to be out for now, I've created a market on whether he'll resolve in the next few hours: https://manifold.markets/ChaosIsALadder/will-kearm-resolve-his-market-today
@summer_of_bliss Not really a bug I can squash. I did mange to fit 3 hours of sleep in. It has completed 6 MMLU-Pro prompts.
@jim It's dead, Jim. I don't see how they can get the network to run fast enough to finish in less than 16 hours.
Running the entire MMLU-Pro benchmark requires processing 15,852,596 prompt tokens and producing around 600k+ output tokens. Even if we assume a miracle and @Kearm20 somehow manages to get DeepSeek v3 running with the same efficiency as Vicuna 13B quantized to 4 bits (note: 4-bit quantization would likely fail the MMLU-Pro test), a single RTX 3090 could achieve less than 15 output tokens per second (calculated as >35 * 13B / 37B).
Being extremely generous, if we assume perfect scaling across four RTX 3090 GPUs, the performance would increase to 60 output tokens per second. This is highly unlikely, as the GPUs lack sufficient memory and are almost certainly bottlenecked by system memory bandwidth.
Let's further assume that prompt tokens can be processed 4x faster than output tokens. Under this assumption, we could reach a hypothetical speed of 240 prompt tokens per second - an improvement by a factor of 1250 compared to 16 hours ago.
Despite all this, the total time required would still exceed 21 hours (< (15,852,596 / 240 + 600,000 / 60) / 3600).
I'm genuinely excited to see just how fast the model can run on @Kearm20 's machine, but I don't see even the slightest chance of it meeting the extremely tight deadline. I also highly recommend getting at least some sleep.
Sources:
https://github.com/ggerganov/llama.cpp/discussions/8450
"One run had 15852596 prompt tokens and 651281 completion tokens"
https://klu.ai/blog/open-source-llm-models
"Vicuna 13B v1.5 16k has been evaluated using standard benchmarks, human preference, and LLM-as-a-judge, showing promising results. Users have reported good performance with the model, with one user achieving 33-35 tokens per second on an RTX 3090 using the 4-bit quantized model."
https://api-docs.deepseek.com/news/news1226
$0.27/M input tokens vs $1.10/M output tokens implies 4x more resources used per output token than per input / prompt token.
@ChaosIsALadder The main problem at the moment is the task at hand which is the eval harness or llama-server which either one or both are bugged. If I make the file monolithic it fully loads the CPU and GPU so we are good until I attempt to connect with eval-haness then it and then it no longer loads the system correctly. There is also a level of uncertainty we are seeing in TPS which is very odd and likely something to do with the implementation as there is a crazy amount of weirdness in this model.
So the only main point I would disagree with is that with the imatrix 4bpw GGUF it is almost lossless from a MMLU-Pro standpoint as linked below. The reasoning why is the native FP8 training and sparse nature of this MoE make it VERY VERY good even quantized which is exciting for the future of AI in general.
Q4_K_M: 77.32
API: 78.05
I will let it run but current output is absurdly slow and I only a sudden hero implementation of MTP for speculative decoding to 1.8x the speed and/or a fix of what looks like a bugged eval harness would be needed.
I am looking at verbose output and interstingly so far it is getting all the questions corrrect. Will keep working at more agressive optimiations and attempt to fix the way that eval harness seems to call llama-server and let the current run run. There is also some crazy concurrency I could attempt as the eval only needs 2048 context so 16x concurrency would even be feasible on system ram, but it crashes the llama-server after a few moments of running right now.
@Kearm20 You ever stay up and hear the birds chirping in the early morning? Those are tough mornings. Just gliding through the day, slightly irritable, slightly unperturbed by anything. I feel you.
@Bayesian This isn't too far off from the SF hackathons I do pretty regularly. It's rather hard when there is something this fascinating to try things on but this is just more public than my other endurance tests haha.
@Kearm20 Then you’re sacrificing your long term cognitive capacities which isn’t something I personally understand being willing to do