I will run a Manifold poll 1 month after the official GPT-5 release asking whether or not it exceeded expectations. Resolves to results of that poll.
Update 2025-22-01 (PST): - The market closure date has been extended to July 1, 2025 following updates on the GPT-5 release schedule. (AI summary of creator comment)
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ2,843 | |
| 2 | Ṁ2,790 | |
| 3 | Ṁ1,860 | |
| 4 | Ṁ1,100 | |
| 5 | Ṁ722 |
People are also trading
@Mactuary Damn straight! The disregard for comms and branding among tech platforms continues unabated, but eventually one (and all it will take is one) company will hire people as good as the original Twitter brand & comms and CEOs will realize how many millions they've been leaving on the table.
@traders Poll here: Did GPT-5 Exceed Expectations?
https://manifold.markets/GabeGarboden/did-gpt5-exceed-expectations?r=R2FiZUdhcmJvZGVu
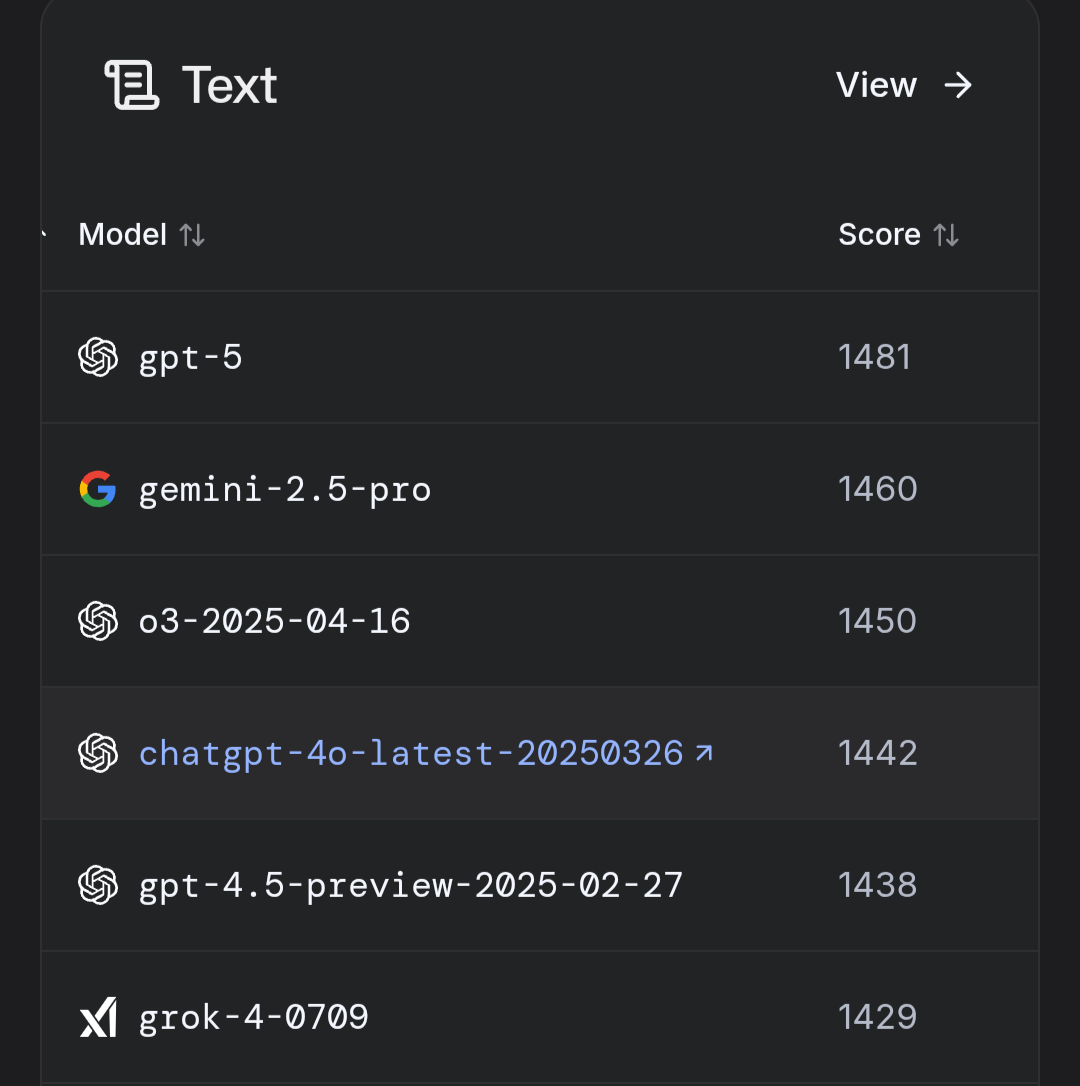

All that for +21 Elo score?
@TheAllMemeingEye bruh it's only 257 above GPT-3.5 from way back in 2022-23, so almost a fifth of the time the model from years ago will beat it XD
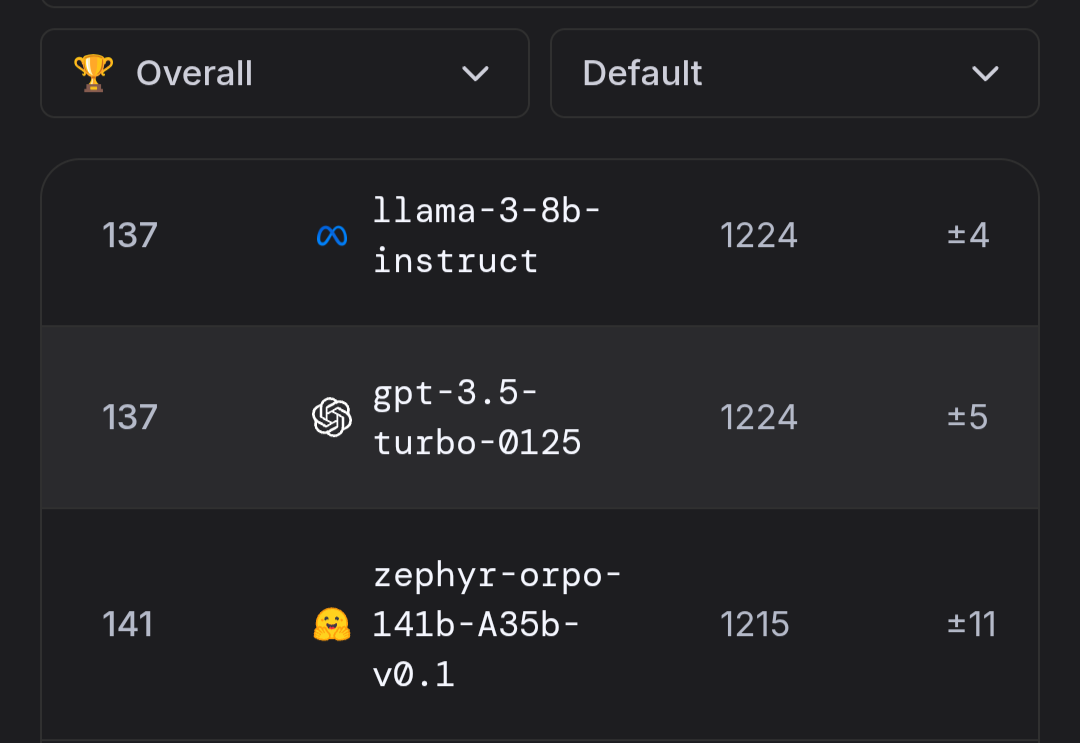
@TheAllMemeingEye It (or a classifier) chooses how much reasoning to devote to a query.
Not an actual technical term as far as I know
If anyone wants to keep trading https://manifold.markets/Thomas42/how-will-gpt-5-exceeds-expectations
EDIT: Poll will be posted in one month (per description)
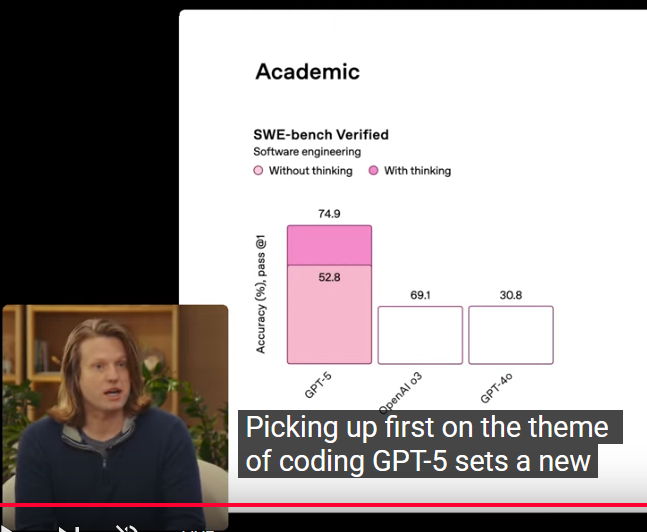
Closed so no arbitrage possible
https://manifold.markets/PhilosophyBear/when-gpt5-comes-out-will-more-manif
https://manifold.markets/strutheo/will-nvidia-stock-nvda-be-worth-188
This market should be correlated with this one, no?
@jessald Very loosely at best, I hardly expect that the performance of one model is going to have a big effect on Nvidia's stock