
The rules, according to my friend: "You pick posts from a few respected blogs from before 2022 (no cherry-picking) and also generate GPT-4 blogs (cherry-picking allowed). Say 4 of each. I bet I can pick out which are which given a decent length sample."
Resolves YES if he can tell them apart correctly (at the 1.4% significance level), NO if the null hypothesis is not rejected.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ641 | |
| 2 | Ṁ63 | |
| 3 | Ṁ59 | |
| 4 | Ṁ50 | |
| 5 | Ṁ35 |
People are also trading
(obviously within the last 20 minutes, not within the last two minutes)
don't post the answers w/o a spoiler so other people can do it.
also, how many was he off by?
@jacksonpolack answers (obviously spoils the whole thing): https://pastebin.com/3zVtkjFs
!!Indirect spoilers!!: Even having read them, still a bit surprised you were tricked - the writing styles are very clearly different - the GPT-4 ones have very smooth flow to the words (not in a good way) with lots of connecting clauses and unnecessary topic sentences and similar, whereas real ones have more awkward phrasings and points that are at least a little bit hard to understand because the author cares more about communicating something than words flowing. The non gpt4 blogs are the densest - they have interesting ideas and pack more content into sentences and paragraphs. I didn't pick up on who GPT was supposed to imitate at all. The least generic GPT post was <censored> but precisely because it was less generic it made several meaningful mistakes.
I wonder how much of that is whatever finetuning/rlhf/... openai did on top of the base model though, especially the writing style parts.
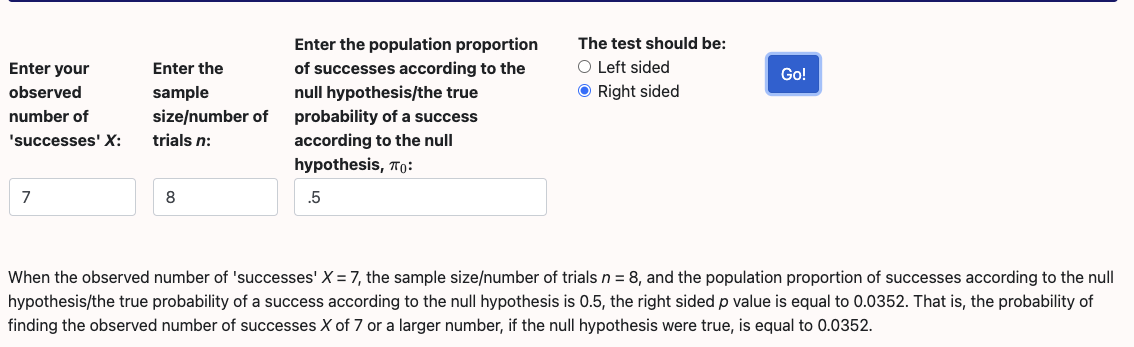
@DanMan314 oops, good point, I should've used the actual number, which is the 1.4% significance level. I've updated the description to match.
@Odoacre Depends on the guesser's utility function. They could want to hedge even knowing it guarantees not getting them all right.