Market resolves yes if a major Chinese AI developer (e.g., Tencent, DeepSeek, Baidu, 01, Alibaba, ByteDance, others that seem unlikely to totally fraud) announces evaluation results for a model which tie or surpass OpenAI's o3 December 20th results on any one of the following:
SWE-Bench Verified: 71.7%
Codeforces: 2727 Elo
AIME 2024: 96.7%
GPQA Diamond: 87.7%
Frontier Math: 25.2%
ARC-AGI Semi-Private: 87.5%
Aggressive test time scaling is allowed. Pass@1, as this appears to be what OpenAI did (but I'm not totally sure this makes the most sense, or what to do if this is ambiguous). Benchmark contamination is a concern, but this market will resolve based on stated performance, whether or not benchmark contamination is suspected.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ247 | |
| 2 | Ṁ100 | |
| 3 | Ṁ26 | |
| 4 | Ṁ24 | |
| 5 | Ṁ15 |
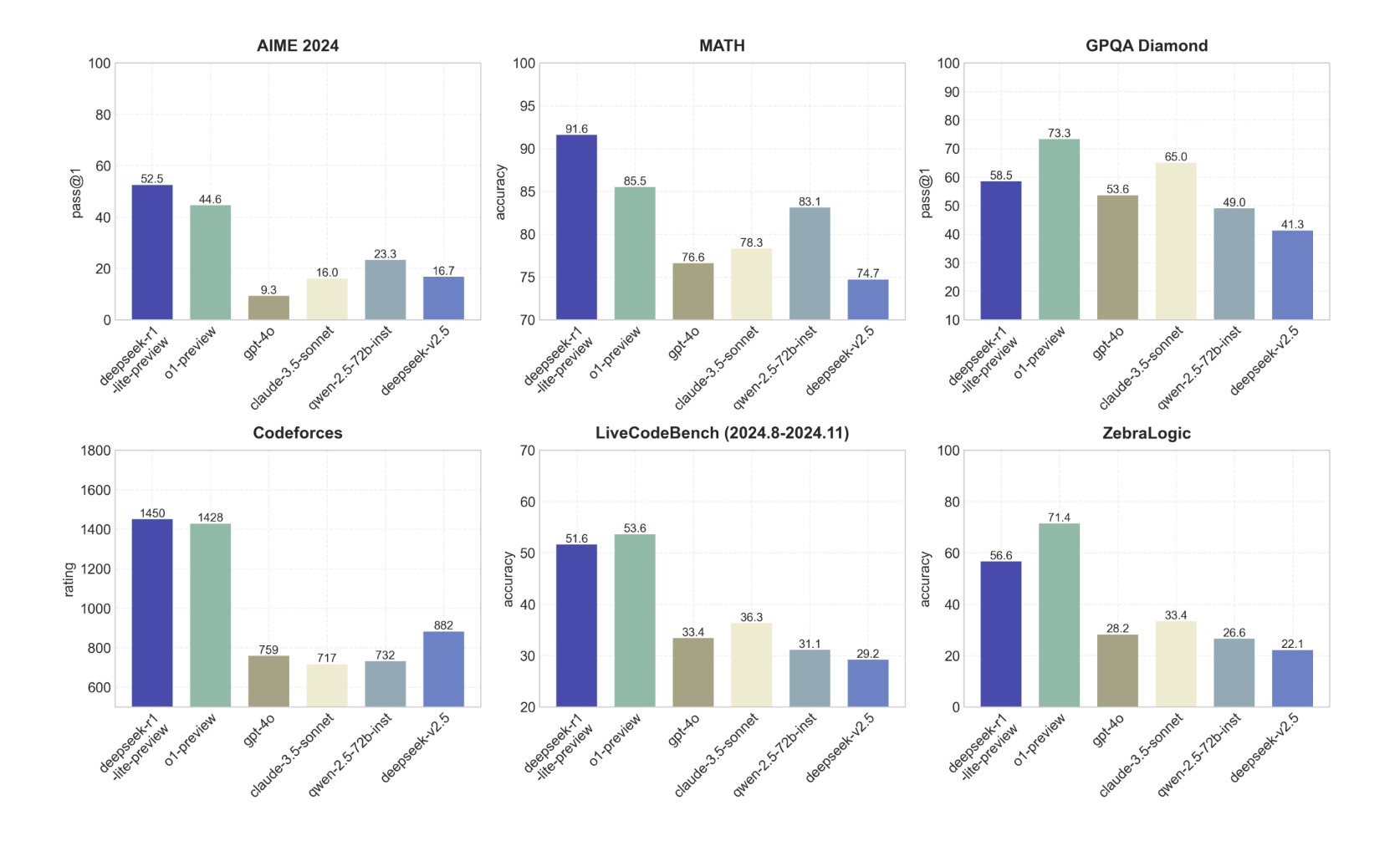
DeepSeek-R1 paper is out. Per the reported benchmark scores, this model is considerably better than DeepSeek-R1-Lite-Preview (Nov 20, 2024) but still falls substantially short of o3 on each of the market resolution scores (first score is DeepSeek-R1, second score is o3 score and market resolution target; Table 4):
SWE-Bench Verified: 49.2 < 71.7%
Codeforces: 2029 < 2727 Elo
AIME 2024: 79.8 < 96.7%
GPQA Diamond: 71.5 < 87.7%
Frontier Math: NA; 25.2%
ARC-AGI Semi-Private: NA; 87.5%
It looks like DeepSeek is going to release a new base model now / in the next couple days. The chat version of it has early results on the Aider coding benchmark which are slightly above 3.5-sonnet (below o1). They are a pretty substantial improvement from DeepSeek Chat V2.5 (17.8% --> 48.4%). That is, it seems like they're recently working with a non-RL model which is much better than the previous one.
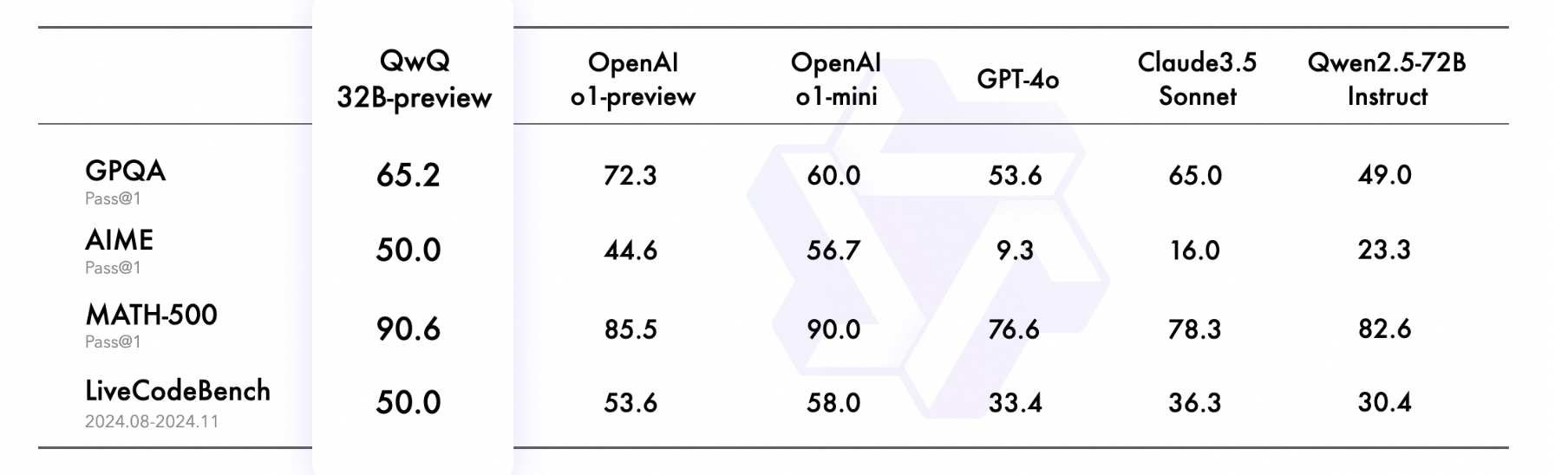
DeepSeek's previous reasoning model, deepseek-r1-lite-preview does well on many benchmarks:
That model is likely based on either 2.5, or potentially even a smaller model (rumor that it's a smaller model).
So the update here is: they have shown that they can do the RL thing and get decent results, we now have strong evidence that they have stronger base models to apply this to which they have not yet done publicly. It's still a real time crunch to see if they can get that done by end of January, and it's not clear it will match o3 performance, but it seems plausible IMO.