GQPA dataset here: https://arxiv.org/abs/2311.12022
"Human expert" means 74%.
Currently, GPT-4 gets 39%.
The LLM is allowed to use external tools (e.g. Google, Wolfram Alpha).
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ1,198 | |
| 2 | Ṁ880 | |
| 3 | Ṁ731 | |
| 4 | Ṁ621 | |
| 5 | Ṁ605 |
People are also trading
@gabrieldwu Agreed. We're well past the 81% which I called as the reasonable threshold to resolve this as yes.
@GabrielWu I was unable to find any third party that has ever tested the extended GPQA set, likely because the authors themselves do not recommend it (see page 7 of https://arxiv.org/pdf/2311.12022).

The lack of results likely makes this market effectively unresolvable, as neither the question nor the description clarifies how to resolve the market when it's unclear whether an LLM outperforms experts on the GPQA extended set. The absence of published results by January 1, 2025, doesn't necessarily mean no such results exist.
Moreover, the description does not specify that the GPQA extended set will—or even should—be used to evaluate LLM performance. It simply defines a "human expert" as someone scoring 74% on the GPQA extended set (when discounting clear mistakes the experts identified in retrospect) and notes that GPT-4 achieves 39% on the same benchmark. Even if the intention were to use the 74% score on GPQA extended for resolution, this would imply that LLMs should also have the opportunity to identify their errors retrospectively, further complicating the resolution.
Given these considerations, it seems reasonable to use the GPQA main or diamond set for evaluating LLM performance on equal terms with human experts. The market's question and description neither mandate the unrecommended use of GPQA extended, nor would it be in the spirit of the question to do so.
@ChaosIsALadder Thanks for this, I'm convinced. I'll do this based off of Diamond. So should be resolved YES due to o1?
@gabrieldwu Potentially? They claim in their writeup that they beat the human baseline on the diamond set, but they claim the human baseline is lower than the creators of the GPQA test.
In any case they are either already over the line or extremely close!
@gabrieldwu It can be resolved YES. Although the creators of GPQA report a score of 81.3% on the diamond set, this score represents only an upper bound on expert performance due to selection bias in the main and diamond sets (see page 6 of https://arxiv.org/pdf/2311.12022).
OpenAI, on the other hand, independently hired PhDs to obtain an unbiased score of 69.7%, which o1 surpassed by a large margin (see https://openai.com/index/learning-to-reason-with-llms).

OpenAI even employed more qualified experts (all with PhDs, compared to some of the GPQA paper's experts who were still pursuing one), so there is no doubt that o1 has won on GPQA diamond.
@ChaosIsALadder while obviously impressive, beating a hired set of experts is not the question here. Nor do I even think that's the markets' interpretation - Sonnet pulled 67.2% in GPQA diamond (majority over 32) - market wouldn't be at only 50% with 5 months to go with a mere 69.7% goal.
The subtitle and early comments explicitly define this as extended beats 74%. That is a very high bar.
If a model comes out beating 81.3% on diamond, that's reasonable to resolve yes. Right now, there's too much uncertainty if a model can actually beat 74% on extended
@Usaar33 First of all, the unbiased expert score of 69.7% was unknown until OpenAI actually tested it and published the result a few days ago, so it couldn't have affected this market. The market went up immediately after it was published. Still, I do agree that if o1 would have barely exceeded 69.7%, it probably wouldn't have qualified due to the remaining uncertainty. However, it achieves 78.3%. Neither the 74% on extended nor the 81.3% on diamond hold real significance, as the former is, despite the early comments, not suitable as a resolution criterion, and the latter is not the real score achieved by human experts but rather a biased statistical artifact.
as the former is, despite the early comments, not suitable as a resolution criterion
I don't see why a question should adopt a radically simpler resolution criteria because the stated one is "not suitable". Technically, this is suitable - just run the extended test set against SOTA models. If no one wants to do that, oh well, annul the question.
@Usaar33 Simply running the unrecommended and costly extended test is not enough. You would also need to discount for clear mistakes the AI identifies in retrospect once it knows the correct answer. This makes the test both vastly more expensive and highly unlikely to yield a different result from the diamond set. That's why no one has tested the extended set in the past two years, and no will.
Since neither the question nor the description mandate the extended set, annulling the market is probably wrong. Comments are just part of the discussion and are not binding as long as the creator has not updated the market itself.
@gabrieldwu Yeah, seems like o1 is an LLM and the numbers are already over the human line according to your link.
@RyanGreenblatt According to Perplexity, diamond is harder:
What is GPQA Extended vs. GPQA Diamond?
GPQA (Graduate-Level Google-Proof Q&A Benchmark) is a challenging dataset designed to evaluate the capabilities of large language models on graduate-level questions across biology, physics, and chemistry. There are different variations of the GPQA dataset with varying numbers of questions:
1. GPQA Extended: This version contains 546 multiple-choice questions[1].
2. GPQA Main: The main dataset comprises 448 multiple-choice questions[1].
3. GPQA Diamond: This is a subset of 198 questions from the main dataset[1][2]. The Diamond set focuses on questions where domain experts agree but experts in other domains struggle despite extended effort and internet access[2].
The Diamond set is considered particularly challenging and is often used for evaluating top-performing AI models. For example, recent leaderboards show models like Claude 3.5 Sonnet achieving 59.4% accuracy on the Diamond set using zero-shot chain-of-thought reasoning[1].
The different versions of GPQA allow researchers to evaluate models on datasets of varying sizes and difficulties, with the Diamond set representing the most challenging subset of questions.
Citations:
[1] GPQA: A Graduate-Level Google-Proof Q&A Benchmark - Klu.ai https://klu.ai/glossary/gpqa-eval
[2] Many-Shot In-Context Learning - arXiv https://arxiv.org/html/2404.11018v1
[3] [PDF] GPQA - arXiv https://arxiv.org/pdf/2311.12022.pdf
[4] Diamond Education https://jamesdiamondjewelry.com/diamondeducation/
[5] The response is too short to extract answer on GPQA. What should I ... https://github.com/EleutherAI/lm-evaluation-harness/issues/2081
[6] Claude 3 gets ~60% accuracy on GPQA : r/singularity - Reddit https://www.reddit.com/r/singularity/comments/1b6ziob/claude_3_gets_60_accuracy_on_gpqa/
[7] GPQA: A Graduate-Level Google-Proof Q&A Benchmark - GitHub https://github.com/idavidrein/gpqa/activity
[8] "GPQA: A Graduate-Level Google-Proof Q&A Benchmark", Rein et al ... https://www.reddit.com/r/mlscaling/comments/18409uu/gpqa_a_graduatelevel_goo
gleproof_qa_benchmark/
I think diamond is meant to be ~uncontroversial not hard, and extended includes controversial questions as well? I'm at maybe 95% that o1 plus web search can do extended superhumanly if someone tried it, but at less than 25% that someone will bother to verify this unless they do so specifically for this market?
@Fay42 Ooh interesting! So this market is kind of implicitly saying "and someone bothers to test on the extended set".
@Fay42 @GabrielWu What do you think? According to your link, with maximum scaffolding, o1 got up to 93% on GPQA Diamond.
If no one happens to run o1 on the extended set, does this resolve NO?
@ChrisPrichard Perplexity can hallucinate a lot. I don't see how diamond is "harder". Gpt-4 scores are similar on extended and diamond in the original papers. In the paper, experts do better in diamond than extended (reverse for non-experts).
74% isn't even "human expert" level of extended - that's the objectivity limit of the test set itself.
If anything, a model performing well should do better on diamond because that has a higher ceiling of objectivity.
@Usaar33 Looks like you're right that the diamond set is easier for experts (probably higher quality correctness of answers?)!
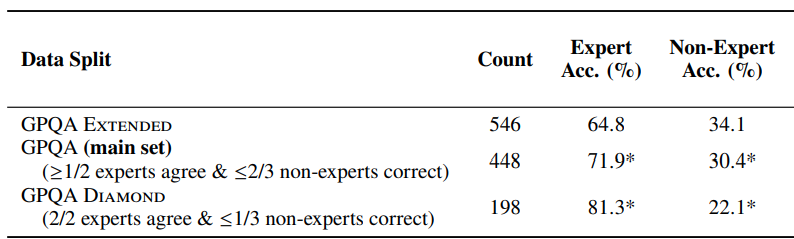
That table from the original paper (https://arxiv.org/pdf/2311.12022). It seems that o1 did indeed beat the 81.3% baseline in the diamond set.
@Usaar33 You're right! I misread the section of the paper that was talking about a Math result and thought it was the GPQA. My bad!
They do claim that they beat the human baseline on GPQA with their own testers, but that doesn't seem as trustworthy:
"We also evaluated o1 on GPQA diamond, a difficult intelligence benchmark which tests for expertise in chemistry, physics and biology. In order to compare models to humans, we recruited experts with PhDs to answer GPQA-diamond questions. We found that o1 surpassed the performance of those human experts, becoming the first model to do so on this benchmark."
If no one happens to run o1 on the extended set, does this resolve NO?
If this happens, I'll use my best judgement at resolution time and extrapolate from the Diamond scores. (I expect to resolve this YES, but have sold all of my shares and won't bet anymore for objectivity).
@gabrieldwu I don't think such an extrapolation is currently possible. We don't know comparative performance on each set at higher accuracy scores .
Looks like o1-pro is at 79% diamond. I would guess we're not going to beat 81.3% by EOY making this question ambiguous in resolution