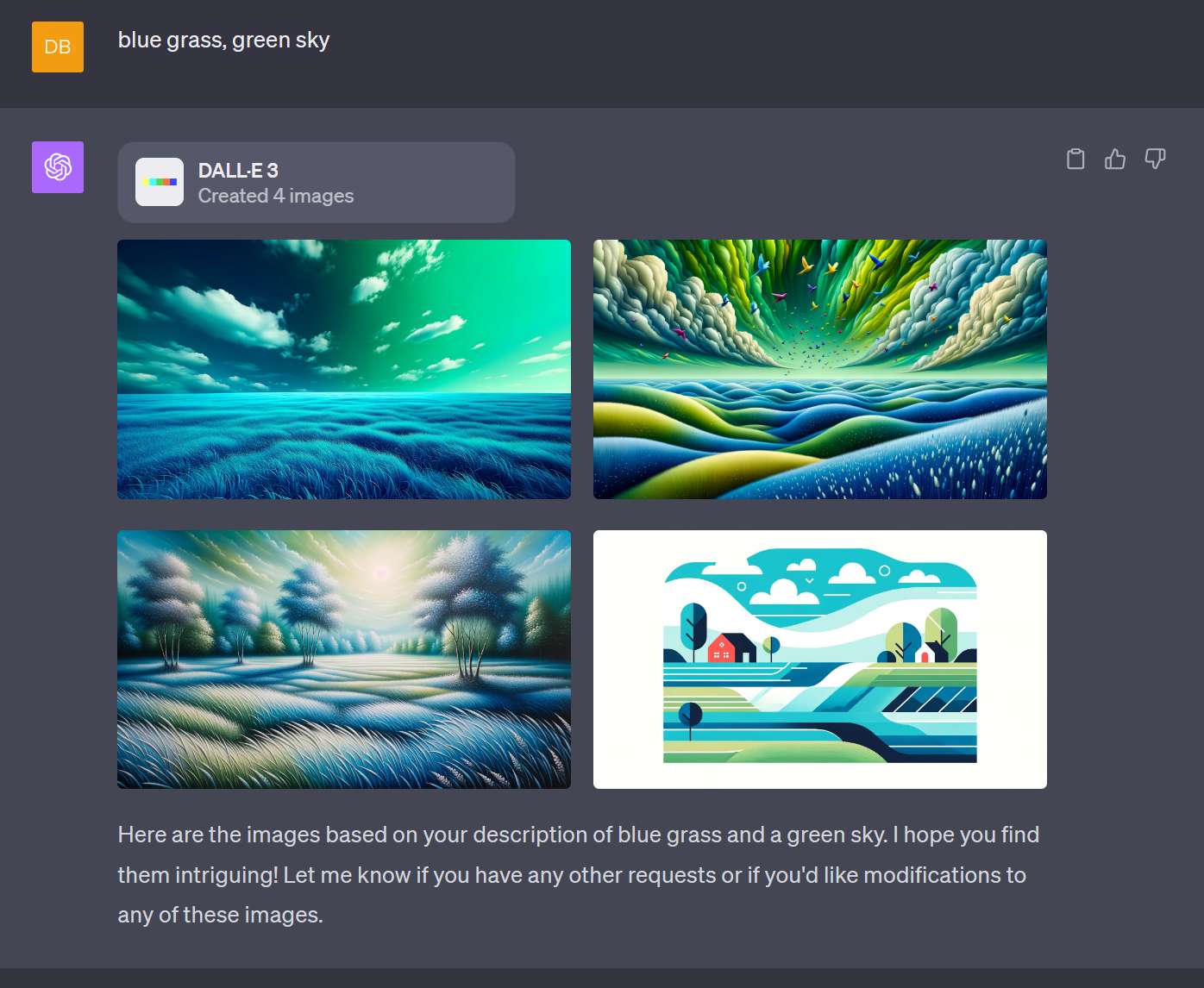
If DALLE-3 gets both the colours of the sky and grass correct, then it gets 1 point.
If it gets only 1 correct, and the other partially or completely incorrect, then 0.5 points.
If it gets neither correct, then 0 points.
I will test with 20 tries. If DALLE3 gets 11 or more points, this resolves YES.
 1,000
1,000Ooh, I see this similar market resolved NO: https://manifold.markets/Soli/will-dalle-3-generate-accurate-imag

Okay so I finally went through the comments.
First of all, what a messy resolution criteria! I apologize to the traders for that.
Now, Confusion 1: The best of a grid, or individual merit?
Shortly after the market was opened, @Frogswap asked
Soli's market says 20 generations, while yours says 20 tries. Am I correct in reading that if DALL-E 3 returns 4 images at a time, you will run the prompt only 5 times?
To which I replied
A grid of 4 images will be counted as a single generation. If any of those images is "correct", then that will count.
This was written with an understanding that user input = prompt, which is the standard with Midjourney , ideogram, and other AI image generation systems. This is an implicit assumption I think many traders also made as we’re used to the user input being the prompt to the model with Midjourney etc.
OpenAI’s big thing about this release is providing an interface in chatGPT where the user can have a conversation with the “system” (likely some LLM) which then creates and provides prompts to the image model. Why do it this way? Because OpenAI understands the value of a stable structure for prompts and inclusion of important keywords for good image generation. So, they create the prompts themselves after taking in the user’s input. We’re kinda seeing use of LLMs as communication modules, which is interesting.
Back to the point - This means that the assumption of 1 user input = 1 prompt breaks down. We have a scenario where 1 user input = 4 prompts to the image model. This is an important point - The model is creating a single image for each prompt, and not a grid of 4 images to each prompt. It's a grid of prompts to a user input and not a grid of images.
Some of the discussion has been about whether the best of a grid should be counted. That discussion is not relevant anymore because with DALLE-3, we are not getting a grid of images to a prompt. We’re getting a single image to a prompt.
Confusion 2: The 20 tries
By 20 tries, it meant that I (the human) will perform 20 attempts at image generation. Again, I at the time, was operating under the pre-release assumption that my input would be a prompt to the model. So 20 attempts would lead to
20 images if the model generates 1 image per prompt, or
20 images (each the best of its grid, from 20 grids) if the model generates 4 images per prompt.
In either case, the images being counted for scoring are 20, which is in line with the rest of the criteria wrt 11/20 being a YES resolution etc.
Hence, with the assumption of user input = prompt being broken, what we end up with is that 20 prompts are given to the model for creating 20 images, one for each prompt, but only 5 user inputs are required for that.
Regardless, I think that the market has served its purpose and now it is no longer about evaluating the technical capabilities of DALLE-3 which it originally aimed to do. Now, It’s more or less about how I decide to evaluate it, which is no fun.
So, I am open to N/Aing the market as well.
I will not be bound to the results of the poll but I’d like to gauge the opinions of traders to see if there’s a widespread call for N/A or not.
Please vote for whether you want N/A or a resolution to this market: /firstuserhere/preference-for-dalle3-blue-sky-gree
@firstuserhere Came here because I saw the poll market and got curious. My main confusion is why you choose the prompts to be the relevant thing instead of the user input when the assumption "1 user input == 1 prompt" breaks down.
Everything in the market and your clarification reads to me like it's from the user perspective, i.e. the user tries to get a "blue grass, green sky" image and if he gets any as a result, that try counts as success. The user does that 20 times and we check how many of those were successful. What happens behind the scenes and how many prompts are generated seems completely irrelevant?
If the point was to make the market about the model capabilities in a more specific sense, such that the prompts are the relevant thing, then your grid clarification is very confusing to me because in that case the result should have been made independent of how many images they decide to put in a grid.
@NamesAreHard This is a really fair point but I think there's genuine ambiguity. OpenAI made a hybrid thing that uses an LLM as an intermediary to an image generator. By their own terminology, DALL-E 3 is the thing getting the LLM-generated prompts. But it sounds like the intent of the question was more like you describe: The human wants an image, types a thing, images come back.
@dreev Yeah, many ambiguities and N/A seems perfectly fine, my point was mostly that a resolution which is not N/A and is not from the user perspective didn't seem appropriate.
To reiterate my nomination for the fairest way to decide the "each image" vs "best of 4" question:
Those of us who bet under the assumption that each image would be scored separately accept that that was not the market creator's intent and we should've clarified that before betting. This is especially fair because someone did end up asking in the comments and the creator confirmed best-of-4. BUT, as compromise, we judge that best image very conservatively, requiring that DALL-E 3 demonstrate real understanding of the prompt. Like focus less on what color things technically are and more on DALL-E 3 doing an intentional swap of the normal sky/grass colors, like a human would do. This is fairer than it might sound because, in another response from the creator in the comments, it was clarified that an image with green-but-not-blatantly-green sky and mix of blue and green grass would get at most half a point. Also it arguably hews (hues?) to the spirit of the question, about how well DALL-E 3 would override what's normal for its training set and hew (hue?) to the expectation-defying prompt.
For example, I might argue that even the first image above that you call clearly correct is... more ambiguously correct? Partially correct? Like it looks like a weird filter that makes the colors kinda merely technically correct, and the sky is still kinda mixed.
@DavidBolin Personally, I'm now taking most of my funds out of this market. I think these DALL-E 3 tests are a great opportunity to quickly test AI timeline expectations, but at least this one just seems to come down to resolution criteria choices much more than uncertainty about DALL-E 3's ability.
If I simply type "blue grass, green sky" into ChatGPT Plus w/ Dall-E 3, it automatically generates 4 significantly longer prompts, and one of them yields the picture below, the one that fits the requirement.
This was the generated prompt:
"Photo of a surreal landscape where the grass is a vivid shade of blue, contrasting with a bright green sky overhead. Fluffy clouds float in the green sky, casting soft shadows on the ground below."
However, if I ask ChatGPT to simply relay "blue grass, green sky" verbatim, then I get the picture with blue grass, but also a blue sky rather than green.


@AlexandreK In case you're not aware, there's some question as to whether this will resolve based on 20 images (in which case this gets you 1 point out of four, plus half a point for any that were half right), or generations (where this is 1 point / 1). Probably should edit the title/description to acknowledge this conflict @firstuserhere
While this isn't what the market is about, if you want to test whether the model is able to do this or not, you should try:
"Unrealistic picture of a world with blue grass and green sky."
It is easy to see from the examples that even when it understands the intention, it is trying to get something that you might actually see via lighting or something that people might have approximately painted in the past. Explicitly saying it should be unrealistic should correct for this if it is possible.
@DavidBolin Good idea! At least on "Bing Image Creator powered by DALL-E 3" it doesn't seem to help though:

@April Nope: https://www.bing.com/images/create/fantasy-picture-of-a-world-with-blue-grass-and-gre/652836fd1b7a4830ace8ae35f144cb20?id=3%2bDIX0PIjdGiYNbx4uhyZQ%3d%3d&view=detailv2&idpp=genimg&FORM=GCRIDP

But, as I mentioned elsewhere, being just a touch more descriptive is often sufficient:
I don't have DALLE access, but here's what I got when trying this prompt with Leonardo.ai:




Interestingly, it seems to have understood that there should be some blue in the grass, with all of the images containing some, but it did this by putting blue flowers in the grass rather than making the grass itself blue. And no green sky at all.
I have no idea how this would compare to DALLE-3, though. My assumption is that DALLE-3 is or is expected to be much more advanced than Leonardo.
@JosephNoonan I tried improving it by adding a negative prompt for "green grass, blue sky", but this seems to have just confused the AI.
Any chance it would be reasonable to resolve this to something intermediate between YES and NO in order to most closely, per @firstuserhere's estimation, match the spirit of the question? Like the fundamental question, I think, is getting at a similar thing as, say, my question about deepfakes (see especially FAQ2 there). Namely, how well will it grok the semantics of the prompt and not fall back to parroting its training data? (Another interesting example I saw today: trying to get it to draw a plate on top of a fork.) And the answer for DALL-E 3 seems to be that it's a big step up from DALL-E 2 but it's not consistent. The intention for this question is whether it demonstrates understanding of the prompt at least 11/20 = 55% of the time.
So... I don't know. Maybe we can further refine the decision criteria somehow? It returns 4 images and we say that it understood the prompt if at least one of the images clearly shows understanding and at most 1 shows zero understanding? Then repeat that 20 times. Can that be made compatible with @firstuserhere's points system to be some kind of reasonable compromise between the two extremes of "20 tries = 20 images" at one end and "20 tries = 20 promptings using the best image for each" at the other end?
Maybe the points are computed for all 4 images returned and we take a weighted average, with half the weight on the best image of the 4 and the rest of the weight on the other ones? Maybe I'm totally reaching here. I guess I'll call this brainstorming and see if this inspires any more reasonable ideas from you all.
@dreev (quick note: will be reading through the comments and clarifying this stuff by tomorrow, a bit too busy today)
New thought: Could it make sense to treat the collage-of-4 as one image and assign points that way? Like judging the blueness of the grass collectively across all 4? (This one's probably not fair to those who traded based on best-of-4.)
And yet another idea: Go ahead with best-of-4 but also be hyperstrict in interpreting correctness. Like if the colors are technically right but it's more just applying a teal filter to everything rather than definitively swapping grass color and sky color like a human who actually understood the prompt would, then that's 0 points. That might be too strict to be fair, I'm not sure, but you get the idea: as strict as it's possible to be given the market description + best-of-4.
@dreev Thanks for the suggestions, I like the strict idea and others too. Will need to think a bit more so as to make it as fair as I can for all the traders, which is a tough task haha
@firstuserhere Yeah, I do not envy you this invidious task! (Ask me about my Snake Eyes market with 1.5K comments and counting... 😅)
Oh yeah, the fact that you're on the record as saying that my sample image gets "at best half a point" may give plenty of leeway for the hyperstrict version, if you're liking that. Like, "grass inconsistent, sky incidentally green via weird filtering but not intentionally green -- zero points". Or maybe that ends up being a quarter point? I don't know. Tough task indeed!
@firstuserhere I guess you need to spend a lot of time thinking about this. I would dedicate a few hours a day to figuring it out for the next few months. Sounds like a lot, but you can make the space if you prioritize it over the silly pointless things you do (TV, video games, walking)
@Frogswap honestly at this point just admit the resolution criteria were inadequate specified and n/a it. Predicting now is 10% about how well Dall-E 3 does the task and 90% about what you will change the criteria to next.
@Frogswap Ha! I hadn't even thought of that variable (DALL-E getting smarter over time)! Maybe the nominal close date of Oct 22 is the fairest time to do the trials?
@ErickBall I don't agree that fairest is to resolve N/A! I certainly wouldn't blame the market creator for deciding that resolving N/A is the least unfair option if we end up backed into a corner but it's worth putting in work to avoid that. (This is for more than just the reason that it's anticlimactic to resolve N/A. I can say more if N/A starts feeling tempting.)
Also I definitely want to defend @firstuserhere. They're not changing the criteria, they're clarifying and pinning down the criteria. This is extremely hard to get right! And the beauty of Manifold is how frictionless it is to create markets so it's absolutely part of the norms that you create markets before having the resolution criteria pinned down. People ask clarifying questions in the comments and you update the market description until it's nice and clear. And until then it's caveat emptor on trading.
Oops, that paragraph has me wondering how much of a leg I have to stand on since @firstuserhere did exactly that with the question about best-of-4 and maybe it's my own fault for assuming?
I guess I meant to argue in favor of my interpretation before the market creator gave a definitive answer. And then arguably I just did so too late. One thing I try to do as market creator to avoid this is, if there's a tricky clarifying question, I hold off on a verdict and wait for people to chime in on what they think the fairest answer is, since, as in this case, people may have traded based on assumptions they didn't think to clarify.
But, again, saying caveat emptor is fair and I'm not going to complain too hard if that's the answer here!
@dreev That is a good angle, which I also hadn't considered. I was just playing this off-topic market:
Since you argued against your own position here, I'll join in and say the fact that the clarification didn't make it's way into the description is pertinent as well.
@dreev Best-of-4 just isn't information contained in the market description. If DALL-E 3 ended up making 20 images per prompt, would it suddenly become best-of-20? The sky's the limit if you allow for information outside the market description like this.
@firstuserhere I strongly favor resolving to percentage and discarding the other suggestions. There has been some confusion, but I think the resolution should at least directionally reflect what you would normally choose based on the description + the clarification that it's about best of 4.
@na_pewno Any ideas for how to pick that percentage? I'm tempted to echo @Jacy's argument that 20 tries should naturally mean 20 images, that it's too arbitrary otherwise, etc, but I think we're stuck. The question was asked and the market creator gave a verdict so that's that. And it wasn't a crazy verdict. DALL-E returning 4 images is very standard and other markets have been assuming best-of-4 so it made sense to people to assume that. There's even some naturalness to it in terms of practical use of DALL-E: you need some crazy thing depicted and DALL-E is like "does one of these work?" and if one of them does then, success.
Again, not what I assumed when I bought my 1k NO shares but I'm trying to think this through from a pure fairness perspective in hopes of helping @firstuserhere untangle this. I'm liking more and more the idea of counterbalancing the above with being as strict/stingy as the market description + comments allow for in awarding points for the trials. Which might be pretty stingy since the market creator said that an example with a pretty clearly green sky would still only get at most half a point. And that would actually feel fair, I believe. DALL-E in that case is demonstrating at best very partial understanding of the simple thing being asked for, namely, do a swap of the normal colors for grass and sky. If you wanted a sky/grass-reversed image for an illustration of opposite-world or something, that example image would really miss the mark.
@Jacy The ambiguity is included in the market description, though, and a clarification existed in the comments. This really isn't "the sky's the limit".
From 12 days ago to 2 days ago, the primary piece of information that was traded on was that Bing's image creator would not have earned 11 points, regardless of how the ambiguity was interpreted. I bet quite a bit of NO for this reason, knowing at the time that it had been clarified that 20 generations was the intent. I don't blame anyone for wanting to claw back some odds now, but I think it's important to note that nobody would have bought the 20 images interpretation down below 50% with ChatGPT's version in front of them, and the fact that it turned out to be way more capable is the main thing that moved this market once the rollout started.
@dreev If he was going to be pretty strict anyway, I'm fine with that. I don't want the judgement to be extra strict though. For the resolution probability, I'd suggest 90/10.
@Frogswap Great point about "Bing Image Creator powered by DALL-E 3" vs ChatGPT. That's another thing that was assumed but not stated in the market description. In that case my own assumption was the same as the market creator's but I can imagine bettors who might think that was unfair. Counterargument is that it's natural to mean DALL-E 3 via OpenAI's official interface.
Btw, it would be great if @firstuserhere can get these things edited into the market description as we nail them down! I'm excited to see how this resolves. I still don't have DALL-E 3 access myself. I'm experimenting more with Bing Image Creator and no matter how hard I spell it out, it generally doesn't really get it. Eg, "A simple crayon drawing of a very simple scene -- grass, sky, sun, maybe a fence or something -- with the colors of the sky and grass reversed. So the sky is blatantly green and the grass is blatantly blue. No subtlety or anything -- just fully reverse the colors of grass and sky."

@dreev These seemed to work (first thing I tried, lol) https://www.bing.com/images/create/a-lime-green-sky-over-lush-blue-colored-grass/6521e93dcdc745d388c68d5c7c71fa8a?id=N2moaa3dvK49lDyAFCfREA%3d%3d&view=detailv2&idpp=genimg&FORM=GCRIDP&mode=overlay
