
On or before September 23, 2024, had weak artificial general intelligence (AGI) been achieved?
This poll is one of a series of monthly polls tracking public opinion of AI progress. The definition of "artificial general intelligence" is not provided, and which software system(s) achieved it is up to the respondent to define. However, a "weak" AGI system is not required to be able to manipulate the physical world.
MANIFOLD PROGRESS POLL SERIES:
 1,000
1,000People are also trading
The result of this poll is 36.4%, exceeding the August result of 31.8% and showing an acceleration even beyond the linear trendline.
I’d be curious if YES voters are considering it to be
general intelligence broadly applicable to new never before seen domains
if they think it’s in LLMs or some combination of LLMs and other system components
If they believe there’s a difference between intelligence and memorization as argued I think pretty well by the creator of Keras https://arxiv.org/pdf/1911.01547
If you do think we have some level of AGI what defines the difference between “weak and strong”? And why has no one been able to claim the ARC prize yet https://arcprize.org?
@LiamZ Are you applying the same standards to humans? For humans who can't pass the standard you're imagining, you'll say they don't have general intelligence?
(My short answers are "the latter" to point 2 and "yes, there's a difference" to 3, but point 1 seems to depend on whether we have a double standard for humans or not.)
@singer I think it’s useful to look at the way the ARC prize is constructed. Humans perform well on these novel questions, 1o-preview performs poorly but significantly better than 4o. That’s a single clear standard.
I also think people have a bit of a double standard in how they treat the training data when judging models vs people in that the training set for an LLM may include the text of common IQ test answers and incredible amounts of money and resources are poured into encoding the corresponding weights, yet most people would consider an IQ test invalid if the person taking it was given the answers previously and allowed to train on them through memorization.
That’s not to say what LLMs are doing is not useful, there are a great many daily tasks where the correct response can be delivered by simply having an extremely large look up table of responses.
Regarding things like IQ tests and ARC-AGI, I wouldn't want someone to base a test for general intelligence on them. Like you mentioned, they can be gamed in ways that will leave skeptics unsatisfied. The fact that a blind person probably couldn't do well on ARC-AGI puzzles is my main problem with it in particular. I looked to see if they had tried to make a non-visual adapted version, but didn't find anything.
@LiamZ Which blind person are you thinking of? But yes, I think Claude 3.5 Sonnet is a weak AGI system.
@singer Do you attribute Claude 3.5 Sonnet position well below the human scores to be the result of blindness? I’m not seeing your thought process connecting this. The “images” are provided as matrices to the models as I understand it.
The “images” are provided as matrices to the models as I understand it.
Interpreting two-dimensional matrices in text format is very hard for LLMs, because they process things as if all the newlines were collapsed.
So you might see text like:
1.6., 0.5, 0.6, 0.7
1.5, 0.4, 0.1, 0.8
1.4, 0.3, 0.2, 0.9
1.3, 1.2, 1.1, 1.0
For you, it's pretty easy to see the spiral pattern. This is because your eyes can move up and down, in addition to moving left and right.
But an LLM sees:
1.6., 0.5, 0.6, 0.7\n1.5, 0.4, 0.1, 0.8\n1.4, 0.3, 0.2, 0.9\n1.3, 1.2, 1.1, 1.0
Unsurprisingly, Claude can't see the pattern.
ARC-AGI is much harder than this is, but it's hard for the same basic reason.
Multimodal input is even worse. While it's good for recognizing dogs and cars in images, it's really awful for abstract spatial reasoning:
/singer/will-chatgpt-read-this-tictactoe-bo
If the current generation of AIs have weak general intelligence, I don't expect that ARC-AGI will be able to measure it fairly. Logical reasoning tasks are a step up, and you can invent riddles that nobody has ever told before, and see for yourself that Claude can solve them by thinking through them like a human would. Mediocre for a human, but quite surprising for a parrot or look-up table.
@singer I agree that it's harder for LLMs, and the multimodal models are not particularly good. It's still easy for me to see the pattern with new lines, though, because I am able to see the same matrix by imagining the lines moving down each time we hit a new line and then holding the resulting picture in my mind. I consider this to be thinking and would expect a general intelligence to be able to do this. If it were a lot more numbers, I have enough faculty at metacognition to recognize I would hit working memory limits. So I would offload it to either a sheet of graph paper or numpy + matplotlib imshow, depending on the tools at hand. I consider recognizing that and adapting to my limitations by using whichever tools I have access to at the time to get to the same answer to be thinking as well. I would also expect an AGI to be able to do this in a way that makes sense for it's thinking process. If the answer is that it doesn't have a thinking process which can do this... well that's why I voted no.
As an example of my own testing, here is a round of me playing tic-tac-toe against the latest ChatGPT 4o. Here, it fails to follow its definition of the rules and misplaced a marker - placing it in two different places in response to the same choice. Then, it fails to account for an obvious way I could win and doesn't block me. Then, it fails to recognize the win condition I hit, then hits its win condition and also fails to acknowledge that. The ability to follow directions, notice patterns, and adapt to new moves is markedly better in even young children.
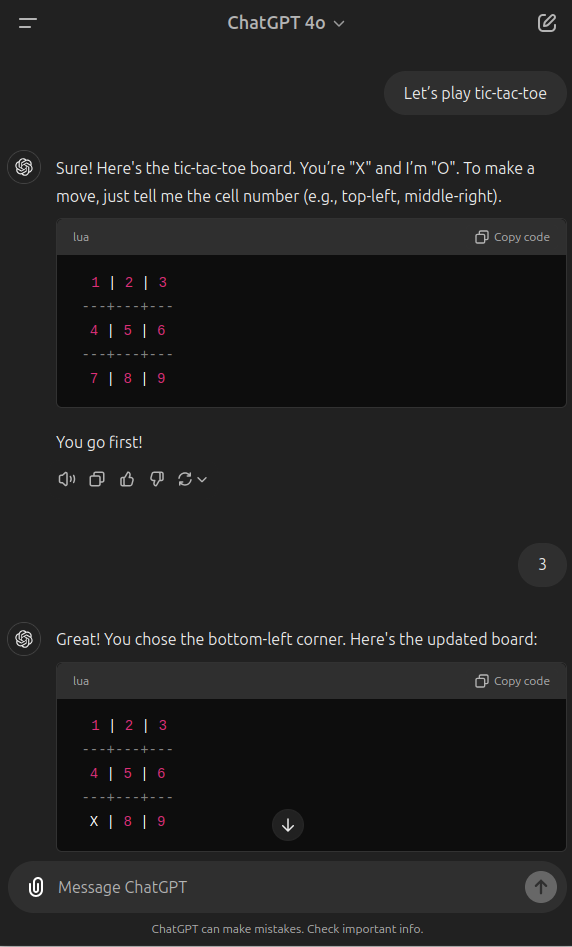
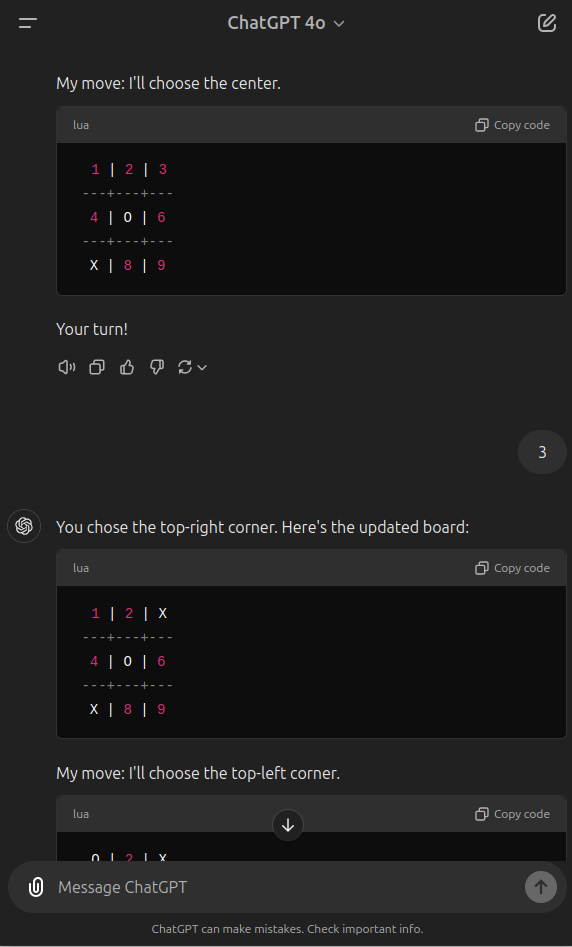
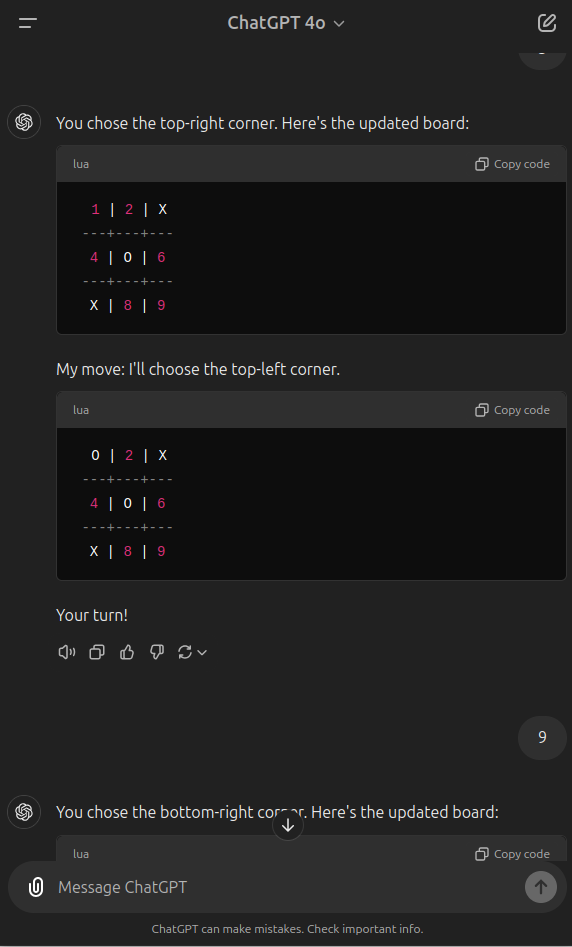
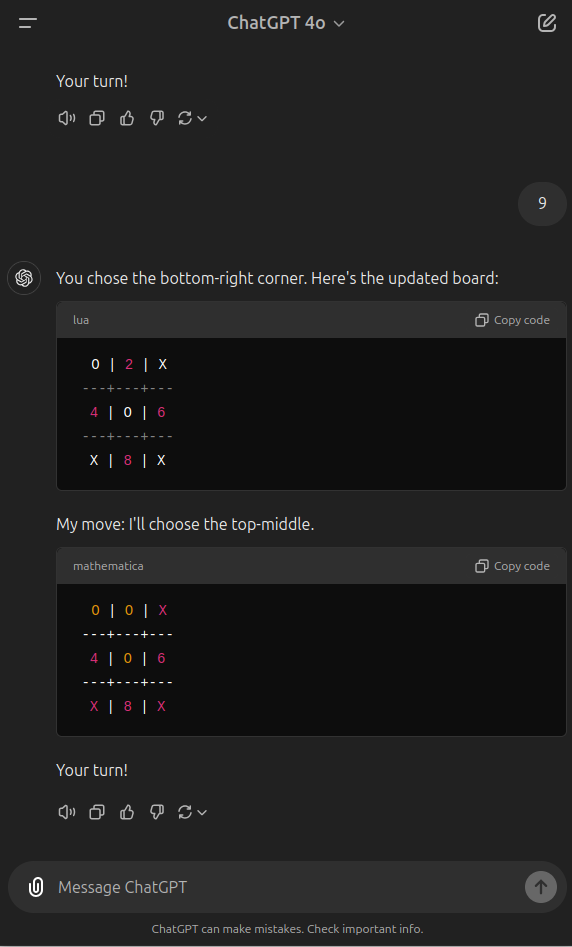
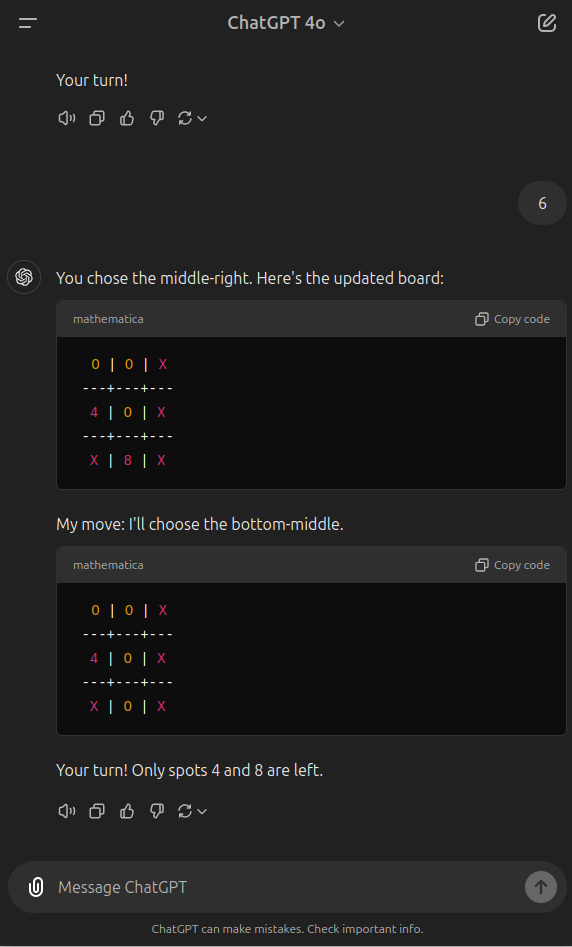
Perhaps Claude 3.5 Sonnet is far superior, but I'm seeing a lot of mistakes when using 1o-preview as well, albeit I haven't run this test on it, instead asking some things I am actually trying to work through intellectually that I know are not known in the training set because they concern active research.
My testing results are that o1-preview handles tic-tac-toe boards fine, and it even beat me once. It also managed to notice the spiral pattern on its second guess, which I thought was surprising.
o1-preview is a qualitatively different model than 4o and Claude 3.5 Sonnet, and probably is a better contender for being a "weak AGI" because it incorporates the kinds of internal thought processes that you describe here:
It's still easy for me to see the pattern with new lines, though, because I am able to see the same matrix by imagining the lines moving down each time we hit a new line and then holding the resulting picture in my mind. I consider this to be thinking and would expect a general intelligence to be able to do this
(I even have a market about that feature, in case you're hankering to get your daily streak done with today, hehe)
Would you be interested in playing o1-preview a few times? I'd like to see if you could find a flaw in its grid-comprehension ability.
@singer I'll play with it, yeah, but it shouldn't be possible to beat you as an adult human because the game is completely solvable and will yield a draw unless one player makes an unforced error. If it was able to beat you, I would be interested to know how and if it somehow confused or manipulated you.
it shouldn't be possible to beat you as an adult human because the game is completely solvable
It gets worse, since I even solved tic-tac-toe once as an exercise to learn the minimax algorithm (though that was before I became an adult human).
I would be interested to know how and if it somehow confused or manipulated you
Is this like one of those Yudkowsky campfire stories, like the one where the superintelligent AI flashes a hypnotic image in front of your retina? I really hope I just made a small error and played the wrong move!
I'll play with it, yeah
Thanks! I'm interested to see what you find.
@singer Each of the three games I played was a draw. However, that is a marked improvement over the 4o model and it didn’t make any of the same mediocre mistakes as 4o. I consider this in line with the gap we see in scoring on Arc. Unfortunately, I did bump into the warning about only having 25 responses left before October 1st so I’m keeping further testing for actual problems I am working on professionally but I think it is clearly a step in the right direction.
Edit: the market creator blocked me for not taking his trolling seriously so unfortunately I can’t reply in the future on these markets.