METR recently published an analysis called Measuring AI ability to complete long tasks.
The analysis suggests that the 50%-task-completion time horizon for the State of the Art AI agent is doubling every 7 months:
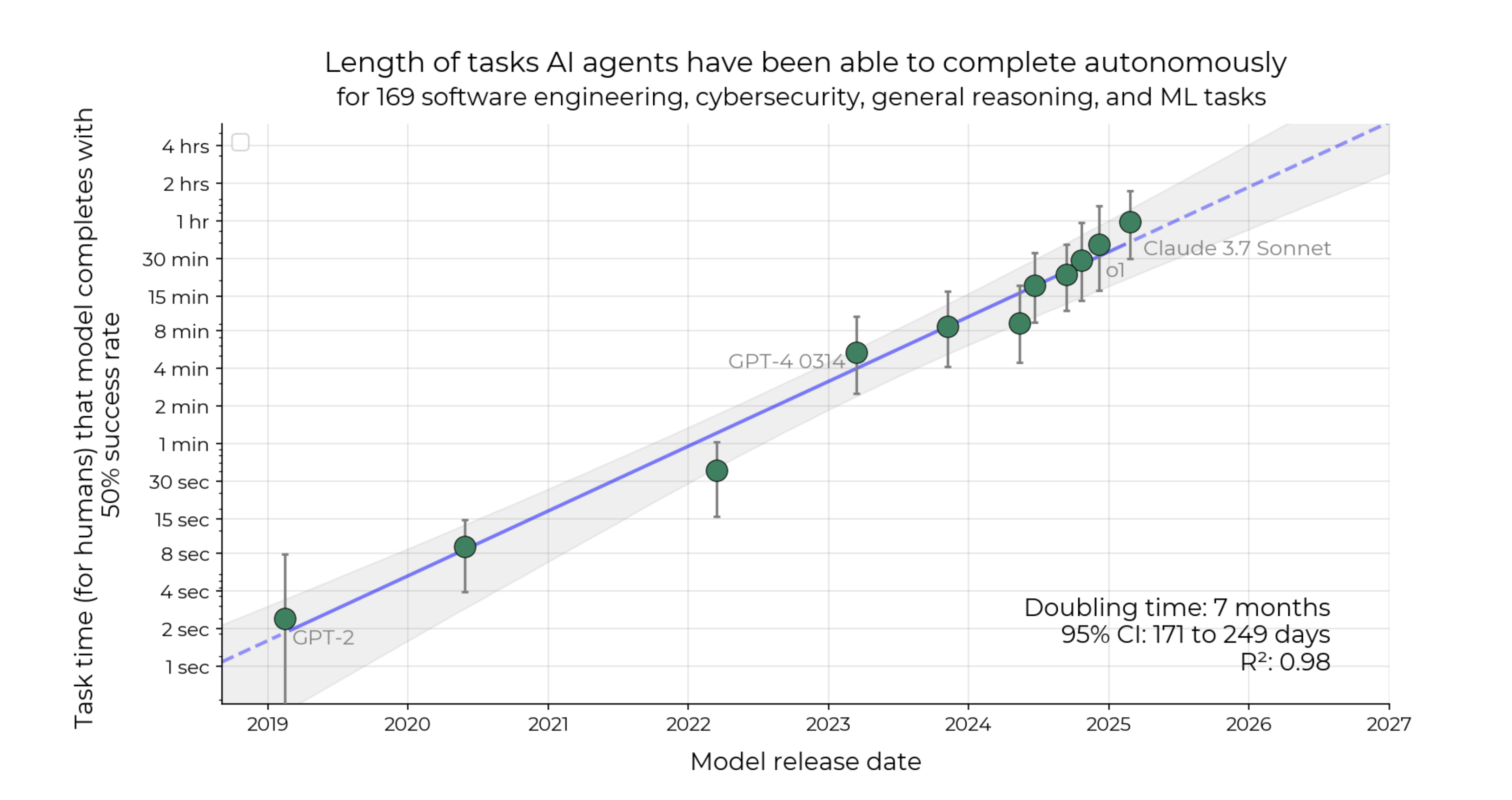
Figure 1 from the METR paper illustrates the historical exponential growth trend and the ~7 month doubling time.
Market details
This market resolves based on published data from METR (Model Evaluation & Threat Research) or a successor organization explicitly continuing this line of research using a demonstrably equivalent methodology.
Metric: The "50%-task-completion time horizon" as defined in METR's paper.
Baseline date (T0): Feb 24th 2025 (the public release of Claude 3.7 Sonnet)
Baseline State-of-the-Art (SotA) Horizon (H0): 40 minutes the value of the trend line at date T0.
Target Horizon (H1): 80 minutes (2 * H0, i.e. a single doubling).
Target Date (T1): The date on which a model is publicly accessible through for which METR (or another organization using equivalent methodology) reports a 50% task completion time horizon of at least H1 (80 minutes) using their established methodology. This date T1 is the model's public access date, not the date of the METR report itself.
Resolution Criterion
This market asks whether the next doubling of the SotA – reaching a horizon of at least 80 minutes (H1) – will occur faster than this historical average. Specifically, will the time elapsed between the effective date of the previous SotA (T0) and the date the new SotA horizon (H1) is achieved (T1) be less than 212 days (i.e. by 24th September 2025).
Market closing date
The market will close on the 24th of October 2025 to provide 30 days for METR (or another org) to run the METR analysis. It will close earlier if METR (or another org using equivalent methodology) confirm that the 80 minute 50%-task-completion time horizon is achieved before this date.
Update 2025-04-16 (PST) (AI summary of creator comment): Important Notes:
The resolution will accept a METR-evaluated model even if changes in the task set prevent a direct numerical comparison to the original baseline figures.
A model that exceeds the 80-minute threshold (for example, reaching 90 minutes) using METR’s current evaluation qualifies.
The public release date of the model is used to determine the timing criteria, so a release date that meets the requirement (as in the case of o3 on 16th April) confirms resolution.
 1,000
1,000🏅 Top traders
| # | Name | Total profit |
|---|---|---|
| 1 | Ṁ7,153 | |
| 2 | Ṁ583 | |
| 3 | Ṁ521 | |
| 4 | Ṁ488 | |
| 5 | Ṁ243 |
People are also trading
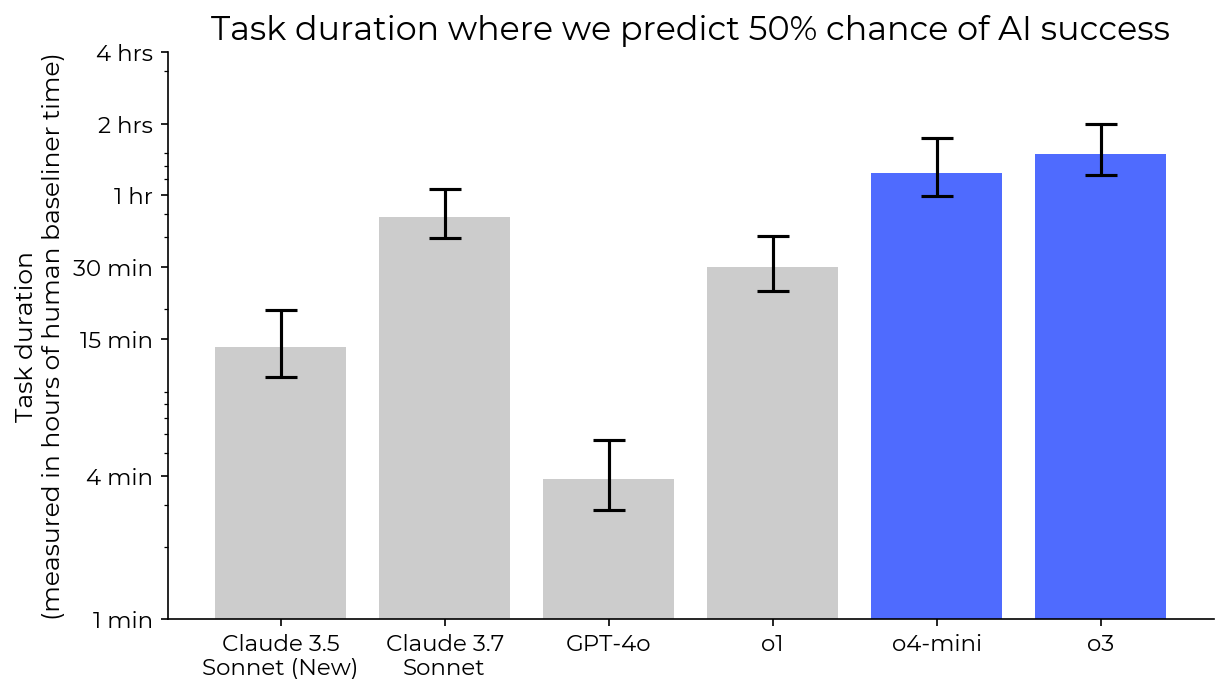
@EliLifland this is HCAST only, so not the same set of tasks as the paper, but I think HCAST makes up the majority of tasks in the paper.
I think the question criteria are ambiguous over whether this counts. e.g. it says an evaluation from a non-METR org with the same methodology (in what respects?) counts
@JoshYou Thanks for flagging.
While METR notes the task set changes prevent direct numerical comparison to the exact baseline figures used to establish the original trendline, the assessment and methodology seem sufficiently close to resolve to YES. The report shows a METR-evaluated model (o3) reaching a 90-minute time horizon (and therefore surpassing the 80-minute threshold) using METR's current evaluation. The public release date of o3 (16th April) meets the timing criteria.
@SamuelAlbanie When would the non-preliminary results have come out? Couldn't you have waited for those?
@Panfilo This is a fair question. My interpretation of the METR study is that this is sufficient evidence to resolve.
I'm not sure if there will be non-preliminary results. I'm interpreting their use of the word "preliminary" to mean something like "this is what we could achieve in 3 weeks, be warned that there may be bugs" rather than as indicative that they will continue to work directly on exactly reproducing the full task horizon set up. I could be wrong on this point. There's some ambiguity in the phrase "We are currently working to address some of these limitations, as well as prototyping novel forms of evaluations."
@Benthamite there are clearly some pros and cons to using Claude 3.7 vs the trend line. However, on balance, I agree with your point - the trend line makes more sense.
I've updated the resolution criterion to reflect this.
@SamuelAlbanie Doesn't using Claude make more sense? Imagine the extreme scenario where Claude was already far enough above the trendline that it fit the "7 month above the trendline" criteria right now. In that case, the question would automatically resolve to yes. But what we are really interested in is whether or not in 7 months we will have something "twice as good" as Claude.
@Soren I feel like if Claude was that high then we would already say that the trend would be broken. And I interpret this market to be trying to measure something like "will the trend be broken?"
Reasons in favor:
- in the METR report it is indicated that recent progress (~2024-2025) has been significantly faster than over the full timeline (~3 months/doubling instead of 7), likely due (in part) to inference time compute/reasoning
- Sonnet 3.7 is probably a last gen/Ne25-ish era model in terms of compute, but just with SotA post-training/fine-tuning, including reasoning and inference; we will be getting the new Ne26-ish SotA models (OAI, Anth, GDP, maaaybe others) in the coming months (Grok 3 is already out & ~5e26, Gemini 2.5 just released, GPT-5 is likely <7 months out, etc.)
- This whole METR time horizon trend is likely to be super-exponential, 2024-2025 discontinuity in data aside (too long for a fraction of a comment to explain)
Reasons against:
- Unclear robustness/replicability: if you read the report METR has good in-model validation and robustness, but not necessarily out-model, which they also admit explicitly.
- The trend holds over long time horizons with many data point falling above but also below the line of best fit: new model releases this year could easily fall below
- If a model is released that has the required capabilities within the required time frame, it's time horizon capability might not be demonstrated/measured before this market closes (could be a window as low as ~1 month)
Overall, seems likely to be significantly >50%, so great deal atm