
Introduction
Connections is a unique, playful semantic game that changes each day. It occupies a fairly different space than most of the other games being effectively challenged by Large Language Models on Manifold and elsewhere, being at times both humorous and varyingly abstract. But, it does rely entirely on a simple structure of English text, and only features sixteen terms at a time with up to 3 failed guesses forgiven per day. If you're unfamiliar, play it for a few days!
I think Connections would make a good mini-benchmark of how much progress LLMs make in 2024. So, if a prompt and LLM combo is discovered and posted in this market, and folks are able to reproduce its success, I will resolve this Yes and it'll be a tiny blip on our AI timelines. I will need some obvious leeway for edge cases and clarifications as things progress, to prevent a dumb oversight from ruining the market. I will not be submitting to this market, but will bet since the resolution should be independently verifiable.
Standards
-The prompt must obey the fixed/general prompt rules from Mira's Sudoku market, excepting those parts that refer specifically to Sudoku and GPT-4.
-The information from a day's Connections puzzle may be fed all at once in any format to the LLM, and the pass/fail of each guess generated may be fed as a yes/no/one away as long as no other information is provided.
-The prompt must succeed on at least 16 out of 20 randomly selected Connections puzzles from the archive available here, or the best available archive at the time it is submitted.
-Successful replication must then occur across three more samples of 20 puzzles in a row, all of which start with a fresh instance and at least one of which is entered by a different human. This is both to verify the success, and to prevent a brute force fluke from fully automated models.
-Since unlike the Sudoku market this is not limited to GPT-4, any prompt of any format for any LLM that is released before the end of 2024 is legal, so long as it doesn't try to sneak in the solution or otherwise undermine the spirit of the market.
Update 2024-12-12 (PST): - The LLM only needs to correctly group the 16 words into their respective groups of 4. It does not need to identify or name the category labels for each group. (AI summary of creator comment)
Update 2025-01-01 (PST) (AI summary of creator comment): - Independent verification: Success must be confirmed by multiple traders using separate instances of the LLM.
Consistent prompt usage: The same prompt must be utilized across different users to achieve successful puzzle solving.
Resolution timeline extension: Resolution may be delayed until the end of January to accommodate verification processes.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ4,236 | |
| 2 | Ṁ3,368 | |
| 3 | Ṁ1,398 | |
| 4 | Ṁ1,288 | |
| 5 | Ṁ925 |
People are also trading
o1 hasn't failed at any of the ~dozen I've tried over the past weeks (a handful of times it's made a reasonable enough first guess and then needs a second).
No particularly special prompting - literally just 'solve this NYT connections', and then if it fails, '[A, B, C, D] was correct. [W, X, Y, Z] was incorrect.'
https://mikehearn.notion.site/155c9175d23480bf9720cba20980f539?v=77fbc74b44bf4ccf9172cabe2b4db7b8 has it getting o1 pro 14/15 on the first attempt [and o1 got it on the second attempt for the one it missed when I tried, for 15/15]. He's "stopped tracking these because the results ended up pretty clear. o1 Pro is nearly perfect".
The archive above got taken down, but to get to 16, I just tested today's, which o1 got. This is obviously playing a bit fast and loose with 'random' (and the assumption that o1 pro >> o1; although I could quickly feed o1 the couple that it failed to ensure it does get them within the subsequent allowed trys if people doubt this), but at this point I'm 99%+ confident that o1 (let alone o1 pro/o1 high) would meet the bar for this market.
If push comes to shove I'm happy to feed in 16-20 randomly selected connections into o1 if someone's an NYT pro subscriber or whatever and can get their hands on them. But I'm curious if any no-holders are holding out there's a chance that o1 actually can't meet this?
@CalebW As a matter of principal, if you can hand off this combination to a second party to confirm it, I will resolve Yes. I personally haven't used o1 and haven't held in this market in some time.
@Panfilo This is not limited to Caleb, by the way. Any @traders who can verify that they and a separate instance run by a separate person can both get a net success with the same prompt using an LLM released in 2024 (or earlier). I see multiple people confidently using o1, but for the resolution criteria to be met, we do need that redundant success with the same prompt. Just a technicality, but an important one. I am willing to hold off resolution for all of January in case folks are busy, but the market will remain closed for consistency.
@Panfilo I just tried o1 with Connections (1/1/25 edition) and was impressed to see it perfectly solve the puzzle. But my prompt was a little weird. Could we maybe create a template for a prompt and then all try it on the same day (starting on 1/2/25 for example) and share our findings? Want to propose a simple template?
@Panfilo The question isn't whether "an LLM released in 2024 (or earlier)" can do this. It's whether a "prompt" can do this by the end of 2024.
Verification should only be happening using prompts known to have been written before, well, today — not LLMs released before today.
@jpoet If you need a standardized prompt that was written before January 1, here's one of my old chats: https://chatgpt.com/c/673fd241-f174-8010-830b-9a98eaafea80
```
Sort these words into 4 categories with 4 words each.
PLAY BAY STIR CHAIN TREE STREAM BARK RUN HOWL GARNISH AIR PYRAMID MUDDLE LADDER SNARL STRAIN
```
Here's a screenshot that proves that the chat was on November 21:
@jpoet Yes, the original description is still the standard, I was just prompting (lol) folks to actually show their work.
@jpoet @Panfilo to make my position on resolution clearer:
- given the evidence I laid out above and the current market price, I think this should presumptively resolve yes absent counterevidence
- i view myself as having planted the flag for the following prompting strategy: 'just 'solve this NYT connections [puzzle follows]', and then if it fails, '[A, B, C, D] was correct. [W, X, Y, Z] was incorrect.'' etc
- with this said, turns out I can access the NYT archive, so I just would need agreed upon dates to run
In the meantime, here's o1-mini oneshotting today's: https://chatgpt.com/share/6786a275-12d8-8009-907e-200f8189624a
@CalebW Well my position is still that we need a direct duplication and it sounds like it shouldn't be that tough now that o1 seems to have overshot the necessary intelligence. @CDBiddulph @jpoet @Jx Would any of you three volunteer to work with CalebW to resolve? I want to be crystal clear that I will be sticking to this standard and there are just over two weeks remaining to confirm it!
@Panfilo Sure. @CalebW If you have access to the NYT archive, could you send a pastebin or something containing a list of 20 puzzles? To make it effectively "random" without going too far back into the past (to avoid the possibility that the puzzles ended up in the training data), how about the puzzle every third day starting from today? January 14, January 11, January 8, etc. I'll post o1's responses after I run them all, so everyone can see that the puzzles are the correct ones. Does that sound reasonable to both of you?
@CDBiddulph Quick and dirty copy and paste: https://docs.google.com/document/d/1ZrqHh1gWRmwyE4GuTIZ8-chH2_S-Zf2xxs7NaX4a95A/edit?usp=sharing
Presumably ChatGPT w/ code interpreter or whatver can clean up and randomize them (out of the correct order) as needed 😁
@CalebW Okay, done. This was actually closer than I thought - o1 got exactly 16/20 correct, so this market should resolve YES.
Feel free to check my work below:
Failed:
https://chatgpt.com/share/67897c83-1f54-8010-83f0-50c1e64c0282
https://chatgpt.com/share/67897cf7-7084-8010-bf6c-77852c922926
https://chatgpt.com/share/67897d28-915c-8010-a522-2d8b34106fc5 (gets very defensive about the "BEANS" answer lol)
https://chatgpt.com/share/678982e6-92ec-8010-9e33-0f4e5b342573
Succeeded:
https://chatgpt.com/share/67897c34-1784-8010-bd40-bca715ffbcd0
https://chatgpt.com/share/67897c4a-10d0-8010-a18e-780932b4169c
https://chatgpt.com/share/67897c53-9fc8-8010-a008-6ff03451e888
https://chatgpt.com/share/67897c60-57d0-8010-9422-0be5222ab757
https://chatgpt.com/share/67897c72-2ba4-8010-9aea-34babda872ec
https://chatgpt.com/share/67897cb9-3248-8010-9ccb-91d4e43ade73
https://chatgpt.com/share/67897cc4-8850-8010-928d-bc932fdad1a9
https://chatgpt.com/share/6789818d-2edc-8010-ab1a-39e41e297f3d
https://chatgpt.com/share/678981a7-1a14-8010-844d-1ab36d1b59bc
https://chatgpt.com/share/678981c0-c580-8010-983d-4339c5c5ab6f
https://chatgpt.com/share/678981ce-3000-8010-9c29-ca183bb345ab
https://chatgpt.com/share/67898204-ee3c-8010-b61a-622119c16810
https://chatgpt.com/share/67898227-f378-8010-90ea-22d9edbb3f14
https://chatgpt.com/share/6789828e-4cec-8010-9b84-69ab96b4b0a9
https://chatgpt.com/share/678982af-96f8-8010-84c7-63a1e2676fab
https://chatgpt.com/share/67898420-cfa8-8010-80af-59f2d09d8772


@Panfilo sorry if this is answered somewhere else but tbc, this market is about whether the AI can place the 16 words in the right groups of 4, not whether they can guess the name of the categories on top of that?
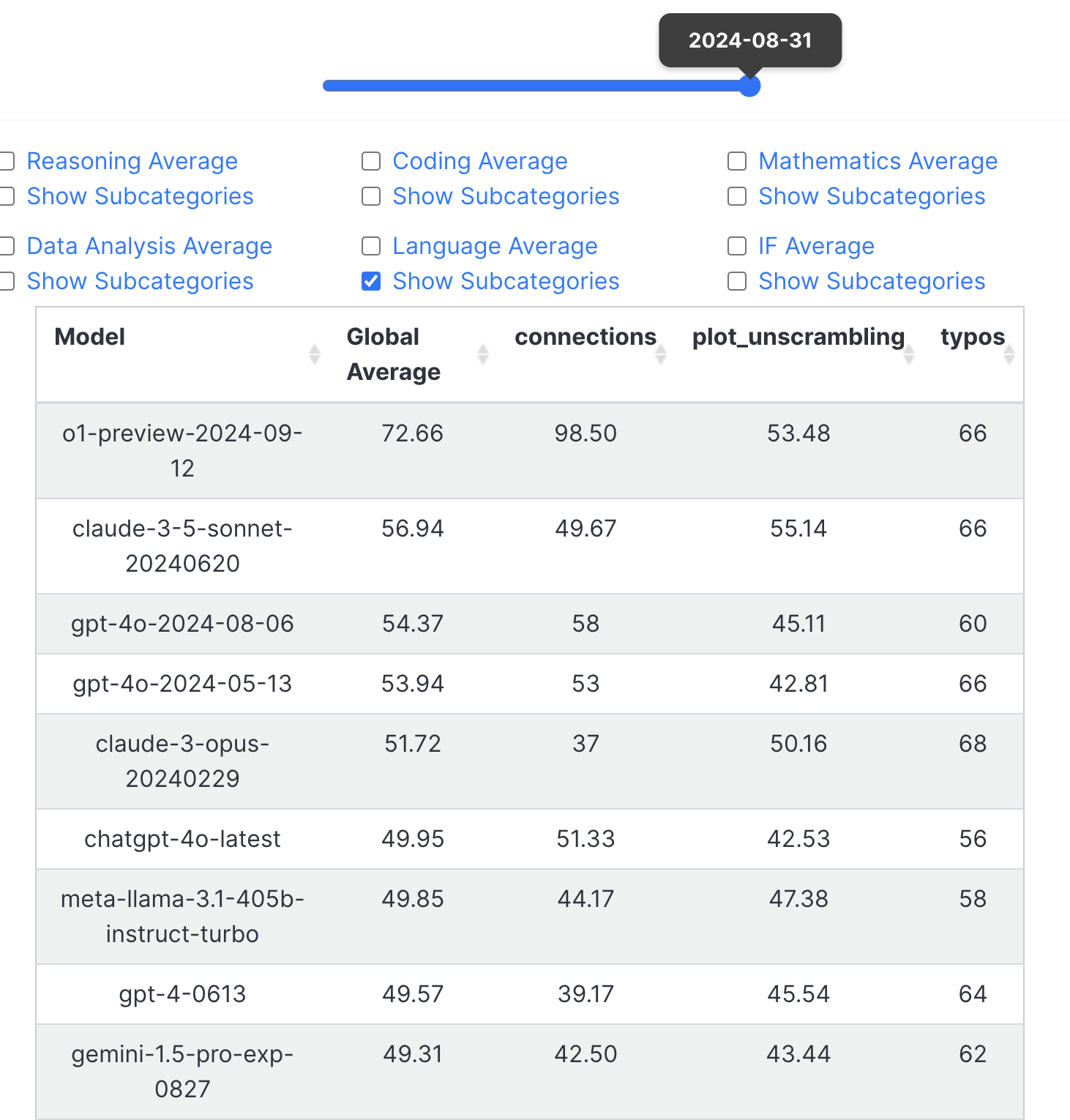
@Bayesian You think it trained on the LiveBench ones? Maybe people could test the last few connections game to see
@EliLifland Looks like they're from April-May https://huggingface.co/datasets/livebench/language/viewer/default/test?q=connections
@Bayesian I tried it on today's game which it couldn't have been trained on and it got it using the simplest prompt possible (second message https://chatgpt.com/share/66e47309-63ec-8007-85af-324a7a9b3310 )
@EliLifland I am bullish on the market overall but this particular model would have a hard time passing the test as written, since randomly selecting one of the puzzles from April-May would count as (unintentionally) backdooring in solutions.
The new o1 models would count here, right?
https://openai.com/index/learning-to-reason-with-llms/
@Bayesian Cool. In my test it oneshots 4/5 from the archive given an example solution, so if it get's 3 attempts, some more context and a bit of prompt massaging, I think it will easily do this.