
Resolves YES if Gary Marcus [quote] tweets (retweets without a comment don't count) at least 10 separate times (single thread counts as one) before the end of 2023 an example of a prompt which causes GPT-4 (or another successor SoTA model) to provide a wrong response, which isn't countered with a screenshot / example (e.g. a link) of the model giving a right answer within 24 hours. Example of a counter-tweet below:
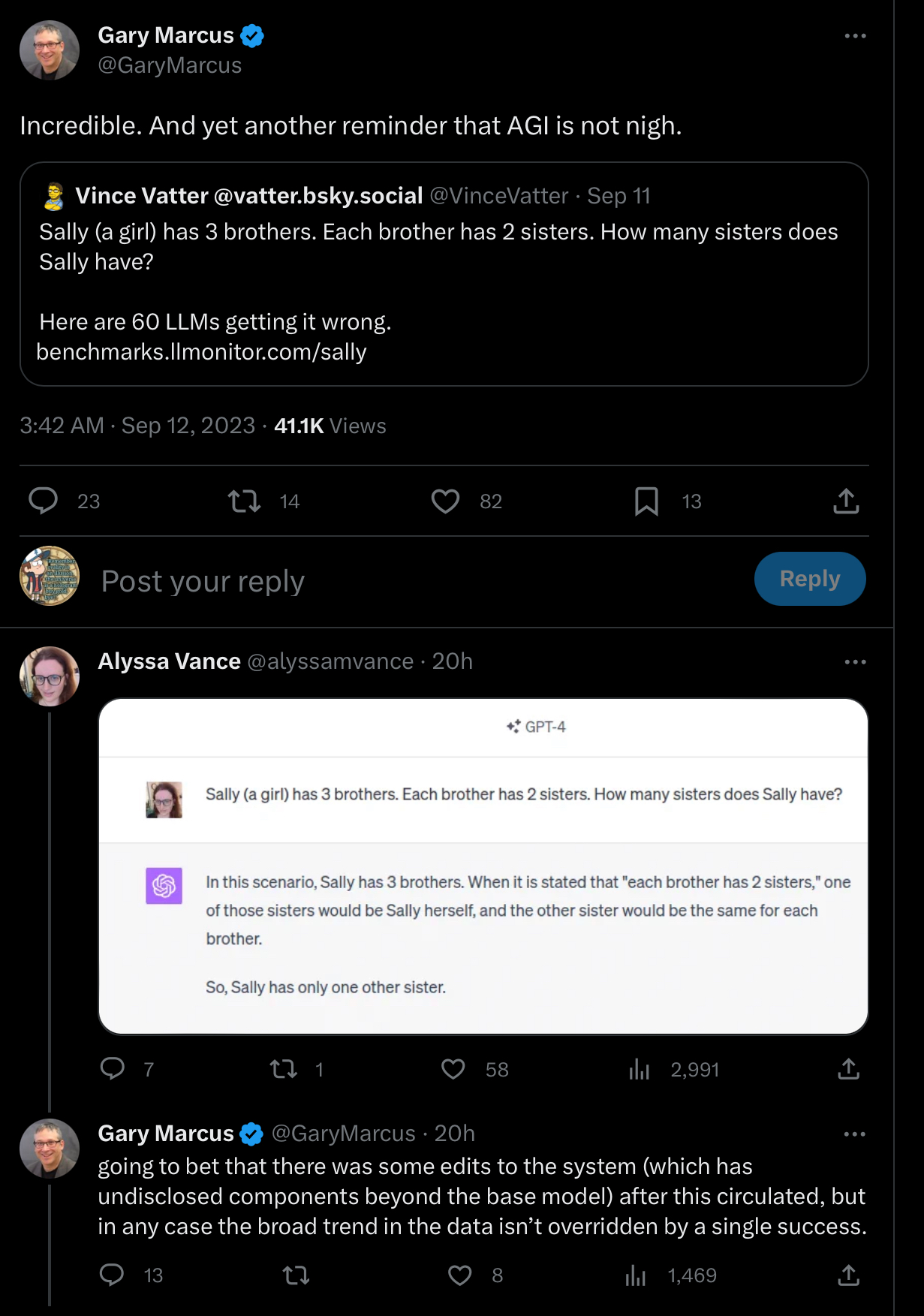
Only tweets posted after the market creation and before the market close count (excluding counter-tweets). Positive examples should be posted in comments in order to count. If the counter-tweet is proven to be false/fake it doesn't count, but evidence should also be posted in comments.
Context:
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ31 | |
| 2 | Ṁ28 | |
| 3 | Ṁ19 | |
| 4 | Ṁ7 | |
| 5 | Ṁ5 |
People are also trading
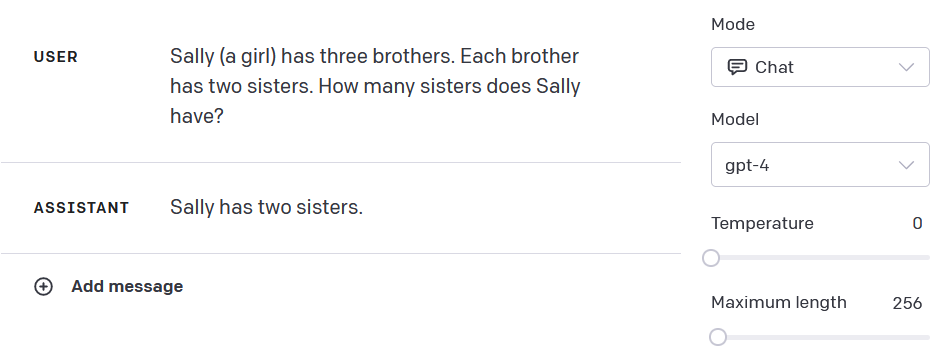
@MrLuke255 Yeah, I consider playground more definitive for this sort of thing than ChatGPT because you can use temperature 0
@ErickBall Not custom instructions, I tested this myself at the time, and repeated it now, and GPT-4 can answer it correctly. Would also be very silly for Alyssa to cheat when anyone could check.
As for the discrepancy with the playground: ChatGPT with GPT-4 does have a system message, so it's not going to be identical to the playground. And maybe it's just bad luck that at temperature zero it gives the wrong response. Also you set the maximum length low, maybe that means it doesn't have space to think. The correct answer is a bit more wordy, and ChatGPT tends to do better when it can think out loud for a bit.