
Ben Pace and Nathan Helm-Burger recently made a bet about whether AI systems will have begun to meaningfully improve themselves by August 23rd, 2026.
Nathan: "I believe we are already in a substantial hardware and data overhang, and that within the next 24 months the threshold of capability of LLM agents will suffice to begin recursive self-improvement. This means it is likely that a leader in AI at that time will come into possession of strongly super-human AI (if they choose to engage their LLM agents in RSI)"
Ben: "I don't expect that a cutting edge model will start to train other models of a greater capability level than itself, or make direct edits to its own weights that have large effects (e.g. 20%+ improvements on a broad swath of tasks) on its performance, and the best model in the world will not be one whose training was primarily led by another model. "
This market resolves YES if Nathan wins the bet, and NO if Ben wins. The resolution date is one year later than the cutoff so that information about whether meaningful self-improvement started prior to August 2026 can be taken into account.
 1,000
1,000People are also trading
the quotes in the description make it seem like this wouldn’t suffice for a YES, i think.
@Bayesian my guess based on statements from labs or those who work in them themselves is that this is maybe about where we indeed are, but that this wouldn't wualify for YES yet. Thoughts?
This should be quite clear
https://x.com/SakanaAILabs/status/1928272612431646943?t=Cfgef4BW2uVcdct3mKCifw&s=19
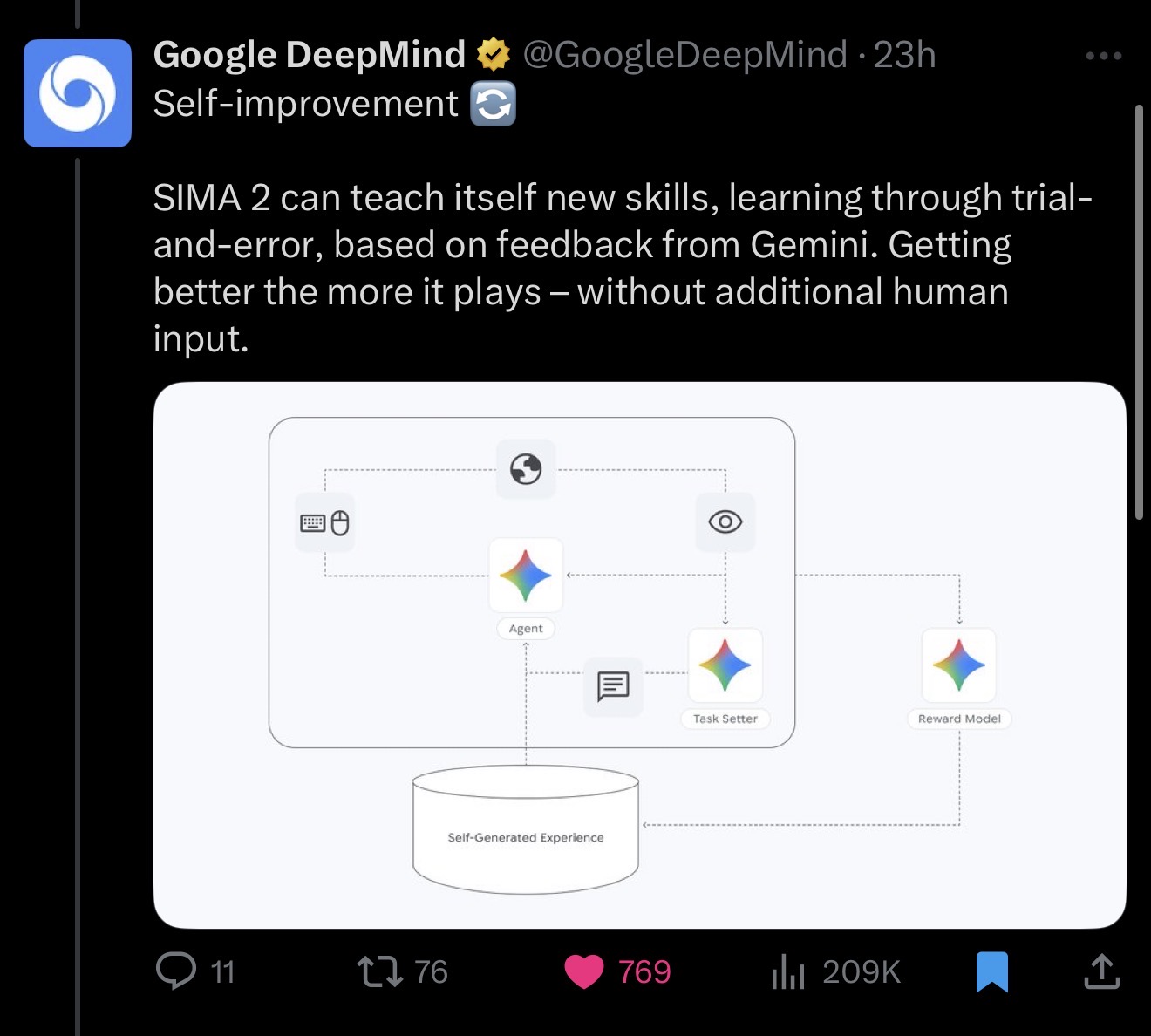
@NathanHelmBurger Here's my understanding of this question. Correct me if I'm wrong, and elaborate where possible please!
Per quotes: "leader in AI at that time will come into possession of strongly super-human AI" and "whose training was primarily led by another model.":
Resolution will weigh all of: capabilities of the resulting model; amount of human labor automated; degree to which human labor was improved on; ?second derivative of progress/resulting acceleration to algorithmic progress. From the quotes' wording, seems we should read the bet as conjunctive i.e. NHB claims all will be satisfied?
Trying to relate this to my mainline scenario for mid 2026 where (1) AIs are doing most of the work to improve some particular components (say 50% of them) e.g. attention CUDA implementation, or data loading pipeline, but not doing the 3-6 month planning/OAI manager roles (2) resulting in a model which is above trend, but roughly equal to the algorithmic progress as the GPT-4 to O3 jump. (3) The resulting model is at ~80% on frontier math, saturated on 2025 SWE metrics etc.
Then under assumptions 1-3, the bar still has not been met, you need something more significant? If so, do you need to strongly improve on all of 1-3 or will strong improvement in just one of these disjunctively suffice?
@JacobPfau Great question. I do think that this market question is more about the technical work than the management oversight. I certainly think that if all 3 of these were true that it would be close. Within the 'grey zone' that would resolve NO. For this to resolve 'YES', we'd need to see probably stronger contribution from the AI on (1), and I would expect that if such strong contribution did occur, your (2) and (3) would be exceeded as a result (thus, 'for free' in a prediction sense).
I could see (2) and (3) not happening even after a surprisingly strong (1), if some dramatic event in the world interfered. Maybe the AI was clearly helpful enough that the company could've probably have produced the strongest model ever by a significant margin, but before this could occur a natural disaster destroyed their datacenters and set them back substantially. So then this would resolve 'NO' even though signs of a strong (1) seemed to indicate that (2) and (3) were highly likely.
Please feel free to ask further clarifying questions.
@NathanHelmBurger "This means it is likely that a leader in AI at that time will come into possession of strongly super-human AI (if they choose to engage their LLM agents in RSI)"
Are you able to cash this out in terms of time horizons? E.g. is there a certain time, t, such that a YES resolution requires that mid-2026 AI will be capable of owning AI R&D technical tasks of length t with 50% success? From the discussion, I'd infer a t~1 week?
An interesting point of view: https://www.lesswrong.com/posts/jb4bBdeEEeypNkqzj/orienting-to-3-year-agi-timelines
(cross-posted from https://www.lesswrong.com/posts/wr2SxQuRvcXeDBbNZ/bogdan-ionut-cirstea-s-shortform?commentId=groxciBxma5cgay7L)
Figures 3 and 4 from MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering seem like some amount of evidence for this view:
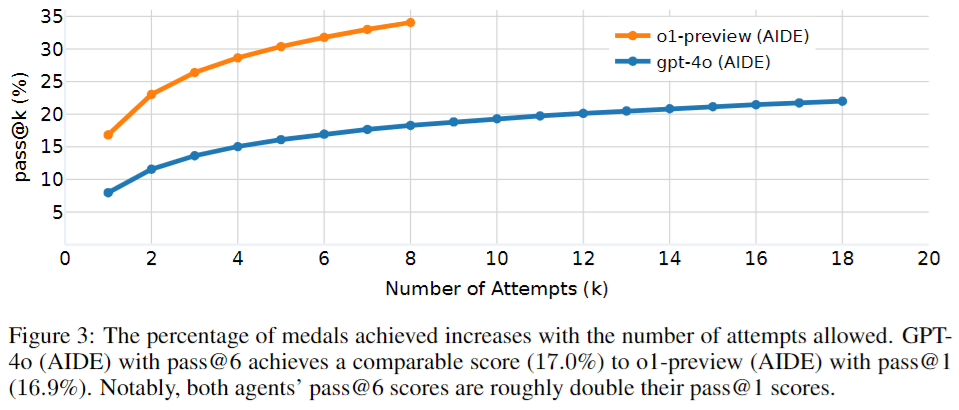
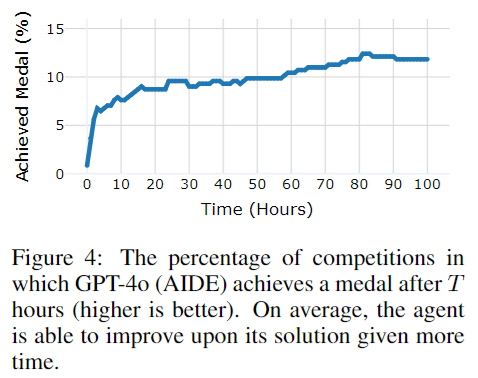

If this article happens to be true does it resolve YES ? https://www.theinformation.com/articles/openai-shows-strawberry-ai-to-the-feds-and-uses-it-to-develop-orion
This is using a Sota model with something to advance reasoning to improve, by providing the training data, a frontier model. Probably strawberry is MCTS and RL on top of a base LLM
To me this is "self improvement" in that it's an automated process, its bootstrapping by using one cutting edge AI model to improve another. It is also recursive in that gpt-5 can be augmented with RL and MCTS to produce the training data for gpt-6.
Others might disagree in that it's not one monolithic AI - its several components, and it's not 100 percent automated. It would probably take 100s of thousands of people to do this work manually, and instead is requiring less than 1000 people, but that's not full automation. People are ordering each run, checking results, fixing bugs, trying again, for thousands of iterations over months. AI is likely even helping with this but the most talented engineers in the world are driving the effort.
So, just to be clear, this market resolves based on the determination of the judge(s) picked by Ben and Nathan, and so my opinion as market creator isn't that relevant.
That said, I think this is not sufficient by itself. As discussed earlier, my opinion is that generating training data isn't usually what's meant by RSI, at least on the vibes level. What's more centrally meant is algorithmic (or direct) improvement, such that version n is designing version n+1. That said, if on the deadline, models were vastly more powerful because of automated training data production, I'd probably suggest it should resolve YES anyway, because it's in line with the vision of the future Nathan presents.
Note : the algorithm described is where strawberry/q* is a self improving algorithm that can solve reasoning questions. It likely works similar to https://www.multion.ai/blog/introducing-agent-q-research-breakthrough-for-the-next-generation-of-ai-agents-with-planning-and-self-healing-capabilities
However the architecture was chosen entirely by humans. Gpt-5 is then memorizing/compressing the correct answers to very large numbers of outputs.
So yes it's not generating merely "training data", the smart but slow AI is strawberry, and then gpt-5s network is being used to compress the techniques learned by strawberry to something cheaper and faster to run. It is doing exactly what you are saying it isn't, Max.
If this works everyone will be doing it and yes we will see large advances over a short time period to probably human level or above across most questions that it is easily possible to check for correctness.
Possibly robotic problems are solvable with the same approach - bring in a simulator, use RL and MCTS to find a solution to each simulated task, then memorize the answer. If you go back and check the GATO paper is this.
It's a good discussion max and I have my doubts this is RSI myself. Humans are picking the architecture ("let's make the numbers defining it bigger"), doing countless debugging steps the current tools are too stupid to help with, building the data centers, etc etc.
Imagine we wrote some manifold bets on early aircraft in 1895 and we are now arguing if the Weight Brothers aircraft flies like a bird does.
@GeraldMonroe It is definitely in a murky grey zone, but my intuition is that just synthetic data generation doesn't quite count. I explicitly said in the bet that this market is determined by that murky grey-zone situations should resolve to NO. The scenario I have in mind for a YES resolution is something more like the AI being used as part of an 'AI scientist' system which pursues algorithmic improvements in a highly parallel search process involving formulating hypotheses and running experiments. See Bogdan's comment:
https://manifold.markets/MaxHarms/will-ai-be-recursively-self-improvi#qugx17dviw8
@NathanHelmBurger so even if humans are then cherry picking the best results of the experiments, then human engineers assisted by Cursor etc implement new AI models based on the new algorithms. Human engineers then keep the enormous GPU clusters running training the new models, fixing a steady stream of intermittent failures and maintaining the generators.
Finally after training human engineers then test the improved models, send access keys to NIST, the government has human experts inspect it, and finally after a human emails approval at several levels a human IT engineer launches a script, written with AI help, to give a subset of public human users access to the new model.
Closing the loop, a human makes a pull request on the AI scientist repo to have the AI system use the newly improved base model.
This is recursive self improvement by your current understanding and for the purposes of this bet?
Just checking. It's missing the "self" part of it. The "AI scientist" as a script around a base model isn't really a player in itself. It's not doing research because it wants to be smarter, its doing it because the Json file of next tasks to do instructs it to, and because we did a bunch of math to find a set of functions that will do what we (humans) want from the AI scientist.
@GeraldMonroe Thanks for the clarifying question. Yes, that counts in my view. If the clear majority of the intellectual work is being done by AI, the human input/guidance doesn't have to be zero or negligible to count. If the work being done is something like 75% AI, 25% human, then that seems to me like it would qualify. So this bet is about recursive-self-improvement that is still human-in-the-loop, not all the way to human-out-of-the-loop fully independent improvement.
Of course, I must reiterate that I'm not the judge, and I'm only one of the two parties to the bet. I'm just sharing my understanding and intuitions. Ultimately it won't be on me to make the call.
@NathanHelmBurger if X.ai employees are really a tiny crew and they all use cursor or similar tools would that count? Assuming it speeds up the easier part of "intellectual work" - turning ideas to code, turning results to a human interpretable form, reviewing work for mistakes.
I know culturally lesswrong believes the only intellectual work that matters is that tiny bit of human inspiration that is pivotal. For example when Edward Teller and Stanislav Ulman famous whiteboarded the radiation lens concept.
But what about all the other engineers who would have worked for months to design every detail of the actual device? Does their work count as intellectual? What saves you more money, automating the bulk of the work or the brilliance of the top of the pyramid staff?
@GeraldMonroe I feel like non-peak intellectual work, supportive stuff, does count but at some discounted rate? Like, more clear and impressive peak insights coming from the AI would need to be a smaller fraction of the credit in order for this to count? Either way, it's gotta be clearly obviously in main part because of the AI. Part of how this would be clear is if X.ai were using the AI in some manner to accelerate more than 2x beyond what a similar sized team could have been expected to achieve, and their model was clearly the best... And if other companies racing for powerful AI were leaning less heavily on AI help and fell behind despite superior resources as a result? But probably some of the knowledge for the judge to decide if all this was the case would be private, so that would leave room for speculation/uncertainty. Anticipating this is why a resolution delay might help (private info might come out later), and why the bet specified that an unclear 'grey area' resolution would resolve to 'NO'.
I'm expecting we'll see super clear indications if my mainline worldview predictions come true, like the SotA 2026 AIs being clearly better than 99.999% of humanity at programming, and able to agentically do substantial programming tasks independently with high reliability.
Currently (beginning of 2025), the AIs aren't quite skilled enough (at the relevant skill levels of the ML engineers at the major labs), aren't quite agentic enough for long-ish horizon tasks (e.g. multiple hours), and aren't reliable enough (time wasted debugging their code subtracts from time gained by using their help). Currently I feel like Claude Sonnet 3.6 has been giving me about a 1.5x speedup (mainly because the debugging time cuts so heavily into the value gained). I thus suspect that the benefit for top ML engineers at large companies is less than 1.5x. By early 2026, it sure seems like we're on track for the coding assistant AIs to be enough better to be >2x speedup even for top engineers.
@NathanHelmBurger You could probably get a lot more coding performance by designing your software project from the start to take advantage of tooling like this, with the right frameworks so the models can efficiently use your tools, multiple models are used in a committee to reduce error rates, etc.
I will also note that there are 2 competing forces here for the RSI task. Each generation of AI, the next generation will require more compute and more model complexity to gain another increment of performance. So even if the MLEs are using generation n-1 as a helper when developing generation n, the quantity of work required increases. This would preclude foom even though there is heavy use of RSI.
@GeraldMonroe I agree that that is a mostly accurate description of how things have gone so far. The majority of my probability is still on models getting capable enough that they cross a threshold where they are able to handle sufficient complexity to make a substantially more powerful next generation. I still think that the first few such generations will take years or months, not weeks or days, so it wouldn't be a fast FOOM sort of situation (probably).
As for taking more compute... I don't think that assumption holds at all. I think that if algorithm development gets substantially sped up, then training and inference compute requirements will actually start dropping.