Background: SWE-bench is a benchmark designed to evaluate the ability of language models to solve real-world software issues from GitHub. The benchmark consists of 2,294 Issue-Pull Request pairs from 12 popular Python repositories. The models are tasked with generating patches that resolve these issues, verified by unit tests to assess the correctness of the solutions. This benchmark is pivotal in assessing the capability of language models in practical software engineering tasks.
Question: Will the next major release of an OpenAI LLM achieve over 50% resolution rate on the SWE-bench benchmark?
Resolution Criteria: For this question, the "next major release of an OpenAI LLM" is defined as the next model from OpenAI that satisfies at least one of the following criteria:
It is consistently called "GPT-4.5" or "GPT-5" by OpenAI staff members
It is estimated to have been trained using more than 10^26 FLOP according to a credible source.
It is considered to be the successor to GPT-4 according to more than 70% of my Twitter followers, as revealed by a Twitter poll (if one is taken).
This question will resolve to "YES" if this LLM demonstrates a resolution rate of more than 50.0% on the SWE-bench benchmark under standard testing conditions. The results must be verified by a credible public release or publication from OpenAI detailing the model's performance on this benchmark. This will resolve according to the first published results detailing the LLM's performance on the benchmark, regardless of any future improvements due to additional post-training enhancements.
 1,000
1,000People are also trading
@MatthewBarnett Resolves as YES. GPT-5 is clearly considered to be the major successor to GPT-4 (GPT-4.5 was not), while achieving more than 50% resolution rate on the SWE-bench benchmark (https://openai.com/index/introducing-gpt-5-for-developers/):
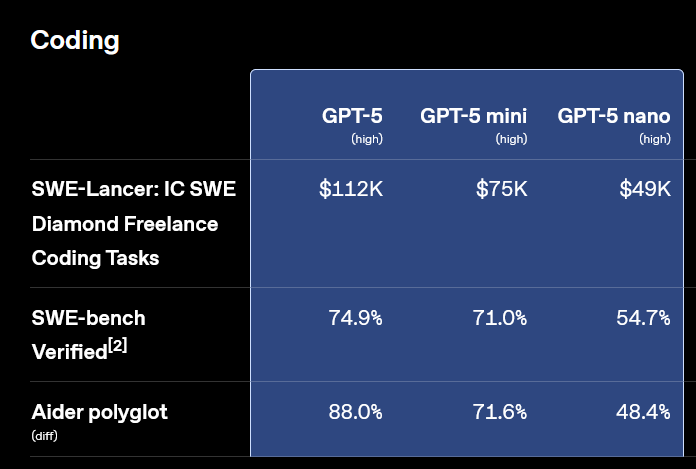
"Resolution Criteria: For this question, the "next major release of an OpenAI LLM" is defined as the next model from OpenAI that satisfies at least one of the following criteria:
It is consistently called "GPT-4.5" or "GPT-5" by OpenAI staff members"
Looks like required resolution criterion was full-filled.
https://openai.com/index/introducing-gpt-4-5/
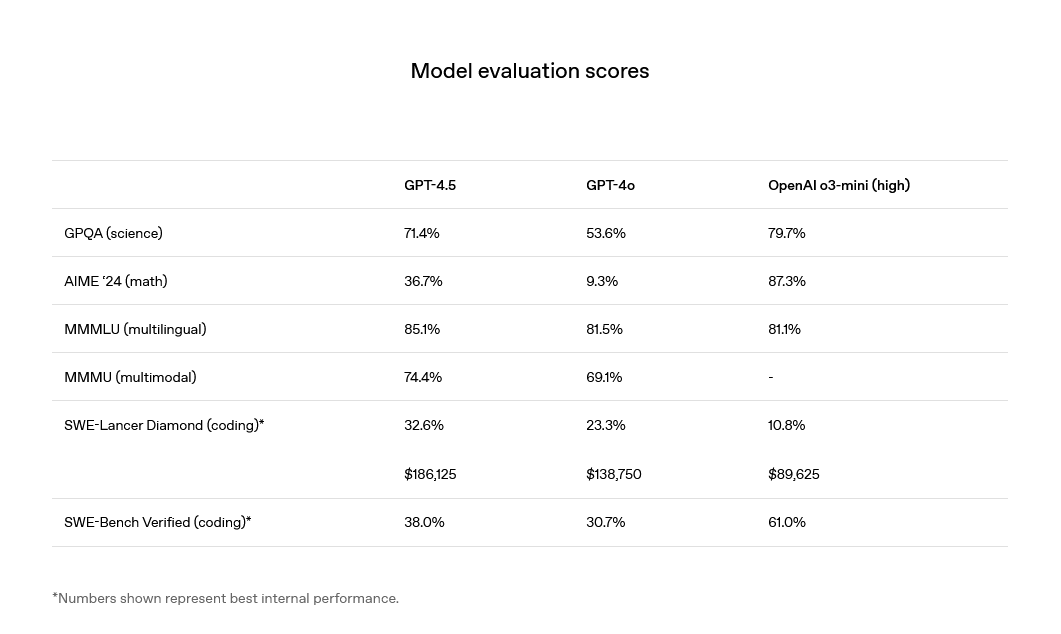
@Metastable @MatthewBarnett Can we get a clarification on that? I think it was not framed as the next major LLM by OpenAI themselves but it would fit the name criterion. The only questions would be if o1 or another model meets the FLOP or poll criteria.
nice eval. do you have a link that you'd use to resolve this for gpt4? couldn't find one. i went off this https://www.swebench.com/