
Released = available to some portion of the public (including a subset of subscribers or a limited number of API developers from members of the public). Released only for safety testing does not count.
New model = Either announced by the company as a new model, is clear from numbering/naming it is a distinct model, or able to be selected from some sort of menu as a distinct model. Something like "o1 extra mini" would count as while it is part of o1 it can be considered a distinct model in this market.
Must be publically released for the first time between February 1st 00:00am PST and February 28th 11:59pm PST. If it is announced but not yet released to any members of the public it will not count.
For answers where no specific model type is specified alongside the company, then any type of generative AI model will cause it to resolve yes.
*OpenAI (other) refers to any model that is not their new flagship model (eg. GPT 5), o3, a video generator, or an image generator. It could be a derivative of another language model or some other type of model such as a voice generator.
**Anthropic flagship language model refers to a model comparable to claude 3.5 or gpt-4o that should outperform claude 3.5 sonnet on a majority of performance benchmarks. This should not be a reasoning model.
***Anthropic reasoning model refers to a model that is not considered their everyday task model and is akin to what OpenAI's O1 is to gpt-4o.
****Anthropic (any other) refers to any model that is not a reasoning model nor their new flagship model. For example, it could be a derivative of an existing language model or a different type of AI model entirely.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ31,115 | |
| 2 | Ṁ27,106 | |
| 3 | Ṁ15,507 | |
| 4 | Ṁ10,496 | |
| 5 | Ṁ10,326 |
People are also trading
@JanPydych
Unfortunately, we are in a position where the norms of AI companies are rapidly changing so I'm going to try and be as fair to the spirit of the question as possible.
Here are my tentative thoughts:
If there is a toggle then that would be sufficient for both the flagship and reasoning model to resolve to yes. At the time this market was created the norm was for AI companies to label such toggles as distinct models a user can choose from.
If the LLM dynamically decides whether it should reason and there is no toggle then this is where I would consider things to become a bit more unclear. As Bayesian said it probably would be fairest to resolve both to YES.
@Bayesian @strutheo here is my March 2025 version of this q:
https://manifold.markets/typeofemale/which-of-the-following-companies-wi-n2Uh2OQuPt
this market gives genuine edge over polymarket
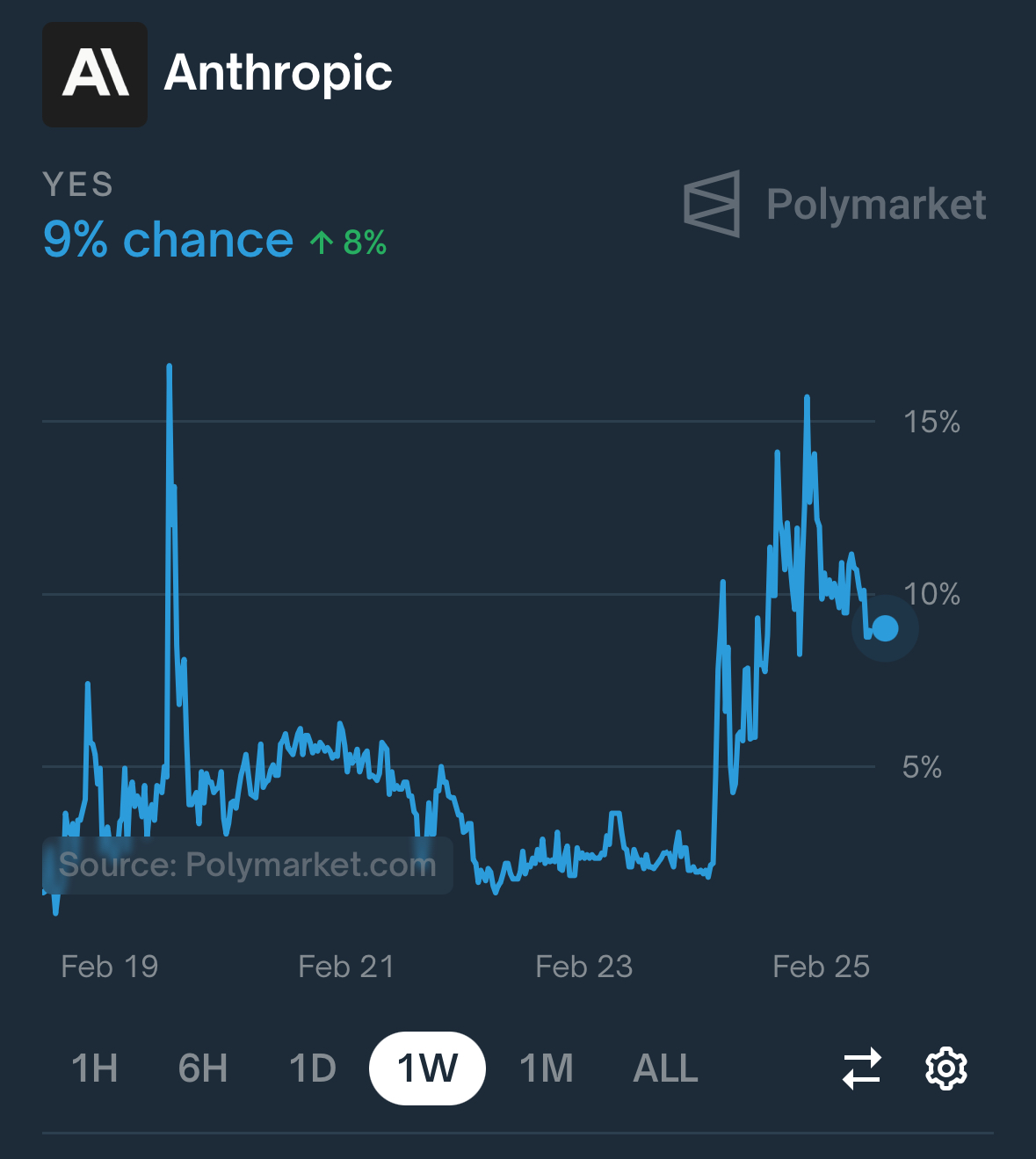
their “will anthropic lead on lmsys on march 1st” market. had them at 2% a week ago
then a model is released. a reasoning model in february as this market had at 90%. and the polymarket lmsys market shoots up to about 12% (with a lot of volatility). from odds of 1:49 to odds of 3:22 after the release, or a bayes factor of 6.7x
maybe sonnet 3.7 is a little more cracked at coding than people expected but not “factor of 6.7” better. the release just wasn’t priced in. manifold dub
i disagree a bit, i think the market knew some model was probably coming out, if it was a reasoning model stacked on 3.5 it would not have topped lmsys bc small reasoning models do terribly there. Coding only matters a bit, same for math, a lot of the points on the lmarena are kinda random stuff, includes creative writing which small reasoning models do bad in, etc. Im personally pretty sure claude 3.7 isn’t gonna get #1 but the fact that u can set it to no reasoning (was at 50% on manifold before release) and the fact that it’s fairly improved from 3.6 is the update imo
Resolved both reasoning and flagship to YES.
I realise that the description failed to capture the evolving way companies are releasing new models and apologise that we weren't able to better anticipate this scenario. We will not be differentiating between reasoning and non-reasoning models in future versions of this market.
Market description:
**Anthropic flagship language model refers to a model comparable to claude 3.5 or gpt-4o that should outperform claude 3.5 sonnet on a majority of performance benchmarks. This should not be a reasoning model.
Anthropic description of Claude 3.7 Sonnet:
Today, we’re announcing Claude 3.7 Sonnet[1], our most intelligent model to date and the first hybrid reasoning model on the market.
It seems like a stretch to say that the spirit of a question that explicitly requires, "This should not be a reasoning model," is fulfilled by a model that is trained to reason and sometimes reasons just because it sometimes doesn't reason. Humans often don't reason either; are we not reasoning models?
@Jacy agreed, I traded based on the market description earlier today given what the AWS description stated about Claude 3.7. The toggle part being only clarified in comments is frustrating for sure. It's not clear to me that the toggle does anything more than what R1 does, which is start a new text completion with special tokens. Anthropic seems to be suggesting that Claude-3.7 is genuinely a reasoning model, which means this really should resolve No
@Soaffine I think @SirSalty's comment was reasonable, particularly in that he qualified it with: "Here are my tentative thoughts," rather than phrasing it as a permanent judgment. It would have been hard to make a durable judgment given the wide range of what a "toggle" can be.
Also note that the toggle, as labeled by Claude, is for "extended thinking," not "reasoning."
Yeah it's unfortunate, I think the distinction that the market was trying to draw, but used not quite the rights words for, was:
Flagship: whether there is a new model that can achieve better results with similarly low latency to the previous models
Reasoning: whether there is a new model that achieves better results by thinking longer (reasoning isn't the best description for this)
~
Today, we’re announcing Claude 3.7 Sonnet[1], our most intelligent model to date and the first hybrid reasoning model on the market.
You probably don't see reasoning traces because you're on the free plan. Claude 3.7 Sonnet is capable of "reasoning."