The breakthrough needs to make LLMs better at learning from context at test time. Some examples of results that could demonstrate this breakthrough would be a model that shows less degradation than contemporaries on long-context or one that can more effectively learn from mistakes during agentic tasks.
The breakthrough needs to be major and conceptual, it can't be something as simple as models getting better at in-context learning through more scaling.
In order to count this breakthrough must apply to general LLMs, not just using continual learning to solve a narrow problem or class of problems
A paper claiming to have a really good result isn't enough (like the Titans paper). The breakthrough must be widely accepted as legitimate and there should be publicly accessible models that use it
Update 2025-09-07 (PST) (AI summary of creator comment): - LLM definition: Will be interpreted broadly; any AI system that models language qualifies, including non-transformer architectures.
 1,000
1,000People are also trading
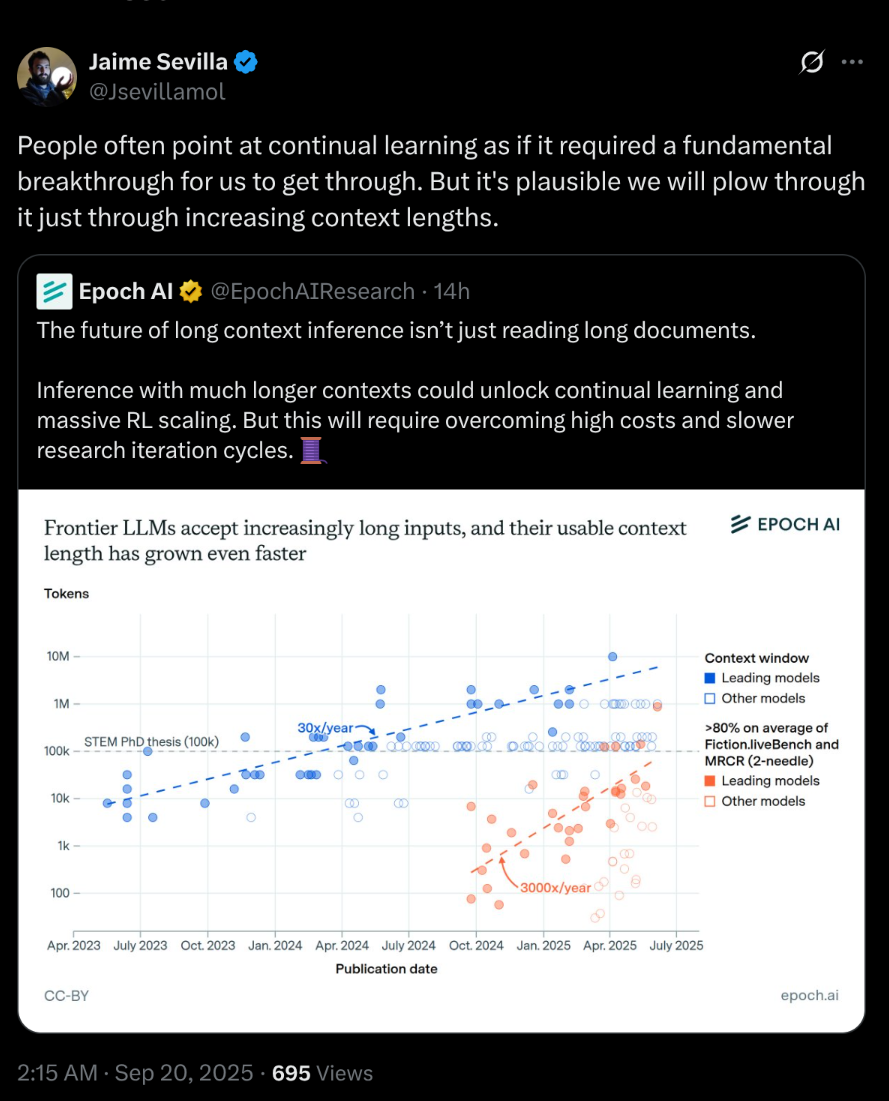
@Dulaman "plowing through it by increasing context lengths" is an example of something that would not count