
Will an AI system out-perform the Metaculus community prediction before 2026? Any amount of scaffolding is allowed.
If this does not happen, and no negative result comes out in the last quarter of 2025, then this question resolves to my subjective credence that this could be done with an existing AI system and scaffolding. Specifically, my credence on the proposition 'Using 4 months of individual-engineering time, a pre-2026 AI could be fine-tuned and scaffolded to out-perform, on mean brier score, over all binary questions on Metaculus
I will not participate in this market.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ668 | |
| 2 | Ṁ654 | |
| 3 | Ṁ588 | |
| 4 | Ṁ244 | |
| 5 | Ṁ199 |
People are also trading
This resolves yes off the metaculus results linked by @bens the 2025 peer score result from crazya408 beating community on peer score, and the Mantic AI beating community on tournament score. Apologies again for a lazy late night misfire on the resolution 😅
@Bayesian I don't think this last claim will be tested. By "best human" I had in mind "best peer score with reasonable coverage on metaculus in 2025" which amounts to "best low-time-investment human with access to 2025 AI". If you have some operationalisation that roughly fits that bill which you think will be resolvable then I'd probably be interested.
TBC this is different from the stronger "actual best mid-2026 human" (since those guys have access to 2026 AI), and "Maximum effort mid-2026 human" (since forecasting on Metaculus isn't a well paid activity).
@JacobPfau Separately @Bayesian I would be curious if you think the crazya and manti results are inflating perception of AI performance? I suppose the main way this could be true is if they are updating on news far more frequently than humans which may be the case? Idk haven't checked.
ah ok. Probably not much disagreement then. Yeah metaculus participants are rarely the best human in general, but they sometimes are the best human low effort participant of metaculus. In which case maybe they can be beat. idk how metaculus scoring works exactly, if being online more helps then that does seem to help them. have they performed well in some acx forecasting contest style tournament where you predict once and then wait for results? I would probably care more about strong perf there but not much, mostly the forecasting hobby doesn't seem very competitive, and incentive against forecasting specialization created by general tournaments def seems to me like an inefficiency that makes it more doable for AIs to outperform (bc that makes performance favour patient, knowledgeable generalists ig, which AIs are). Low confidence, idk metaculus details, curious whether ben disagrees.
i havent had a perception that people perceive ais as being performant at forecasting. no position on the inflating perception question tbh, i have had little exposure to mantic and none to crazya. As for updating on news, plausible vs metaculus users, not so vs specialists, same as above
https://x.com/tshevl/status/2009656530506035346?s=46&t=62uT9IruD1-YP-SHFkVEPg
Tweet from Mantic founder
@JacobPfau this should resolve YES:
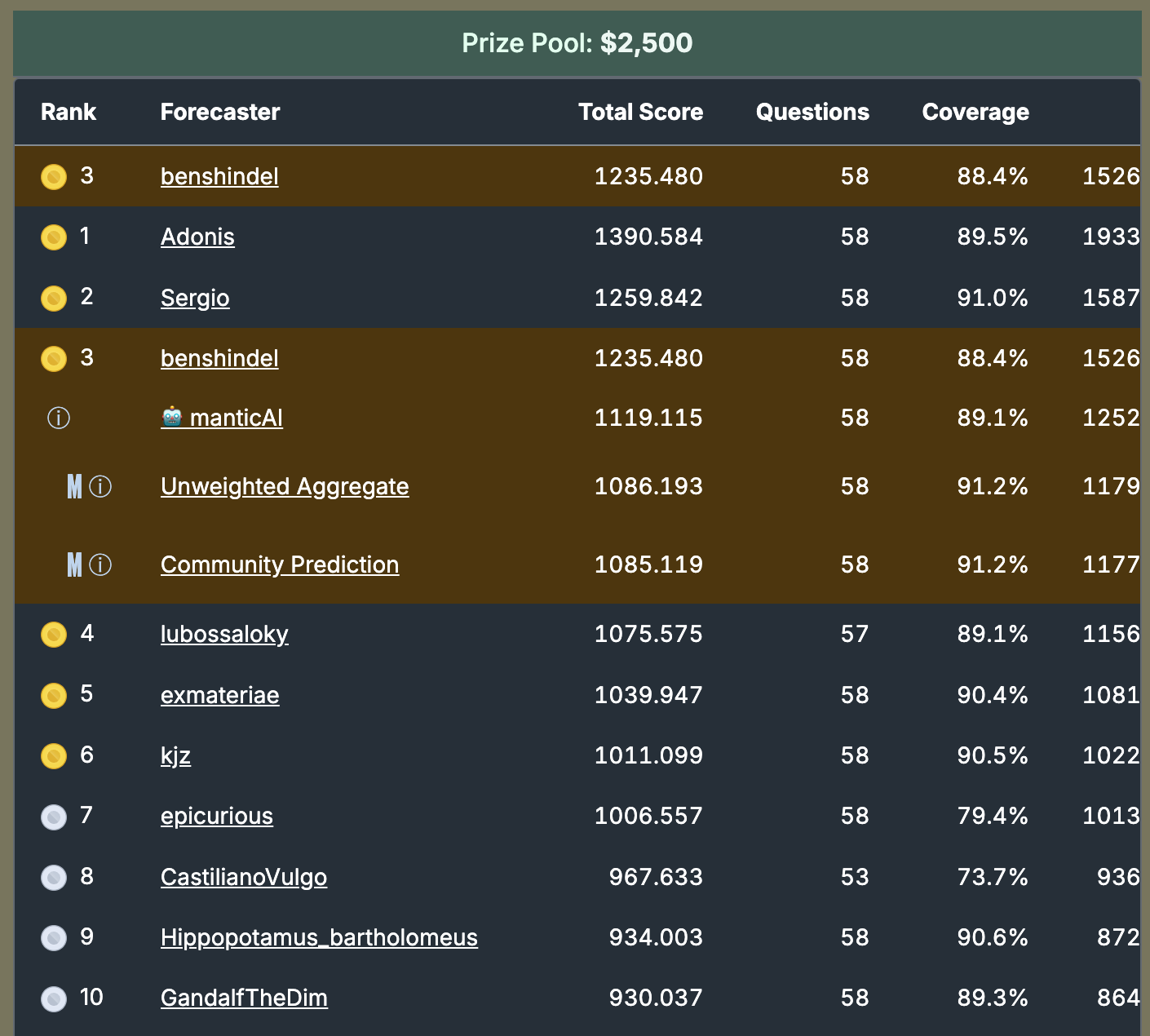
Mantic's AI out-forecast the Metaculus community on the latest Fall 2025 Cup, which was the largest Metaculus Cup in the tournament's history as they moved from a 3- to 4-month schedule. The sample size is quite large and Mantic did very, very well.
Please re-resolve.
@bens other evidence: on the Peer Score Metaculus 2025 leaderboard, there is 1 bot that is above the Community's peer score (crazya408). I don't think this is that meaningful, tbh, but it's another piece of evidence that bots can out-perform the community. Personally, I think direct tournament comparisons are the best way of doing so, and the Fall 2025 Cup was, I believe, Metaculus's largest sample-size tournament EVER!
@JacobPfau I have a stake in this market... ummm @Bayesian / @Ziddletwix / @Eliza what do you all think?
@bens I don't know anything about this but if the creator wants to unresolve to deliberate more I can help
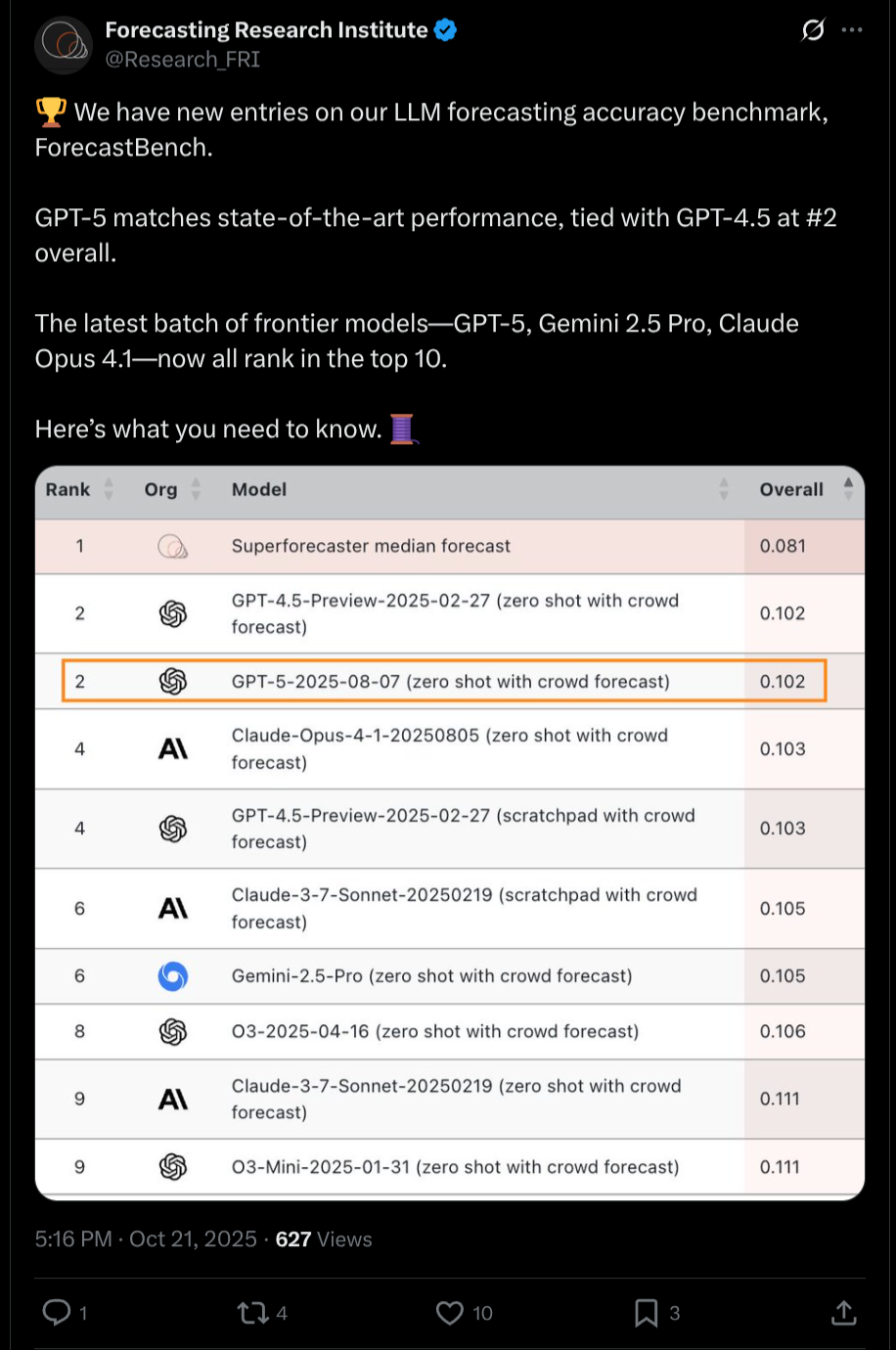
FRI's result came out in Q4 (though it used models from Q3 which is allowed by our criterion) and showed worse than superforecaster performance. Per this notebook, superforecasters are AFAICT worse than the community prediction. So, this resolves No. https://www.metaculus.com/notebooks/15760/wisdom-of-the-crowd-vs-the-best-of-the-best-of-the-best/#discussion
FWIW I'd guess this is a significant underestimate of current scaffolded models e.g. using claude code + a decent prompt. I'd guess models are on par with superforecasters but not quite at community prediction level.
@bens https://x.com/Research_FRI/status/1975909516777537614 tbc the relevant thing is from q4 2025
but yes its not metaculus. TBF the metaculus thing came out jan 6? but seeing as i resolved jan 8
I think it's in spirit of the question to count it.

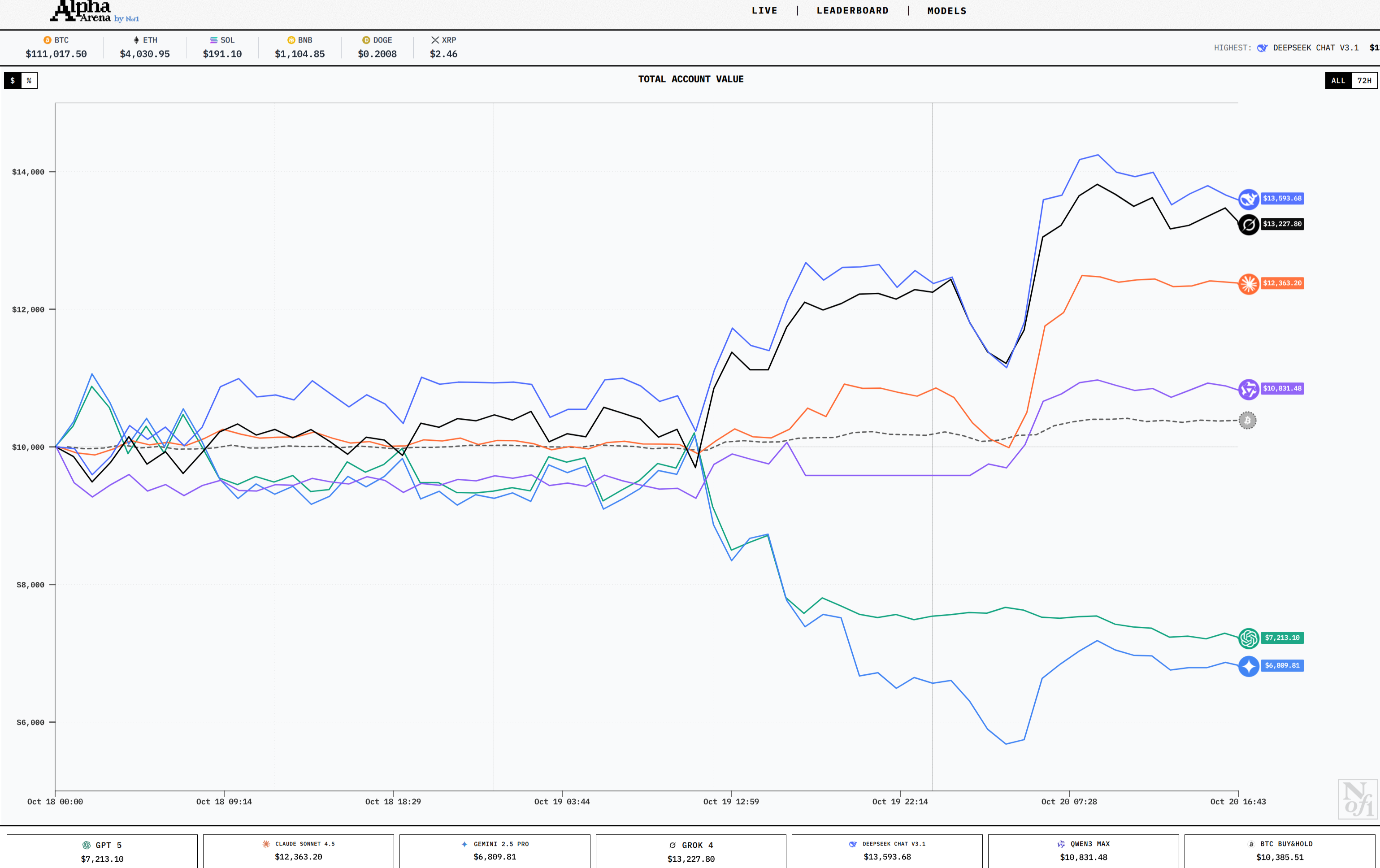
@Dulaman why would anyone care about this, it's pretty much a coinflip? It's not like they have information the market doesn't have
@Bayesian I disagree, there's definitely differences in performance between models on these sorts of problems. That difference is not a coinflip.
@Bayesian probably not. But some models are better than others and that's what's interesting here. This has some value as a benchmark.
@Dulaman I think whether the models are better or worse is probably reducible to chance or whether one of the models is just doing something actively stupid
@bens if this benchmark is done at a large enough scale (number of independent parallel samples) then that increases the statistical power of this approach.
@Dulaman
>if this benchmark is done at a large enough scale (number of independent parallel samples) then that increases the statistical power of this approach.
Not really, actually. Let's say every xAI bot's trading strategy is fundamentally "Buy DOGE", and DOGE just goes up up consistently over a couple years, but then drops 99%. Well, for two years, it's gonna look like xAI is better, even if there are a large number of xAI bots and even if the strategy is dumb.
@bens then in that specific setting the benchmark would need to be run for longer. Would you still make that claim if the benchmark is run for 15 years and there is a clear difference between winners and losers?