
The LM must have 'frontier' performance (having PILE/or similar perplexity above one year prior's SotA). The LM must have been trained after 2022.
If it's unclear whether this has happened, I will give this a year to resolve. If it remains plausibly unclear the market will resolve N/A.
Fine-tuning includes all RL training. Training on synthetic data, or additional supervised learning (which is deliberately trained on after training on a PILE-like generic dataset) counts as fine-tuning. If the nature of pre-training changes such that all SotA models do RL/instruction training/etc. during the initial imitation learning phase, I will probably resolve this question as ambiguous. Multi-modal training of text+image will by default count as pre-training.
Update 2026-01-09 (PST) (AI summary of creator comment): The market has been reopened until end of year because it's unclear whether the resolution criteria have been met. If it remains unclear by then, the market will resolve N/A as stated in the original description.
 1,000
1,000People are also trading
I'm not clear on whether this happened though I haven't done a thorough search. I'm going to reopen til EOY as per the question's clause "If it's unclear whether this has happened, I will give this a year to resolve. If it remains plausibly unclear the market will resolve N/A."
Will resolve earlier if someone shows me the relevant FLOP numbers from a 2025 run
@JacobPfau maybe the strongest candidate is grok 4? the published figure is suggestive that post>pretraining, but this is pretty weak evidence.

Well done @JacobPfau on this market! I thought pretraining was going to remain FLOPs dominant for some time, because I thought there was still lots of world knowledge still to obtain through new modalities for pretraining (especially video). I was wrong, and RL compute has scaled a lot quicker, judging from the recent Grok release.
Quick back-of-the-envelope got me that LLAMA 3.1 used ~100B tokens of post-training compute.
https://scontent-lga3-2.xx.fbcdn.net/v/t39.2365-6/452387774_1036916434819166_4173978747091533306_n.pdf?_nc_cat=104&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=t6egZJ8QdI4Q7kNvgGLd_WP&_nc_ht=scontent-lga3-2.xx&oh=00_AYAi3mcauEKuekcEn4CRpsF-igaR2I_3eBGde533LIM8eQ&oe=66A6EB8D#page=14.39
For reference, current estimates of most expensive training run pre-2026 is at 10x GPT-4 price. https://www.metaculus.com/questions/17418/most-expensive-ai-training-run-by-year/
Meanwhile information on the data supply of text is available here https://epochai.org/trends#data-trends-section
Added some detail to clarify "Fine-tuning includes all RL training. Training on synthetic data, or additional supervised learning which is deliberately trained on separately from a PILE-like generic dataset counts as fine-tuning. If the nature of pre-training changes such that all SotA models do RL/instruction training/etc. during the initial imitation learning phase, I will probably resolve this question as ambiguous."
This does not really make sense to me given the purpose of pre-training in bulk knowledge learning, and fine-tuning in setting certain behaviours. In fact very little SFT data is required to get desired behaviour; certain papers such as LIMA have shown this.
Yann LeCun has a famous cake analogy that describes this.
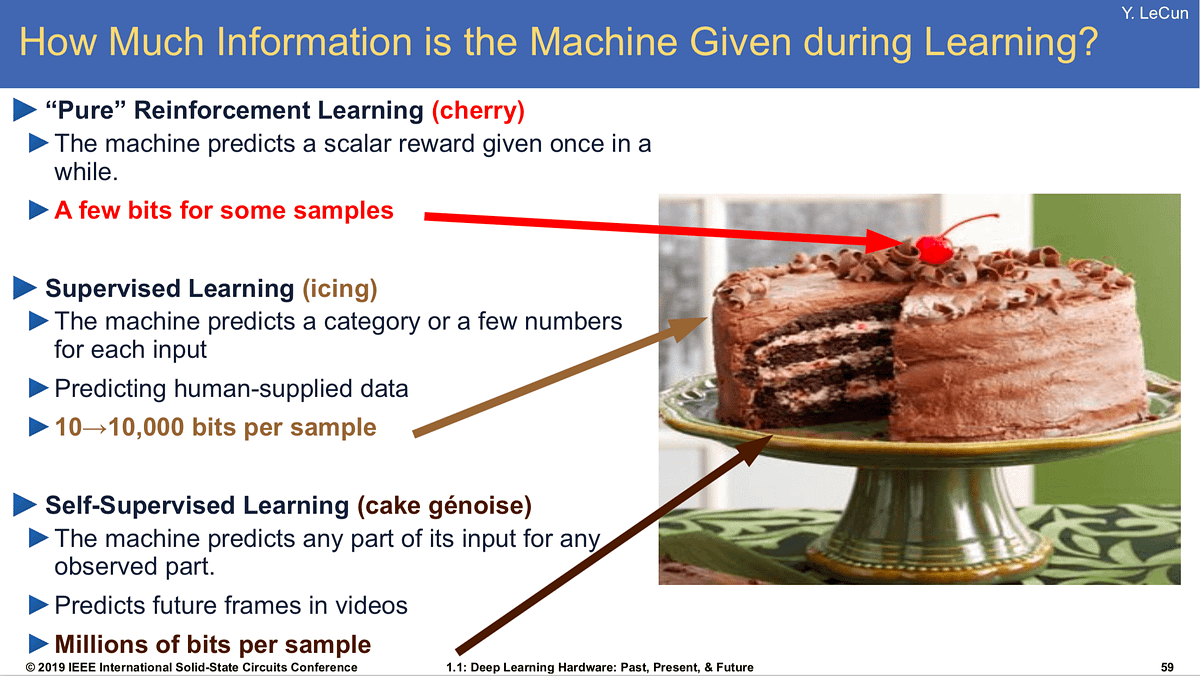
-