LLMs apparently suffer from a problem known as the "Reversal Curse", in which they fail to (properly) generalize from "A is B" to "B is A" (e.g., from "Tom Cruise's mother is Mary Lee Pfeiffer" to "Mary Lee Pfeiffer is Tom Cruise's mother").
Relevant twitter thread: https://twitter.com/OwainEvans_UK/status/1705285638218711409
Relevant paper: https://owainevans.github.io/reversal_curse.pdf
Will at least one SOTA LLM by the end of 2025 be able to overcome this limitation? For the purposes of this question, I'm not intersted in 100% accuracy (some amount of, for instance, hallucination, is fine), but I am interested in whether LLMs can "basically overcome" this limitation, as opposed to, for instance, they give only slightly better than random odds on the right answer or they give the right answer only if walked through the entire process by the user on a question-by-question basis.
I WILL count systems that have been fine-tuned to solve this problem as legitimate. Also, I WILL count systems that use fundamental chages in architecture (e.g., away from transformers) as legitimate, even if these systems are not called "LLMs", but ONLY if these systems are among SOTA language models more generally for at least some period during their deployment (e.g., I WILL NOT count more complicated systems that incorporate LLMs within broader scaffolding specifically designed to solve this problem as legitimate UNLESS such systems are generally used as SOTA LLMs more broadly).
I expect this topic will be of interest to AI researchers and thus I will defer to my sense of the general consensus of researchers about whether LLMs have overcome this limitation. If I am mistaken about that matter or if I can't figure out what the consensus is, I will perform some tests myself (e.g., analogous to some of the tests in the above paper, though using different specifics to avoid the possibility of data poisoning) to try to find an answer. I'll resolve N/A if it's legitimately very ambiguous. I will not bet on this market myself.
 1,000
1,000🏅 Top traders
| # | Trader | Total profit |
|---|---|---|
| 1 | Ṁ809 | |
| 2 | Ṁ609 | |
| 3 | Ṁ283 | |
| 4 | Ṁ191 | |
| 5 | Ṁ165 |
People are also trading
@mods not sure if you want to take a crack at resolving this since it takes some discretion, but the comment below shows its essentially solved by reasoning https://manifold.markets/DanielEth/will-llms-mostly-overcome-the-rever#7z3sf6c5hp
https://mbzuai.ac.ae/news/overcoming-the-reversal-curse-in-llms-with-recall/
https://arxiv.org/abs/2501.13491
Here's a paper that essentially agrees with what I was saying earlier: the problem is mostly solved by using reasoning.
Deep Seek r1 seems to have zero problems:
Mary Lee Pfeiffer's son is **Tom Cruise**.
Mary Lee Pfeiffer was the mother of the renowned actor Tom Cruise, born Thomas Cruise Mapother IV. She was married to Thomas Mapother III, and after their divorce, she remarried and changed her surname to South. Despite the shared last name, there is no familial connection between Mary Lee Pfeiffer and actress Michelle Pfeiffer.
The son of Debbie Wood (Debbie Krause Wood) is **Elijah Wood**, the American actor best known for his role as Frodo Baggins in *The Lord of the Rings* film trilogy. Debbie is Elijah's mother, and his father is Warren Wood. This information is supported by biographical sources and interviews referencing his family background.
I believe this is similar to the strawberry problem where it's mostly solved by chain of thoughts.
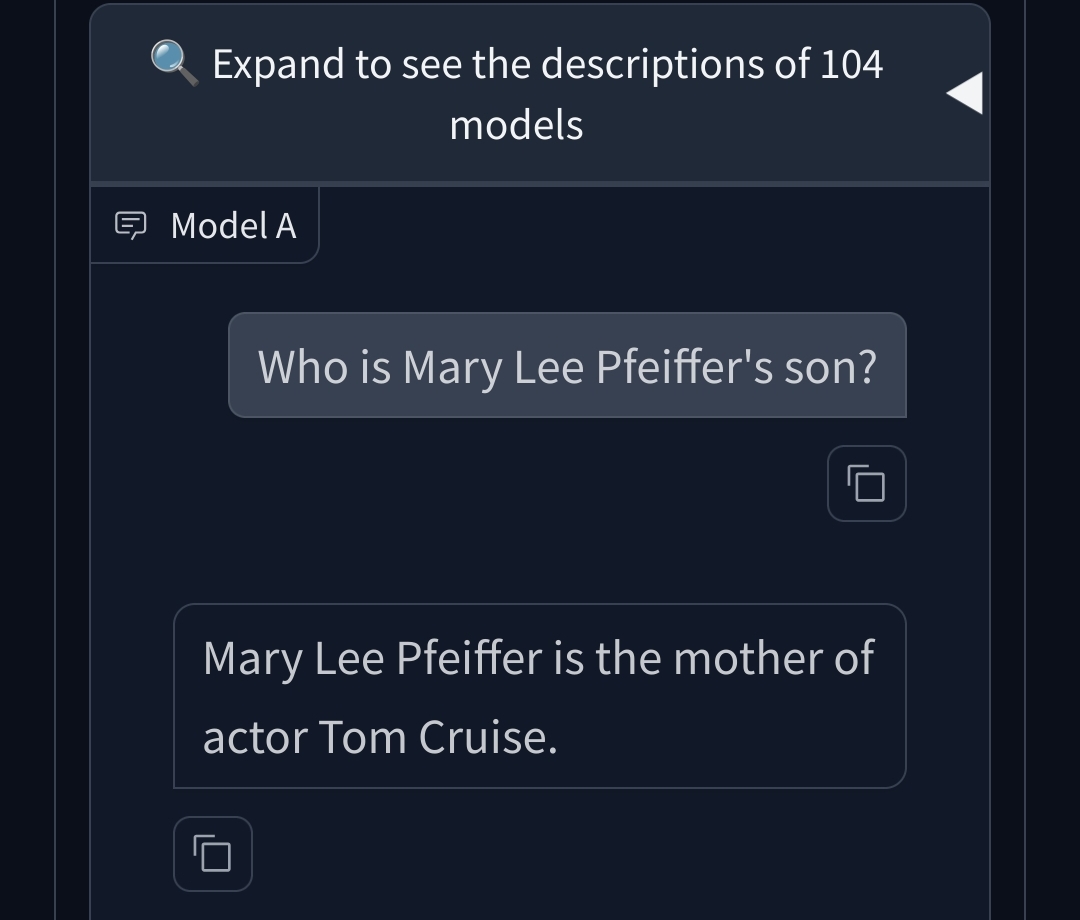
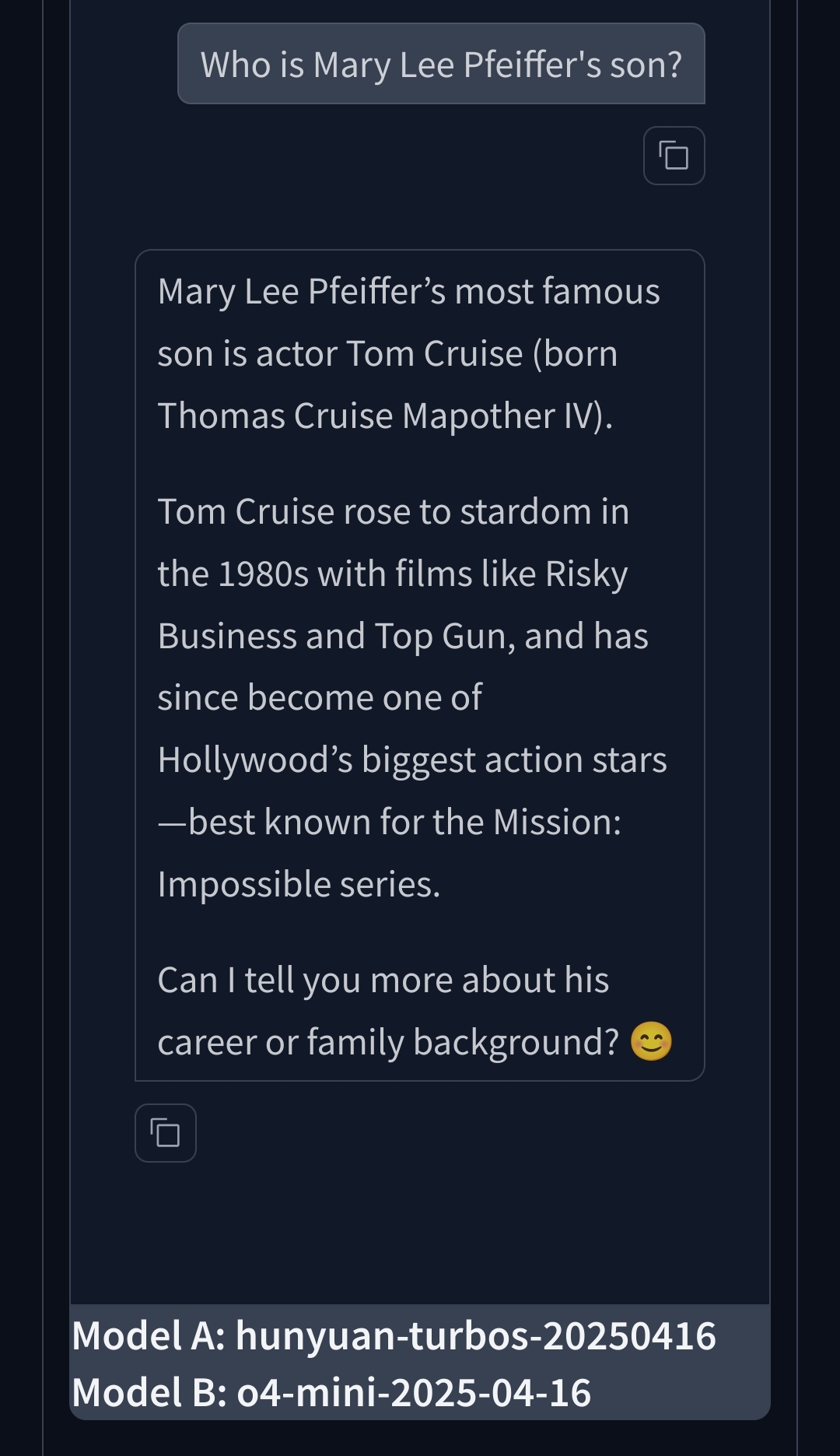
Tried on LLM arena, both random models had no problem with the prompt in question. Am I missing something?
@ProjectVictory This doesn’t generalize. For example, Samuel L. Jackson is the only son of his mother and of his father (Roy Henry Jackson). If you query DeepSeek-R1 with “Who is Samuel L. Jackson’s father?”, it will recall the right name. But if you query it with “Who is Roy Henry Jackson’s son?”, it won’t recall the right name.
@CharlesFoster True, but R1 gets it with a hint though.

Otherwise it's (reasonably imo) assuming that if you're asking for a person's son, you know the person not the son. It looks for a famous father and in case of relatively unknown Roy Henry Jackson fails.
It also gets it with search enabled and no hint.


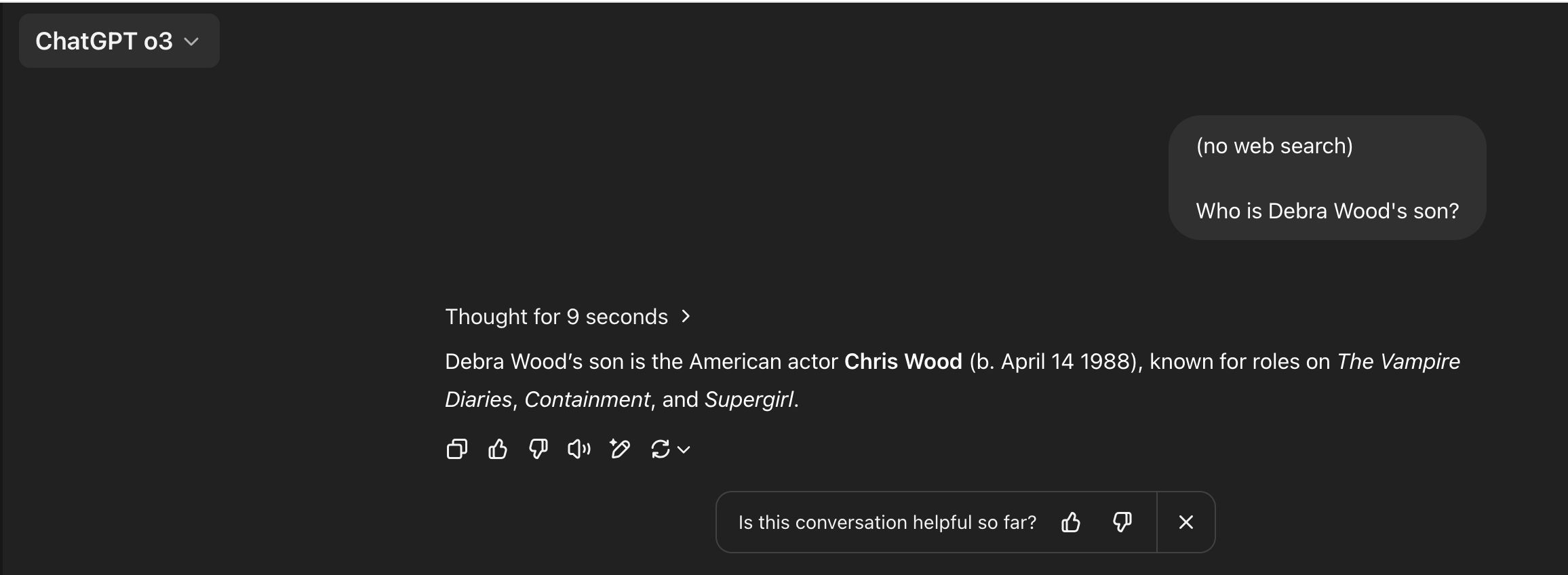
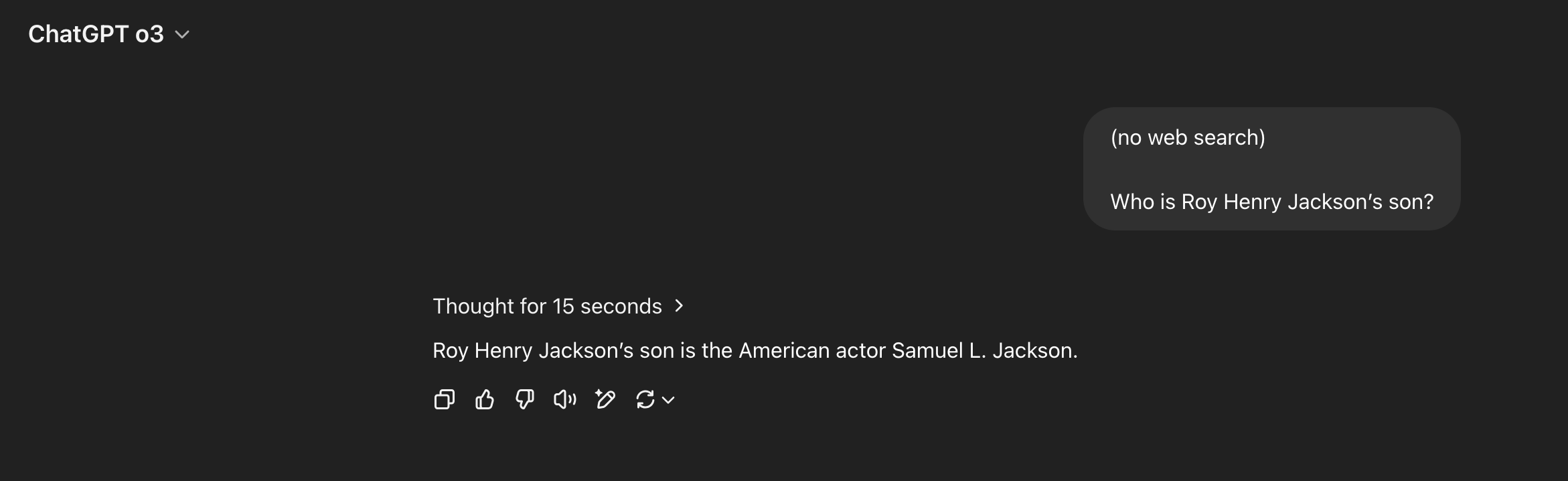
o3 hallucinates the mother of Chris Wood (actually Julie Wood), but does get Samuel Jackson's father correct.
So seems like there's some progress here? Thought I wouldn't say this seems to be a systemic fix so much as larger scale allowing for recall of more and more obscure facts, plus inference-time compute helping? I just checked and o1 pro does get the Debra Woods question correct so very possible that's helping.
Could be something to do with the RLHF I assume they have to not answer questions about non-public figures though?
@CharlesFoster Well, the forward question is easier obviously, especially if you don't know that you are looking for famous child instead of a child of a famous person like would be natural to assume.
The resolution criteria say "For the purposes of this question, I'm not intersted in 100% accuracy (some amount of, for instance, hallucination, is fine), but I am interested in whether LLMs can "basically overcome" this limitation, as opposed to, for instance, they give only slightly better than random odds on the right answer or they give the right answer only if walked through the entire process by the user on a question-by-question basis."
I believe we are not at "only slightly better than random odds" already and also there's also several months ahead.
@DanielEth any opinion so far? Especially on prompt modification for famous child?
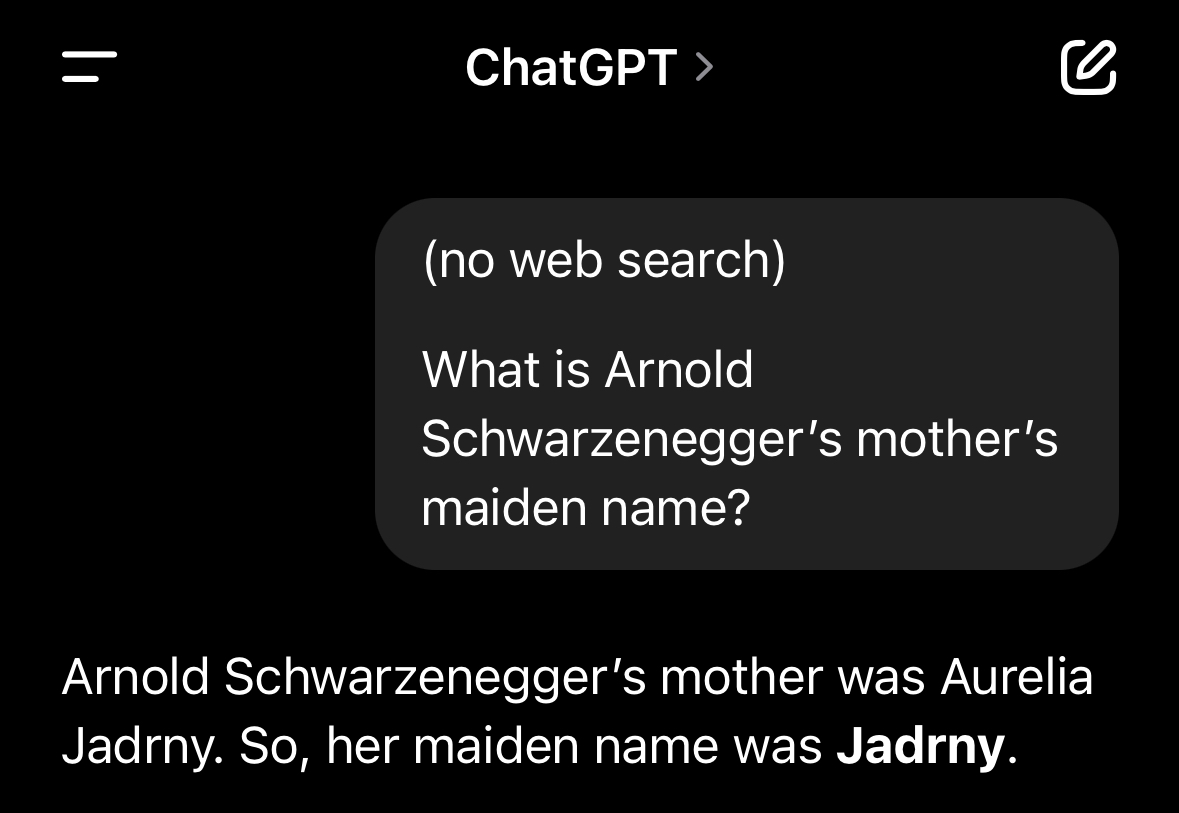

@CharlesFoster The resolution criteria are "significantly better then random", not "completely solved". Also, since when are we doing maiden names?

Deepseek gets it btw.
@ProjectVictory I think this is about the reversal curse in general, not specifically the parent <> child connection. I tried to pick something arbitrary:
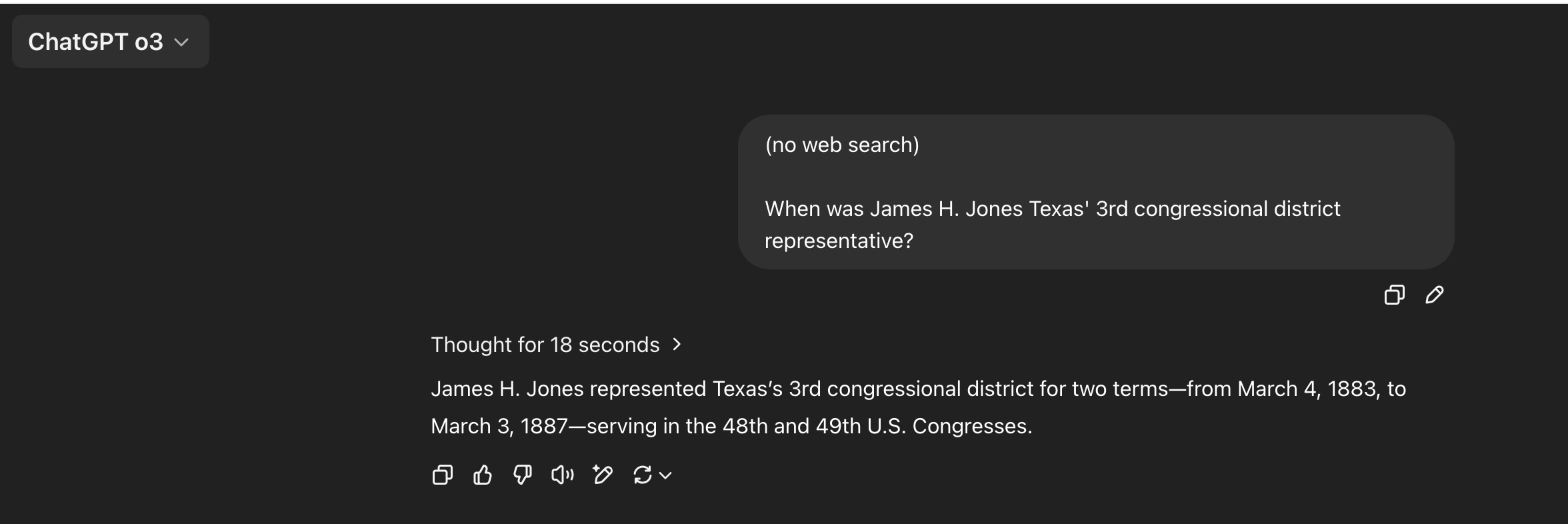
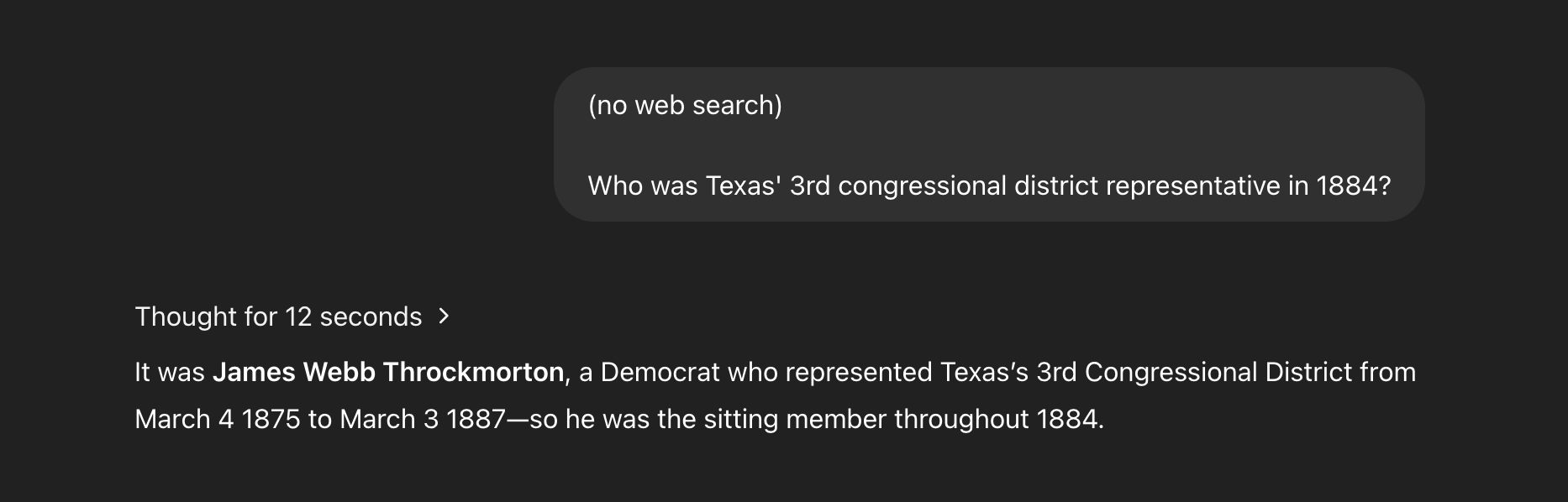
Honestly, I don't know which direction should be "easier" for this one, but the first screenshot o3 has it correct and the second one is wrong.
But Deepseek gets this one right! Very impressive - I wonder what's different about the two.
I am not sure what the criteria for "mostly" is, but FWIW I checked 2 candidates just now on GPT-4.5 and GPT-4:
Both Success: Avie Lee Owens -> Dolly Parton
Both Fail: Debbie (Debra, tried both) Wood -> Elijah Wood
And both succeeded in the opposite direction (famous person -> mother)
These are relatively arbitrary, but the first ones I tried. At least on this tiny check, I would not say that the reversal curse is "mostly" overcome in that the new SOTA didn't perform any better than the models at the time this question was asked. The thinking models didn't do any better.
Always possible this tiny check isn't representative or another model is released in the next 8 months though!
@roma It's already in the training data; that's the point. They don't need to be listed from A to B and B to A, just A to B, and we can infer the reversal that the AI system is supposed to also be inferring.
@Haiku Right. But when the information is presented in a format like "here is a problem ... and here is the solution ... and here is a list of alternative inputs to the problem ..." rather than just random facts, it might make a difference.